TimescaleDB est une base de données open source inventée pour rendre SQL évolutif pour les données de séries chronologiques. C'est un système de base de données relativement nouveau. TimescaleDB a été introduit sur le marché il y a deux ans et a atteint la version 1.0 en septembre 2018. Néanmoins, il est conçu sur un système RDBMS mature.
TimescaleDB est packagé en tant qu'extension PostgreSQL. Tout le code est sous licence open source Apache-2, à l'exception de certains codes sources liés aux fonctionnalités d'entreprise de séries chronologiques sous licence Timescale License (TSL).
En tant que base de données de séries chronologiques, elle fournit un partitionnement automatique entre les valeurs de date et de clé. La prise en charge SQL native de TimescaleDB en fait une bonne option pour ceux qui envisagent de stocker des données de séries chronologiques et qui possèdent déjà de solides connaissances en langage SQL.
Si vous recherchez une base de données de séries chronologiques pouvant utiliser du SQL riche, de la haute disponibilité, une solution de sauvegarde solide, la réplication et d'autres fonctionnalités d'entreprise, ce blog peut vous mettre sur la bonne voie.
Quand utiliser TimescaleDB
Avant de commencer avec les fonctionnalités de TimescaleDB, voyons où cela peut s'intégrer. TimescaleDB a été conçu pour offrir le meilleur du relationnel et du NoSQL, en mettant l'accent sur les séries chronologiques. Mais qu'est-ce que les données de séries chronologiques ?
Les données de séries chronologiques sont au cœur de l'Internet des objets, des systèmes de surveillance et de nombreuses autres solutions axées sur les données qui changent fréquemment. Comme le suggère le nom de « séries chronologiques », nous parlons de données qui changent avec le temps. Les possibilités de ce type de SGBD sont infinies. Vous pouvez l'utiliser dans divers cas d'utilisation industrielle de l'IdO dans les secteurs de la fabrication, de l'exploitation minière, du pétrole et du gaz, de la vente au détail, de la santé, de la surveillance des opérations de développement ou de l'information financière. Il peut également parfaitement s'intégrer dans les pipelines d'apprentissage automatique ou en tant que source d'opérations commerciales et d'intelligence.
Il ne fait aucun doute que la demande d'IoT et de solutions similaires va augmenter. Cela dit, nous pouvons également nous attendre à devoir analyser et traiter les données de différentes manières. Les données de séries chronologiques sont généralement uniquement ajoutées - il est peu probable que vous mettiez à jour d'anciennes données. En règle générale, vous ne supprimez pas de lignes particulières. En revanche, vous souhaiterez peut-être une sorte d'agrégation des données au fil du temps. Nous ne voulons pas seulement stocker l'évolution de nos données avec le temps, mais aussi les analyser et en tirer des leçons.
Le problème avec les nouveaux types de systèmes de bases de données est qu'ils utilisent généralement leur propre langage de requête. Il faut du temps aux utilisateurs pour apprendre une nouvelle langue. La plus grande différence entre TimescaleDB et d'autres bases de données de séries chronologiques populaires est la prise en charge de SQL. TimescaleDB prend en charge la gamme complète des fonctionnalités SQL, y compris les agrégats temporels, les jointures, les sous-requêtes, les fonctions de fenêtre et les index secondaires. De plus, si votre application utilise déjà PostgreSQL, aucune modification n'est nécessaire au code client.
Les bases de l'architecture
TimescaleDB est implémenté en tant qu'extension sur PostgreSQL, ce qui signifie qu'une base de données d'échelle de temps s'exécute dans une instance PostgreSQL globale. Le modèle d'extension permet à la base de données de tirer parti de nombreux attributs de PostgreSQL tels que la fiabilité, la sécurité et la connectivité à un large éventail d'outils tiers. Dans le même temps, TimescaleDB tire parti du degré élevé de personnalisation disponible pour les extensions en ajoutant des crochets en profondeur dans le planificateur de requêtes, le modèle de données et le moteur d'exécution de PostgreSQL.
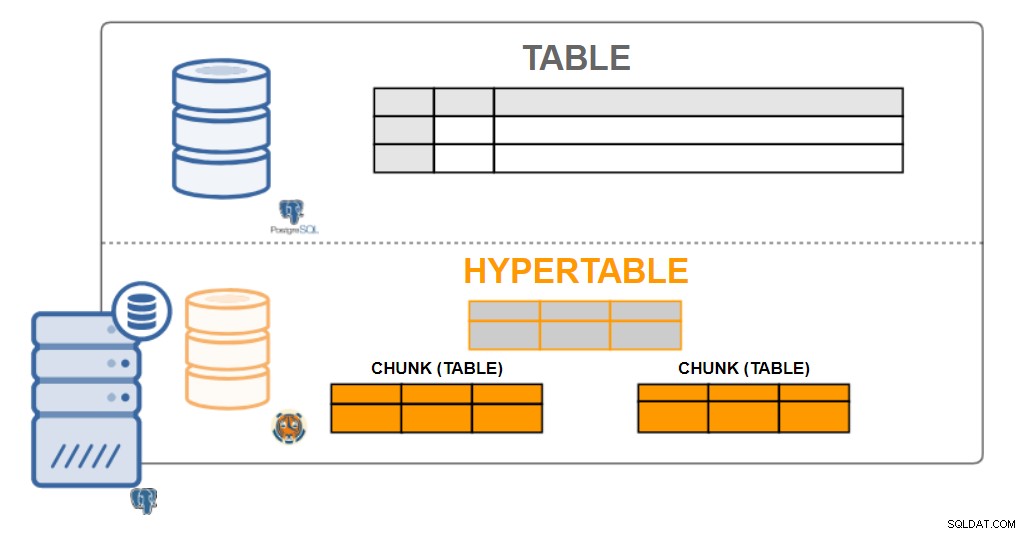 Architecture TimescaleDB
Architecture TimescaleDB Hypertables
Du point de vue de l'utilisateur, les données TimescaleDB ressemblent à des tables singulières, appelées hypertables. Les hypertables sont un concept ou une vue implicite de nombreuses tables individuelles contenant les données appelées blocs. Les données de l'hypertableau peuvent être à une ou deux dimensions. Il peut être agrégé par un intervalle de temps et par une valeur de "clé de partition" (facultative).
Pratiquement toutes les interactions des utilisateurs avec TimescaleDB se font avec des hypertables. La création de tables, d'index, la modification de tables, la sélection de données, l'insertion de données ... doivent tous être exécutés sur l'hypertable.
TimescaleDB effectue ce partitionnement étendu à la fois sur les déploiements à nœud unique et sur les déploiements en cluster (en développement). Bien que le partitionnement ne soit traditionnellement utilisé que pour la mise à l'échelle sur plusieurs machines, il nous permet également d'évoluer vers des taux d'écriture élevés (et des requêtes parallélisées améliorées) même sur des machines uniques.
Prise en charge des données relationnelles
En tant que base de données relationnelle, elle prend entièrement en charge SQL. TimescaleDB prend en charge des modèles de données flexibles qui peuvent être optimisés pour différents cas d'utilisation. Cela rend Timescale quelque peu différent de la plupart des autres bases de données de séries chronologiques. Le SGBD est optimisé pour l'ingestion rapide et les requêtes complexes, basé sur PostgreSQL et, si nécessaire, nous avons accès à un traitement robuste des séries chronologiques.
Installation
TimescaleDB, de la même manière que PostgreSQL, prend en charge de nombreuses méthodes d'installation différentes, y compris l'installation sur Ubuntu, Debian, RHEL/Centos, Windows ou les plates-formes cloud.
L'une des façons les plus pratiques de jouer avec TimescaleDB est une image docker.
La commande ci-dessous extrait une image Docker de Docker Hub si elle n'a pas déjà été installée, puis l'exécute.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPremière utilisation
Puisque notre instance est opérationnelle, il est temps de créer notre première base de données timescaledb. Comme vous pouvez le voir ci-dessous, nous nous connectons via la console PostgreSQL standard. Si vous avez des outils client PostgreSQL (par exemple, psql) installés localement, vous pouvez les utiliser pour accéder à l'instance Docker TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Opérations quotidiennes
Du point de vue de l'utilisation et de la gestion, TimescaleDB ressemble à PostgreSQL et peut être géré et interrogé en tant que tel.
Les principaux points à puces pour les opérations quotidiennes sont :
- Coexiste avec d'autres bases de données TimescaleDB et PostgreSQL sur un serveur PostgreSQL.
- Utilise SQL comme langage d'interface.
- Utilise des connecteurs PostgreSQL communs à des outils tiers pour les sauvegardes, la console, etc.
Paramètres TimescaleDB
Les paramètres prêts à l'emploi de PostgreSQL sont généralement trop conservateurs pour les serveurs modernes et TimescaleDB. Vous devez vous assurer que vos paramètres postgresql.conf sont réglés, soit en utilisant timescaledb-tune, soit en le faisant manuellement.
$ timescaledb-tuneLe script vous demandera de confirmer les modifications. Ces modifications sont ensuite écrites dans votre postgresql.conf et prendront effet au redémarrage.
Voyons maintenant quelques opérations de base du didacticiel TimescaleDB qui peuvent vous donner une idée de la façon de travailler avec le nouveau système de base de données.
Pour créer une hypertable, vous commencez avec une table SQL normale, puis vous la convertissez en une hypertable via la fonction create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Le convertir en hypertable est simple comme suit :
SELECT create_hypertable('conditions', 'time');L'insertion de données dans l'hypertable se fait via des commandes SQL normales :
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);La sélection de données, c'est du bon vieux SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Comme nous pouvons le voir ci-dessous, nous pouvons faire un groupe par, un ordre par et des fonctions. De plus, TimescaleDB inclut des fonctions d'analyse de séries temporelles qui ne sont pas présentes dans Vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;