Ce message a « des conditions attachées :pour une bonne raison. Nous allons explorer en profondeur SQL VARCHAR, le type de données qui traite les chaînes.
De plus, c'est "pour vos yeux seulement" car sans ficelles, il n'y aura pas d'articles de blog, de pages Web, d'instructions de jeu, de recettes mises en signet et bien plus encore à lire et à apprécier par nos yeux. Nous traitons un gazillion de cordes chaque jour. Ainsi, en tant que développeurs, vous et moi sommes responsables de rendre ce type de données efficace pour le stockage et l'accès.
Dans cet esprit, nous couvrirons ce qui compte le mieux pour le stockage et les performances. Entrez les choses à faire et à ne pas faire pour ce type de données.
Mais avant cela, VARCHAR n'est qu'un des types de chaîne en SQL. Qu'est-ce qui le rend différent ?
Qu'est-ce que VARCHAR dans SQL ? (Avec exemples)
VARCHAR est un type de données chaîne ou caractère de taille variable. Vous pouvez y stocker des lettres, des chiffres et des symboles. À partir de SQL Server 2019, vous pouvez utiliser la gamme complète de caractères Unicode lors de l'utilisation d'un classement avec prise en charge UTF-8.
Vous pouvez déclarer des colonnes ou des variables VARCHAR en utilisant VARCHAR[(n)], où n représente la taille de la chaîne en octets. La plage de valeurs pour n est de 1 à 8000. C'est beaucoup de données de caractères. Mais plus encore, vous pouvez le déclarer en utilisant VARCHAR(MAX) si vous avez besoin d'une chaîne gigantesque pouvant atteindre 2 Go. C'est assez grand pour votre liste de secrets et de choses privées dans votre journal ! Cependant, notez que vous pouvez également le déclarer sans la taille et qu'il est par défaut à 1 si vous le faites.
Prenons un exemple.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
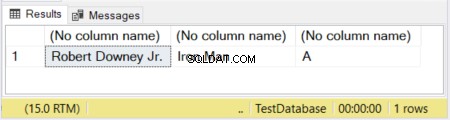
Dans la figure 1, les 2 premières colonnes ont leurs tailles définies. La troisième colonne est laissée sans taille. Ainsi, le mot "Avengers" est tronqué car un VARCHAR sans taille déclarée par défaut est de 1 caractère.
Maintenant, essayons quelque chose d'énorme. Mais notez que cette requête prendra un certain temps à s'exécuter - 23 secondes sur mon ordinateur portable.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
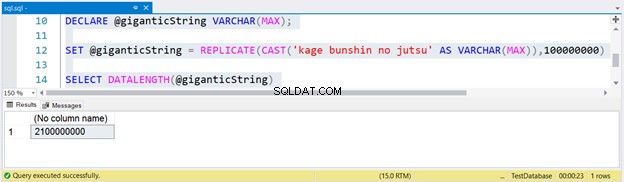
Pour générer une énorme chaîne, nous avons répliqué kage bunshin no jutsu 100 millions de fois. Notez le CAST dans REPLICATE. Si vous ne transmettez pas l'expression de chaîne à VARCHAR(MAX), le résultat sera tronqué jusqu'à 8 000 caractères uniquement.
Mais comment SQL VARCHAR se compare-t-il aux autres types de données de chaîne ?
Différence entre CHAR et VARCHAR en SQL
Comparé à VARCHAR, CHAR est un type de données de caractères de longueur fixe. Quelle que soit la taille de la valeur que vous attribuez à une variable CHAR, la taille finale est la taille de la variable. Vérifiez les comparaisons ci-dessous.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
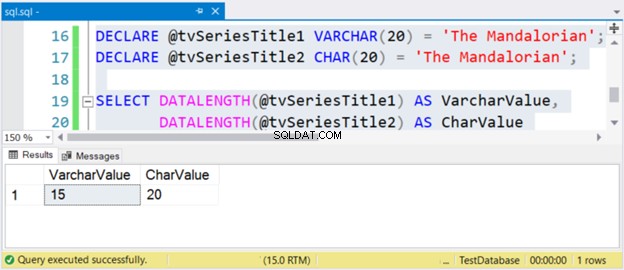
La taille de la chaîne "The Mandalorian" est de 15 caractères. Ainsi, la VarcharValue la colonne le reflète correctement. Cependant, CharValue conserve la taille de 20 - il est rempli de 5 espaces à droite.
SQL VARCHAR contre NVARCHAR
Deux choses fondamentales viennent à l'esprit lorsque l'on compare ces types de données.
Premièrement, c'est la taille en octets. Chaque caractère de NVARCHAR a deux fois la taille de VARCHAR. NVARCHAR(n) est compris entre 1 et 4000 uniquement.
Ensuite, les caractères qu'il peut stocker. NVARCHAR peut stocker des caractères multilingues comme le coréen, le japonais, l'arabe, etc. Si vous envisagez de stocker des paroles de K-Pop coréen dans votre base de données, ce type de données est l'une de vos options.
Prenons un exemple. Nous allons utiliser le groupe K-pop 세븐틴 ou Seventeen en anglais.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Le code ci-dessus affichera la valeur de la chaîne, sa taille en octets et le nombre de caractères. S'il s'agit de caractères non Unicode, le nombre de caractères est égal à la taille en octets. Mais ce n'est pas le cas. Consultez la figure 4 ci-dessous.
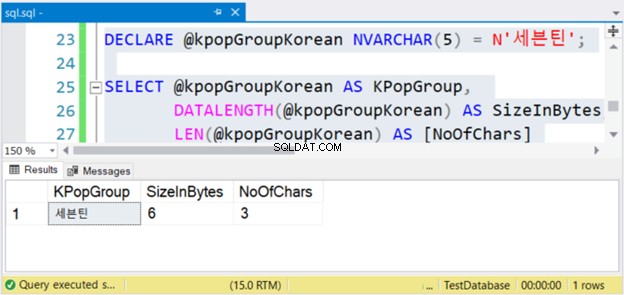
Voir? Si NVARCHAR a 3 caractères, la taille en octets est le double. Mais pas avec VARCHAR. Il en va de même si vous utilisez des caractères anglais.
Mais qu'en est-il du NCHAR ? NCHAR est l'équivalent de CHAR pour les caractères Unicode.
SQL Server VARCHAR avec prise en charge UTF-8
VARCHAR avec prise en charge UTF-8 est possible au niveau du serveur, de la base de données ou de la colonne de table en modifiant les informations de classement. Le classement à utiliser doit prendre en charge UTF-8.
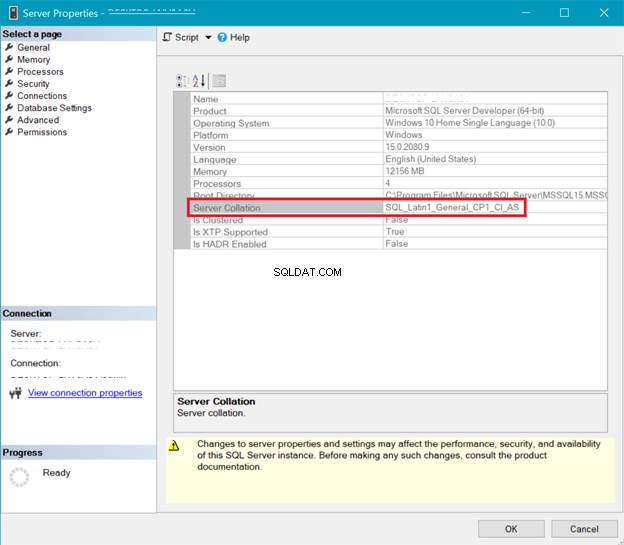
COLLEMENT SQL SERVER
La figure 5 présente la fenêtre de SQL Server Management Studio qui affiche le classement du serveur.
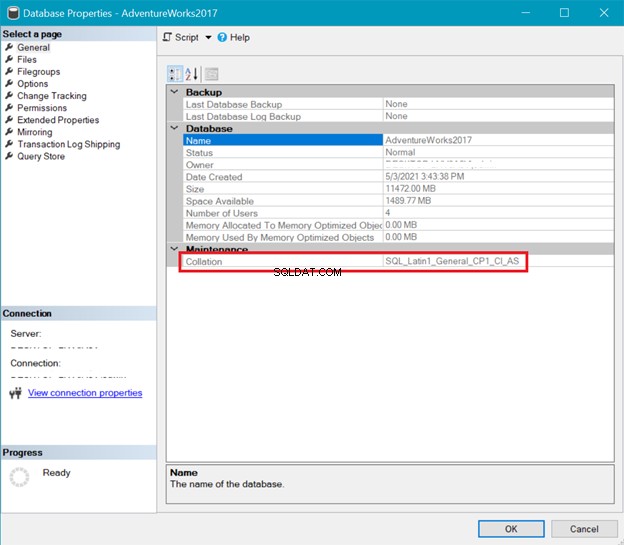
COLLATION DE BASE DE DONNÉES
Pendant ce temps, la figure 6 montre le classement de AdventureWorks base de données.
COLONNEMENT DE COLONNE DE TABLE
Le classement du serveur et de la base de données ci-dessus montre que UTF-8 n'est pas pris en charge. La chaîne de classement doit contenir un _UTF8 pour la prise en charge UTF-8. Mais vous pouvez toujours utiliser le support UTF-8 au niveau des colonnes d'une table. Voir l'exemple.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Le code ci-dessus a Latin1_General_100_BIN2_UTF8 classement pour le KoreanName colonne. Bien que VARCHAR et non NVARCHAR, cette colonne accepte les caractères coréens. Insérons quelques enregistrements, puis visualisons-les.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
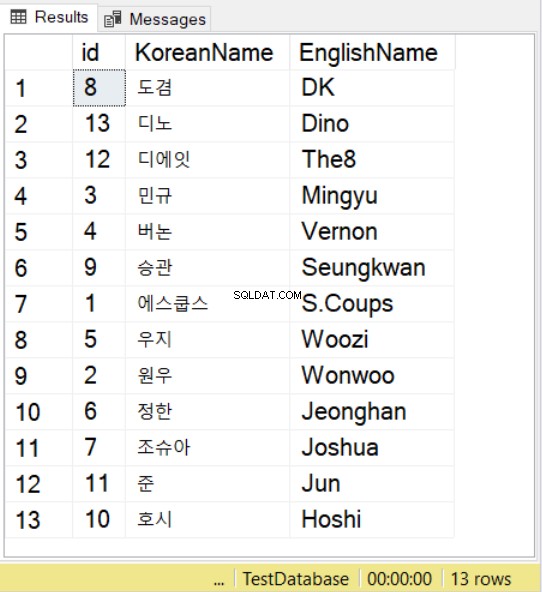
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Nous utilisons des noms du groupe Seventeen K-pop en utilisant des homologues coréens et anglais. Pour les caractères coréens, notez que vous devez toujours préfixer la valeur avec N , tout comme ce que vous faites avec les valeurs NVARCHAR.
Ensuite, lorsque vous utilisez SELECT avec ORDER BY, vous pouvez également utiliser le classement. Vous pouvez observer cela dans l'exemple ci-dessus. Cela suivra les règles de tri pour le classement spécifié.
STOCKAGE DE VARCHAR AVEC SUPPORT UTF-8
Mais comment se passe le stockage de ces personnages ? Si vous vous attendez à 2 octets par caractère, vous serez surpris. Consultez la figure 8.
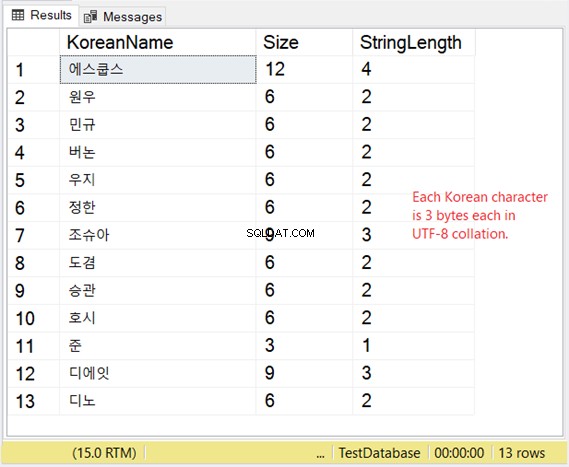
Donc, si le stockage compte beaucoup pour vous, tenez compte du tableau ci-dessous lorsque vous utilisez VARCHAR avec le support UTF-8.
| Personnages | Taille en octets |
| Ascii 0 – 127 | 1 |
| L'écriture latine et le grec, le cyrillique, le copte, l'arménien, l'hébreu, l'arabe, le syriaque, le tāna et le n'ko | 2 |
| Script d'Asie de l'Est comme le chinois, le coréen et le japonais | 3 |
| Caractères compris entre 010000 et 10FFFF | 4 |
Notre exemple coréen est un script d'Asie de l'Est, donc c'est 3 octets par caractère.
Maintenant que nous avons fini de décrire et de comparer VARCHAR à d'autres types de chaînes, couvrons maintenant les choses à faire et à ne pas faire
À faire dans l'utilisation de VARCHAR dans SQL Server
1. Spécifiez la taille
Qu'est-ce qui pourrait mal tourner sans spécifier la taille ?
TRUNCATION DE CHAÎNE
Si vous devenez paresseux en spécifiant la taille, la troncature de la chaîne se produira. Vous en avez déjà vu un exemple plus tôt.
INCIDENCE SUR LE STOCKAGE ET LES PERFORMANCES
Une autre considération est le stockage et les performances. Il vous suffit de définir la bonne taille pour vos données, pas plus. Mais comment pourriez-vous savoir? Pour éviter la troncature à l'avenir, vous pouvez simplement le définir sur la plus grande taille. C'est VARCHAR(8000) ou même VARCHAR(MAX). Et 2 octets seront stockés tels quels. Même chose avec 2 Go. Est-ce important ?
Répondre à cela nous amènera au concept de la façon dont SQL Server stocke les données. J'ai un autre article expliquant cela en détail avec des exemples et des illustrations.
En bref, les données sont stockées dans des pages de 8 Ko. Lorsqu'une ligne de données dépasse cette taille, SQL Server la déplace vers une autre unité d'allocation de page appelée ROW_OVERFLOW_DATA.
Supposons que vous disposiez de données VARCHAR à 2 octets pouvant correspondre à l'unité d'allocation de page d'origine. Lorsque vous stockez une chaîne supérieure à 8000 octets, les données seront déplacées vers la page de dépassement de ligne. Ensuite, réduisez-le à nouveau à une taille inférieure et il reviendra à la page d'origine. Le mouvement de va-et-vient provoque beaucoup d'E/S et un goulot d'étranglement des performances. Récupérer ceci à partir de 2 pages au lieu de 1 nécessite également des E/S supplémentaires.
Une autre raison est l'indexation. VARCHAR(MAX) est un grand NON comme clé d'index. Pendant ce temps, VARCHAR(8000) dépassera la taille maximale de la clé d'index. Cela correspond à 1 700 octets pour les index non clusterisés et à 900 octets pour les index clusterisés.
IMPACT DE LA CONVERSION DE DONNÉES
Pourtant, il y a une autre considération :la conversion des données. Essayez-le avec un CAST sans la taille comme le code ci-dessous.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Ce code effectuera une conversion d'une date/heure avec des informations de fuseau horaire en VARCHAR.
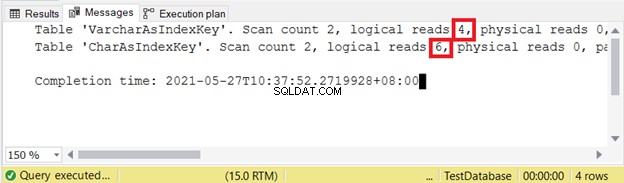
Donc, si nous devenons paresseux en spécifiant la taille pendant CAST ou CONVERT, le résultat est limité à 30 caractères seulement.
Que diriez-vous de convertir NVARCHAR en VARCHAR avec le support UTF-8 ? Il y a une explication détaillée à ce sujet plus tard, alors continuez à lire.
2. Utilisez VARCHAR si la taille de la chaîne varie considérablement
Les noms de AdventureWorks base de données varient en taille. L'un des noms les plus courts est Min Su, tandis que le nom le plus long est Osarumwense Uwaifiokun Agbonile. C'est entre 6 et 31 caractères, espaces compris. Importons ces noms dans 2 tables et comparons entre VARCHAR et CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Lequel des 2 est le meilleur ? Vérifions les lectures logiques en utilisant le code ci-dessous et en inspectant la sortie de STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Lectures logiques :
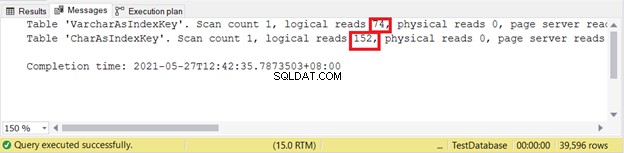
Moins les lectures sont logiques, mieux c'est. Ici, la colonne CHAR a utilisé plus du double de la contrepartie VARCHAR. Ainsi, VARCHAR gagne dans cet exemple.
3. Utilisez VARCHAR comme clé d'index au lieu de CHAR lorsque les valeurs varient en taille
Que s'est-il passé lorsqu'il a été utilisé comme clé d'index ? CHAR s'en sortira-t-il mieux que VARCHAR ? Utilisons les mêmes données de la section précédente et répondons à cette question.
Nous allons interroger certaines données et vérifier les lectures logiques. Dans cet exemple, le filtre utilise la clé d'index.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Lectures logiques :
Par conséquent, les clés d'index VARCHAR sont meilleures que les clés d'index CHAR lorsque la clé a des tailles variables. Mais qu'en est-il de INSERT et UPDATE qui modifieront les entrées d'index ?
LORS DE L'UTILISATION D'INSÉRER ET DE METTRE À JOUR
Testons 2 cas, puis vérifions les lectures logiques comme nous le faisons habituellement.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Lectures logiques :
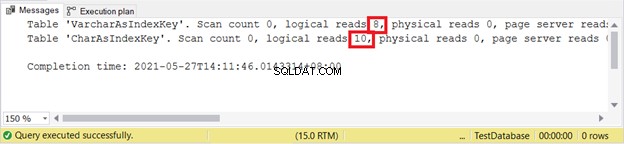
VARCHAR est toujours meilleur lors de l'insertion d'enregistrements. Que diriez-vous de la MISE À JOUR ?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Lectures logiques :
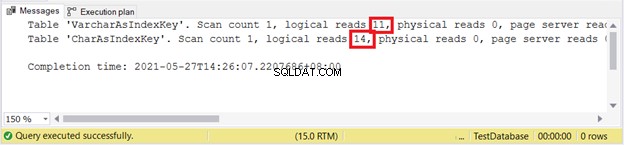
On dirait que VARCHAR gagne à nouveau.
Finalement, il remporte notre test, bien qu'il puisse être petit. Avez-vous un cas de test plus important qui prouve le contraire ?
4. Envisagez VARCHAR avec prise en charge UTF-8 pour les données multilingues (SQL Server 2019+)
S'il y a un mélange de caractères Unicode et non-Unicode dans votre table, vous pouvez envisager VARCHAR avec prise en charge UTF-8 sur NVARCHAR. Si la plupart des caractères se situent dans la plage ASCII 0 à 127, cela peut offrir des économies d'espace par rapport à NVARCHAR.
Pour voir ce que je veux dire, faisons une comparaison.
NVARCHAR À VARCHAR AVEC SUPPORT UTF-8
Avez-vous déjà migré vos bases de données vers SQL Server 2019 ? Envisagez-vous de migrer vos données de chaîne vers le classement UTF-8 ? Nous aurons un exemple de valeur mixte de caractères japonais et non japonais pour vous donner une idée.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Maintenant que les données sont définies, nous allons inspecter la taille en octets des 2 valeurs :

Surprise! Avec NVARCHAR, la taille est de 30 octets. C'est 15 fois plus que 2 caractères. Mais lorsqu'il est converti en VARCHAR avec prise en charge UTF-8, la taille n'est que de 27 octets. Pourquoi 27 ? Vérifiez comment cela est calculé.

Ainsi, 9 des caractères sont de 1 octet chacun. C'est intéressant car, avec NVARCHAR, les lettres anglaises font également 2 octets. Les autres caractères japonais font 3 octets chacun.
S'il s'agissait de tous les caractères japonais, la chaîne de 15 caractères serait de 45 octets et consommerait également la taille maximale de VarcharUTF8 colonne. Notez que la taille de NVarcharValue la colonne est inférieure à VarcharUTF8 .
Les tailles ne peuvent pas être égales lors de la conversion à partir de NVARCHAR, ou les données peuvent ne pas correspondre. Vous pouvez vous référer au Tableau 1 précédent.
Tenez compte de l'impact sur la taille lors de la conversion de NVARCHAR en VARCHAR avec prise en charge UTF-8.
A ne pas faire lors de l'utilisation de VARCHAR dans SQL Server
1. Lorsque la taille de la chaîne est fixe et non nulle, utilisez CHAR à la place.
La règle générale lorsqu'une chaîne de taille fixe est requise est d'utiliser CHAR. Je suis ceci quand j'ai une exigence de données qui nécessite des espaces remplis à droite. Sinon, j'utiliserai VARCHAR. J'ai eu quelques cas d'utilisation lorsque j'ai eu besoin de vider des chaînes de longueur fixe sans délimiteurs dans un fichier texte pour un client.
De plus, j'utilise les colonnes CHAR uniquement si les colonnes ne seront pas nullables. Pourquoi? Parce que la taille en octets des colonnes CHAR lorsque NULL est égale à la taille définie de la colonne. Pourtant, VARCHAR lorsque NULL a une taille de 1, quelle que soit la taille définie. Exécutez le code ci-dessous et voyez-le par vous-même.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Ne pas utiliser VARCHAR(n) Si n Dépassera 8000 octets. Utilisez plutôt VARCHAR(MAX).
Avez-vous une chaîne qui dépassera 8000 octets ? C'est le moment d'utiliser VARCHAR(MAX). Mais pour les formes de données les plus courantes comme les noms et les adresses, VARCHAR(MAX) est exagéré et aura un impact sur les performances. Dans mon expérience personnelle, je ne me souviens pas d'une exigence que j'ai utilisé VARCHAR(MAX).
3. Lors de l'utilisation de caractères multilingues avec SQL Server 2017 et versions antérieures. Utilisez plutôt NVARCHAR.
C'est un choix évident si vous utilisez toujours SQL Server 2017 et versions antérieures.
L'essentiel
Le type de données VARCHAR nous a bien servi pour tant d'aspects. C'est le cas pour moi depuis SQL Server 7. Pourtant, parfois, nous faisons encore de mauvais choix. Dans cet article, SQL VARCHAR est défini et comparé à d'autres types de données de chaîne avec des exemples. Et encore une fois, voici les choses à faire et à ne pas faire pour une base de données plus rapide :
À faire :
- Spécifiez la taille n dans VARCHAR[(n)] même si c'est facultatif.
- Utilisez-le lorsque la taille de la chaîne varie considérablement.
- Considérez les colonnes VARCHAR comme des clés d'index au lieu de CHAR.
- Et si vous utilisez maintenant SQL Server 2019, envisagez VARCHAR pour les chaînes multilingues avec prise en charge UTF-8.
À ne pas faire :
- N'utilisez pas VARCHAR lorsque la taille de la chaîne est fixe et non nulle.
- N'utilisez pas VARCHAR(n) lorsque la taille de la chaîne dépasse 8 000 octets.
- Et n'utilisez pas VARCHAR pour les données multilingues lorsque vous utilisez SQL Server 2017 et versions antérieures.
Avez-vous autre chose à ajouter? Faites le nous savoir dans la section "Commentaires. Si vous pensez que cela aidera vos amis développeurs, partagez-le sur vos plateformes de médias sociaux préférées.