Aperçu
Cet article traite de deux approches différentes disponibles pour supprimer les lignes en double des tables SQL, ce qui devient souvent difficile avec le temps à mesure que les données augmentent si cela n'est pas fait à temps.
La présence de lignes en double est un problème courant auquel les développeurs et les testeurs SQL sont confrontés de temps en temps, cependant, ces lignes en double appartiennent à un certain nombre de catégories différentes dont nous allons discuter dans cet article.
Cet article se concentre sur un scénario spécifique, lorsque des données insérées dans une table de base de données conduisent à l'introduction d'enregistrements en double, puis nous examinerons de plus près les méthodes de suppression des doublons et enfin supprimerons les doublons à l'aide de ces méthodes.
Préparation des exemples de données
Avant de commencer à explorer les différentes options disponibles pour supprimer les doublons, il est utile à ce stade de mettre en place un exemple de base de données qui nous aidera à comprendre les situations dans lesquelles des données en double pénètrent dans le système et les approches à utiliser pour les éradiquer. .
Configurer l'exemple de base de données (UniversityV2)
Commencez par créer une base de données très simple qui se compose uniquement d'un étudiant tableau au début.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Remplir le tableau des élèves
Ajoutons seulement deux enregistrements à la table Student :
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Vérification des données
Affichez le tableau qui contient actuellement deux enregistrements distincts :
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
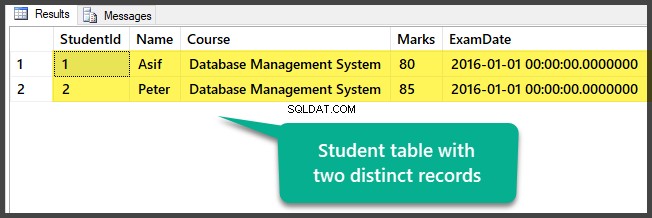
Vous avez préparé avec succès les exemples de données en configurant une base de données avec une table et deux enregistrements distincts (différents).
Nous allons maintenant discuter de certains scénarios potentiels dans lesquels des doublons ont été introduits et supprimés à partir de situations simples à légèrement complexes.
Cas 01 :Ajouter et supprimer des doublons
Nous allons maintenant introduire des lignes en double dans la table Student.
Conditions préalables
Dans ce cas, une table est dite avoir des enregistrements en double si le Nom d'un étudiant , Cours , Marques , et Date de l'examen coïncident dans plus d'un enregistrement même si la carte d'identité de l'étudiant est différent.
Nous supposons donc que deux étudiants ne peuvent pas avoir le même nom, cours, notes et date d'examen.
Ajout de données en double pour Student Asif
Insérons délibérément un enregistrement en double pour Etudiant :Asif à l'étudiant tableau comme suit :
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Afficher les données d'étudiants en double
Afficher l'étudiant tableau pour voir les enregistrements en double :
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
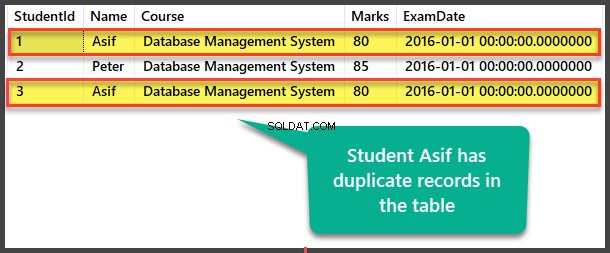
Recherche de doublons par méthode d'auto-référencement
Que se passe-t-il s'il y a des milliers d'enregistrements dans cette table, alors l'affichage de la table ne sera pas d'une grande aide.
Dans la méthode d'auto-référencement, nous prenons deux références à la même table et les joignons à l'aide d'un mappage colonne par colonne à l'exception de l'ID qui est rendu inférieur ou supérieur à l'autre.
Regardons la méthode d'auto-référencement pour trouver des doublons qui ressemble à ceci :
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
La sortie du script ci-dessus nous montre uniquement les enregistrements en double :

Recherche de doublons par la méthode d'auto-référence-2
Une autre façon de trouver des doublons à l'aide de l'auto-référence consiste à utiliser INNER JOIN comme suit :
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Suppression des doublons par la méthode d'auto-référencement
Nous pouvons supprimer les doublons en utilisant la même méthode que nous avons utilisée pour trouver les doublons, à l'exception de l'utilisation de DELETE conformément à sa syntaxe comme suit :
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Vérification des données après suppression des doublons
Vérifions rapidement les enregistrements après avoir supprimé les doublons :
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
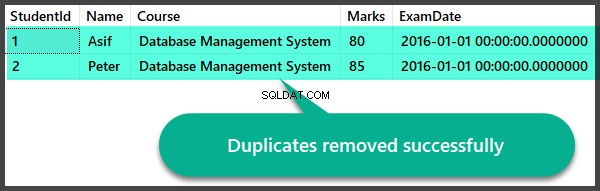
Création de la vue des doublons et procédure stockée de suppression des doublons
Maintenant que nous savons que nos scripts peuvent trouver et supprimer avec succès les lignes en double dans SQL, il est préférable de les transformer en vue et en procédure stockée pour en faciliter l'utilisation :
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
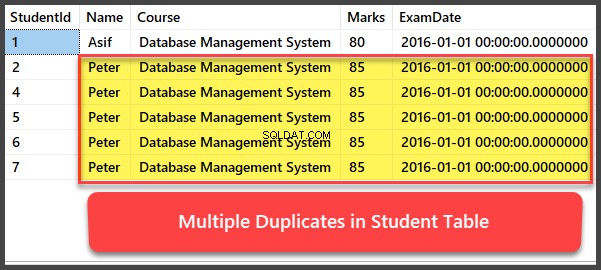
Ajouter et afficher plusieurs enregistrements en double
Ajoutons maintenant quatre autres enregistrements à Student table et tous les enregistrements sont des doublons de telle sorte qu'ils aient le même nom, cours, notes et date d'examen :
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
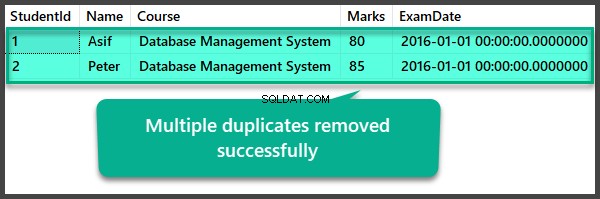
Suppression des doublons à l'aide de la procédure UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
Vérification des données après suppression de plusieurs doublons
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Cas 02 :Ajouter et supprimer des doublons avec les mêmes identifiants
Jusqu'à présent, nous avons identifié des enregistrements en double ayant des identifiants distincts, mais que se passe-t-il si les identifiants sont les mêmes ?
Par exemple, pensez au scénario dans lequel un tableau a été récemment importé à partir d'un fichier texte ou Excel qui n'a pas de clé primaire.
Conditions préalables
Dans ce cas, une table est dite avoir des enregistrements en double si toutes les valeurs de colonne sont exactement les mêmes, y compris une colonne d'ID et que la clé primaire est manquante, ce qui facilite la saisie des enregistrements en double.
Créer une table de cours sans clé primaire
Afin de reproduire le scénario dans lequel des enregistrements en double en l'absence de clé primaire tombent dans une table, créons d'abord un nouveau Cours table sans aucune clé primaire dans la base de données University2 comme suit :
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
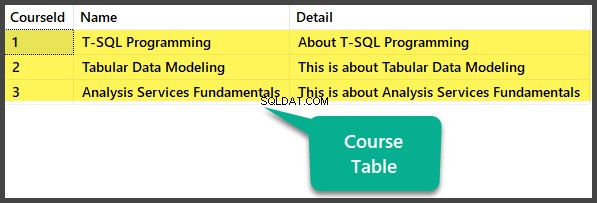
Remplir le tableau des cours
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Vérification des données
Voir le cours tableau :
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Ajout de données en double dans le tableau des cours
Insérez maintenant les doublons dans le cours tableau :
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Afficher les données de cours en double
Sélectionnez toutes les colonnes pour afficher le tableau :
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

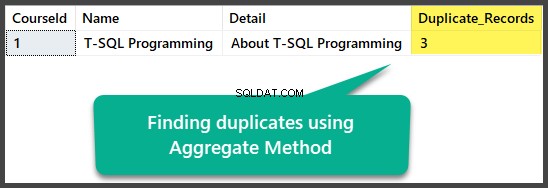
Recherche de doublons par méthode d'agrégation
Nous pouvons trouver des doublons exacts en utilisant la méthode d'agrégation en regroupant toutes les colonnes avec un total de plus d'une après avoir sélectionné toutes les colonnes et compté toutes les lignes à l'aide de la fonction count(*) :
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Cela peut être appliqué comme suit :
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Suppression des doublons par méthode agrégée
Supprimons les doublons en utilisant la méthode d'agrégation comme suit :
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Vérification des données
UTILISER UniversityV2
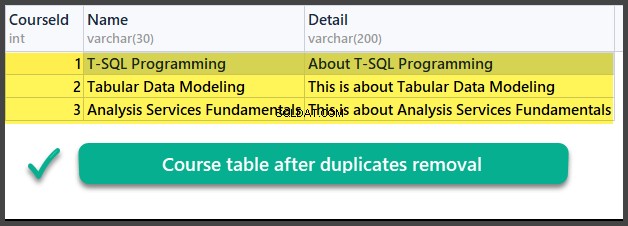
Nous avons donc appris avec succès comment supprimer les doublons d'une table de base de données en utilisant deux méthodes différentes basées sur deux scénarios différents.
Choses à faire
Vous pouvez désormais facilement identifier et soulager une table de base de données de la valeur en double.
1. Essayez de créer le UspRemoveDuplicatesByAggregate procédure stockée basée sur la méthode mentionnée ci-dessus et supprimer les doublons en appelant la procédure stockée
2. Essayez de modifier la procédure stockée créée ci-dessus (UspRemoveDuplicatesByAggregates) et implémentez les conseils de nettoyage mentionnés dans cet article.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Pouvez-vous être sûr que le UspRemoveDuplicatesByAggregate procédure stockée peut être exécutée autant de fois que possible, même après avoir supprimé les doublons, pour montrer que la procédure reste cohérente en premier lieu ?
4. Veuillez vous référer à mon article précédent Jump to Start Test-Driven Database Development (TDDD) - Part 1 et essayez d'insérer des doublons dans les tables de base de données SQLDevBlog, puis essayez de supprimer les doublons en utilisant les deux méthodes mentionnées dans cette astuce.
5. Veuillez essayer de créer un autre exemple de base de données EmployeesSample en vous référant à mon article précédent L'art d'isoler les dépendances et les données dans les tests unitaires de base de données et insérez des doublons dans les tables et essayez de les supprimer en utilisant les deux méthodes que vous avez apprises grâce à cette astuce.
Outil utile :
dbForge Data Compare for SQL Server – puissant outil de comparaison SQL capable de travailler avec le Big Data.