Présentation
Il est de notoriété publique dans les cercles de bases de données que les index améliorent les performances des requêtes soit en satisfaisant entièrement l'ensemble de résultats requis (couvrant les index), soit en agissant comme des recherches qui dirigent facilement le moteur de requête vers l'emplacement exact de l'ensemble de données requis. Cependant, comme le savent les administrateurs de base de données expérimentés, il ne faut pas être trop enthousiaste à l'idée de créer des index dans des environnements OLTP sans comprendre la nature de la charge de travail. En utilisant Query Store dans l'instance SQL Server 2019 (Query Store a été introduit dans SQL Server 2016), il est assez facile de montrer l'effet d'un index sur les insertions.
Insérer sans index
Nous commençons par restaurer la base de données WideWorldImporters Sample, puis nous créons une copie de Sales. Table des factures utilisant le script de la liste 1. Notez que l'exemple de base de données a déjà activé le magasin de requêtes en mode lecture-écriture.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Notez qu'il n'y a aucun index dans la table que nous venons de créer. Tout ce que nous avons est la structure de la table. Une fois cela fait, nous effectuons des insertions dans la nouvelle table en utilisant les données de son parent comme indiqué dans le Listing 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Au cours de cette opération, Query Store capture le plan d'exécution de la requête. La figure 1 montre brièvement ce qui se passe sous le capot. En lisant de gauche à droite, nous voyons que SQL Server exécute les insertions en utilisant Plan ID 563 – un Index Scan sur la Primary Key de la table source pour récupérer les données puis un Table Insert sur la table destination. (Lecture de gauche à droite). Notez que dans ce cas, la majeure partie du coût est sur l'encart de tableau - 99 % du coût de la requête.
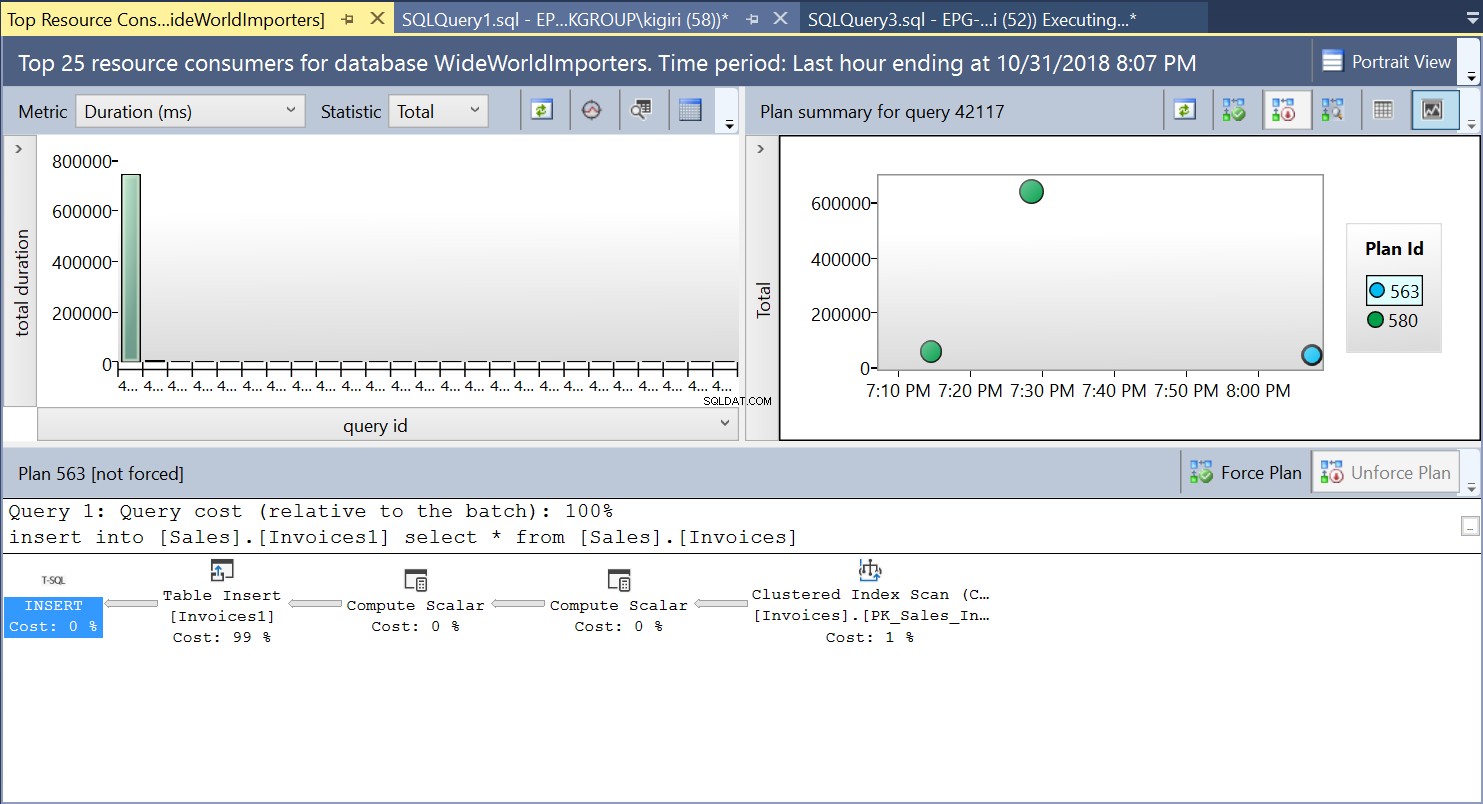
Fig. 1 Plan d'exécution 563
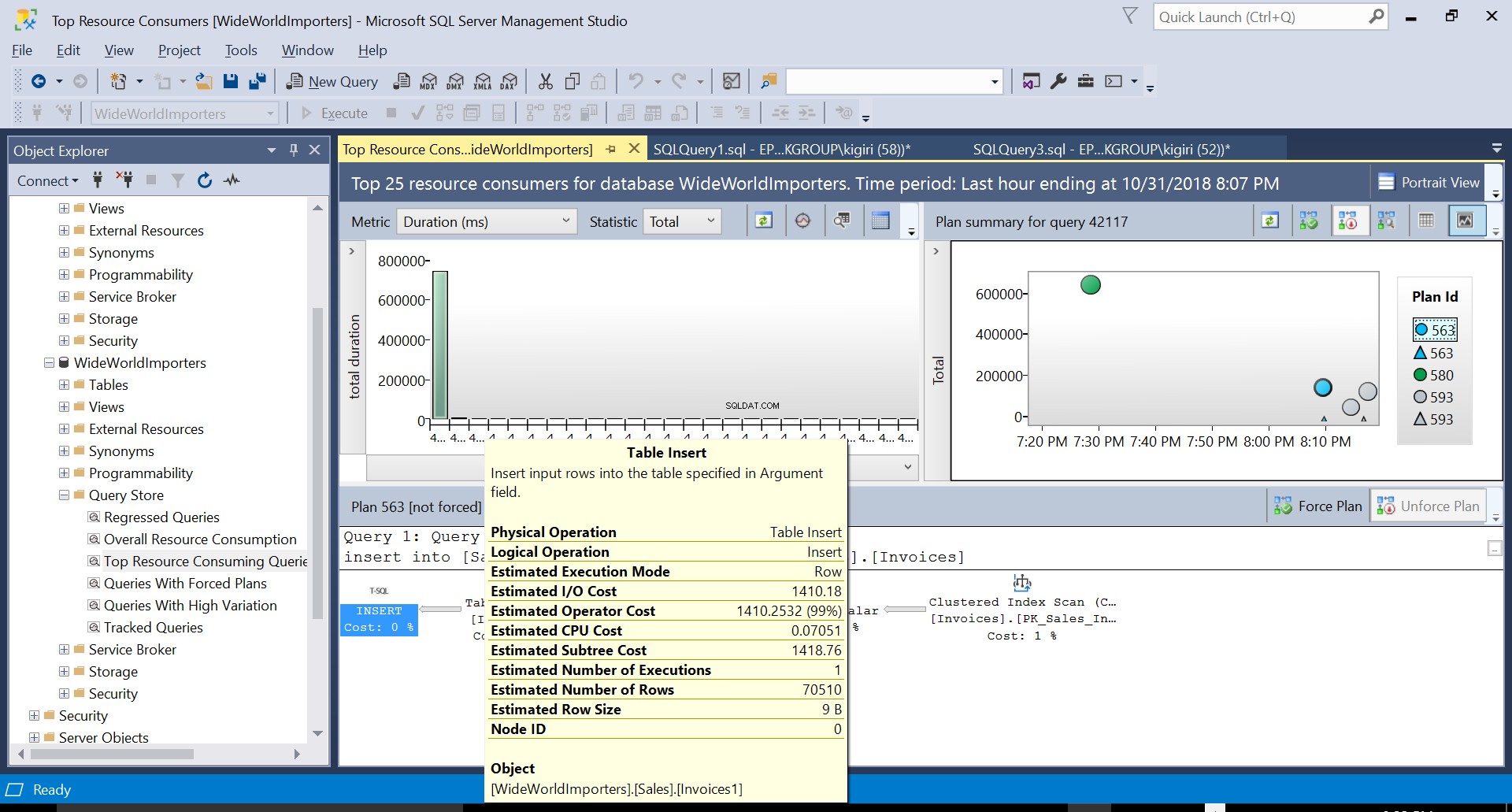
Fig. 2 Insertion de tableau sur la destination
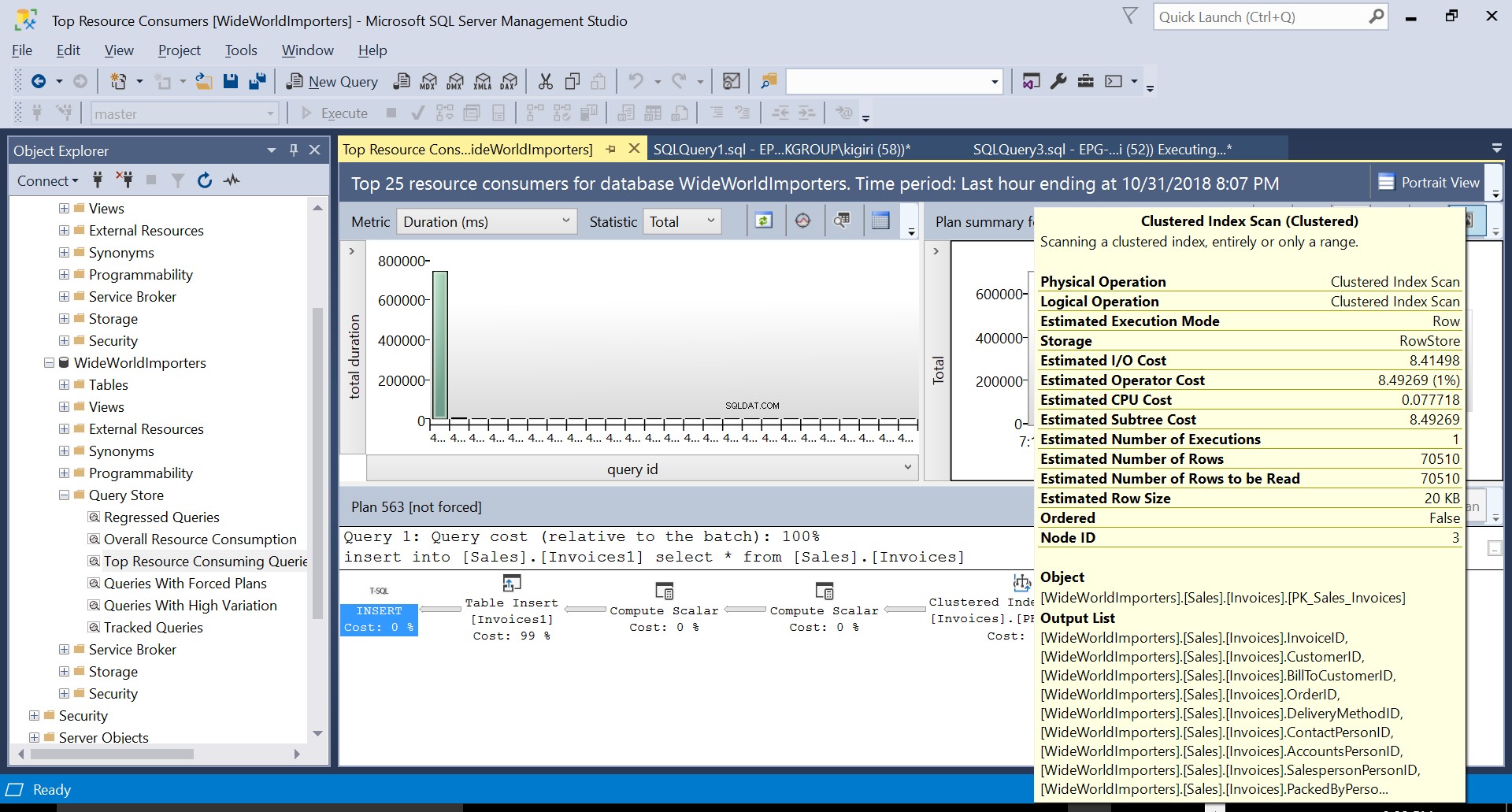
Fig. 3 Balayage d'index clusterisé sur la table source
Insérer avec index
Nous créons ensuite un index sur la table de destination à l'aide du DDL du Listing 3. Lorsque nous répétons l'instruction du Listing 2 après avoir tronqué la table de destination, nous voyons un plan d'exécution légèrement différent (Plan ID 593 illustré à la Fig 4). Nous voyons toujours l'insertion de tableau, mais elle ne contribue qu'à 58 % au prix de la requête. La dynamique d'exécution est un peu faussée avec l'introduction d'un tri et d'un Index Insert. Ce qui se passe essentiellement, c'est que SQL Server doit introduire les lignes correspondantes sur l'index lorsque de nouveaux enregistrements sont introduits dans la table.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
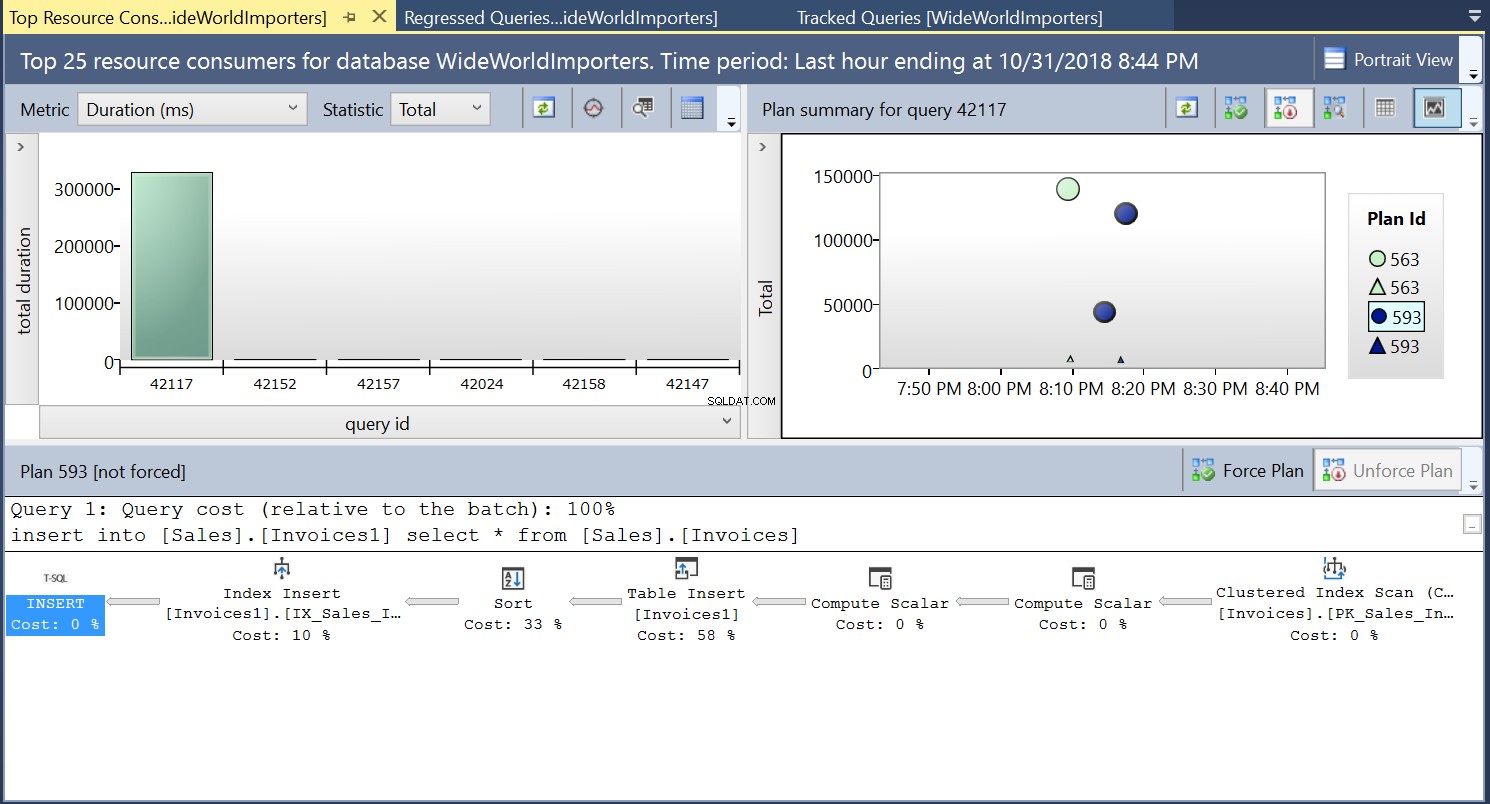
Fig. 4 Plan d'exécution 593
Regarder plus en profondeur
Nous pouvons examiner les détails des deux plans et voir comment ces nouveaux facteurs augmentent le temps d'exécution de l'instruction. Le plan 593 ajoute environ 300 ms supplémentaires à la durée moyenne de l'instruction. En cas de charge de travail élevée dans un environnement de production, cette différence peut être significative.
Activer STATISTICS IO lors de l'exécution de l'instruction d'insertion une seule fois dans les deux cas - avec index sur la table de destination et sans index sur la table de destination - montre également que plus de travail est effectué en termes d'E/S logiques lors de l'insertion de lignes dans une table avec des index.
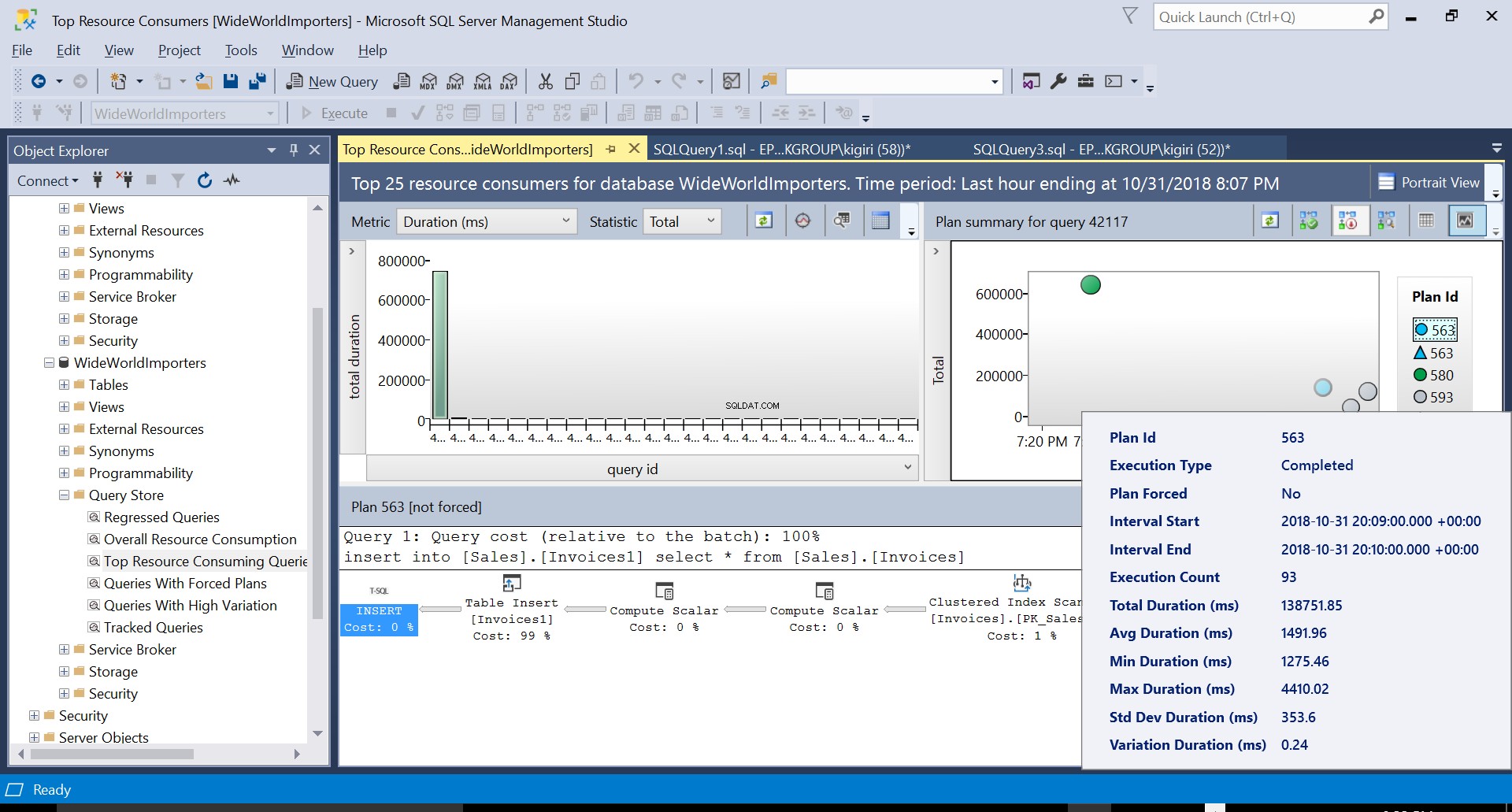
Fig. 5 Détails du plan d'exécution 563
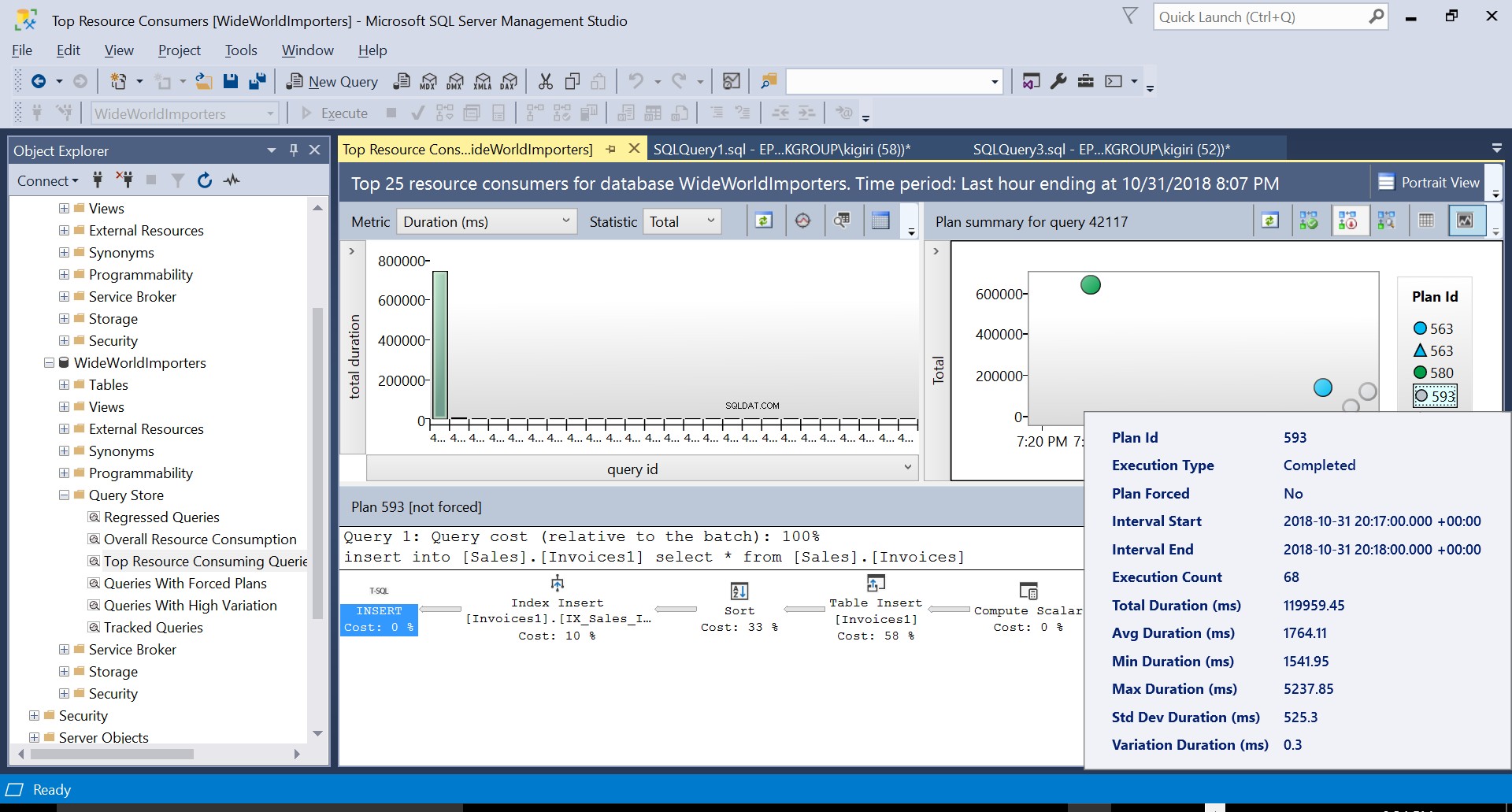
Fig. 4 Détails du plan d'exécution 593
Aucun index :Sortie avec STATISTICS IO activé :
Tableau ‘Factures1’. Nombre d'analyses 0, lectures logiques 78372 , physique lit 0, lecture anticipée lit 0, lob logique lit 0, lob physique lit 0, lob lecture anticipée lit 0.
Tableau ‘Factures’. Scan compte 1, lectures logiques 11400, physique lit 0, lecture anticipée lit 0, lob logique lit 0, lob physique lit 0, lob lecture anticipée lit 0.
(70510 lignes concernées)
Index :Sortie avec STATISTICS IO activé :
Tableau ‘Factures1’. Nombre d'analyses 0, lectures logiques 81119 , physique lit 0, lecture anticipée lit 0, lob logique lit 0, lob physique lit 0, lob lecture anticipée lit 0.
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau ‘Factures’. Nombre d'analyses 1, lectures logiques 11 400 , physique lit 0, lecture anticipée lit 0, lob logique lit 0, lob physique lit 0, lob lecture anticipée lit 0.
(70510 lignes concernées)
Informations supplémentaires
Microsoft et d'autres sources fournissent des scripts pour examiner l'environnement de production des index et identifier des situations telles que :
- Index redondants – Index qui sont dupliqués
- Index manquants – Index susceptibles d'améliorer les performances en fonction de la charge de travail
- Tas – Tables sans index clusterisés
- Tableaux surindexés – Tables avec plus d'index que de colonnes
- Utilisation de l'index – Nombre de recherches, scans et recherches sur les index
Les éléments 2, 3 et 5 sont davantage liés à l'impact sur les performances en ce qui concerne les lectures, tandis que les éléments 1 et 4 sont liés à l'impact sur les performances en ce qui concerne les écritures. Les listes 4 et 5 sont deux exemples de ces requêtes accessibles au public.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusion
Nous avons montré, à l'aide de Query Store, qu'une charge de travail supplémentaire avec un index peut introduire dans le plan d'exécution d'un exemple d'instruction d'insertion. En production, des index excessifs et redondants peuvent avoir un impact négatif sur les performances, en particulier dans les bases de données destinées aux charges de travail OLTP. Il est important d'utiliser les scripts et les outils disponibles pour examiner les index et déterminer s'ils améliorent ou nuisent réellement aux performances.
Outil utile :
dbForge Index Manager - complément SSMS pratique pour analyser l'état des index SQL et résoudre les problèmes de fragmentation d'index.