Présentation
Récemment, nous avons rencontré un problème de performances intéressant sur l'une de nos bases de données SQL Server qui traite les transactions à un rythme élevé. La table des transactions utilisée pour capturer ces transactions est devenue une table active. En conséquence, le problème est apparu dans la couche d'application. Il s'agissait d'un délai d'expiration intermittent de la session cherchant à publier des transactions.
Cela s'est produit parce qu'une session « s'accrochait » généralement à la table et provoquait une série de faux verrous dans la base de données.
La première réaction d'un administrateur de base de données typique serait d'identifier la session de blocage principale et de la terminer en toute sécurité. C'était sûr car il s'agissait généralement d'une instruction SELECT ou d'une session inactive.
Il y a eu également d'autres tentatives pour résoudre le problème :
- Purger la table. Cela devait garantir de bonnes performances même si la requête devait analyser une table complète.
- Activation du niveau d'isolement READ COMMITTED SNAPSHOT pour réduire l'impact du blocage des sessions.
Dans cet article, nous allons essayer de recréer une version simpliste du scénario et de l'utiliser pour montrer comment une simple indexation peut résoudre des situations comme celle-ci lorsqu'elle est bien faite.
Deux tableaux associés
Jetez un œil aux Listing 1 et Listing 2. Ils montrent les versions simplifiées des tables impliquées dans le scénario considéré.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Le listing 3 montre un déclencheur qui insère quatre lignes dans le TranDetails tableau pour chaque ligne insérée dans le TranLog tableau.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Joindre la requête
Il est courant de trouver des tables de transactions prises en charge par de grandes tables. Le but est de conserver des transactions beaucoup plus anciennes ou de stocker les détails des enregistrements résumés dans la première table. Considérez cela comme des commandes et détails de la commande tables typiques des exemples de bases de données SQL Server. Dans notre cas, nous considérons le TranLog et TranDetails tableaux.
Dans des circonstances normales, les transactions remplissent ces deux tables au fil du temps. En termes de reporting ou de requêtes simples, la requête effectuera une jointure sur ces deux tables. Cette jointure capitalisera sur une colonne commune entre les tables.
Tout d'abord, nous remplissons le tableau à l'aide de la requête du Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
Dans notre exemple, la colonne commune utilisée par la jointure est le TranID colonne :
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Vous pouvez voir les deux exemples de requêtes simples qui utilisent une jointure pour récupérer des enregistrements de TranLog et TranDetails .
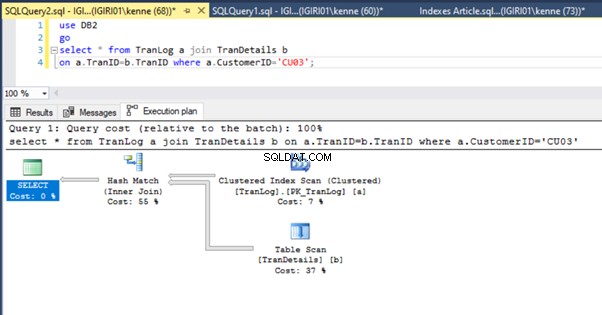
Lorsque nous exécutons les requêtes du Listing 5, dans les deux cas, nous devons effectuer une analyse complète de la table sur les deux tables (voir les figures 1 et 2). La partie dominante de chaque requête concerne les opérations physiques. Les deux sont des jointures internes. Cependant, le Listing 5a utilise une Hash Match join, tandis que le Listing 5b utilise une boucle imbriquée rejoindre. Remarque :la liste 5a renvoie 4 000 lignes tandis que la liste 4b renvoie 4 lignes.
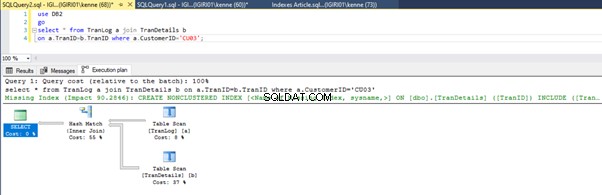
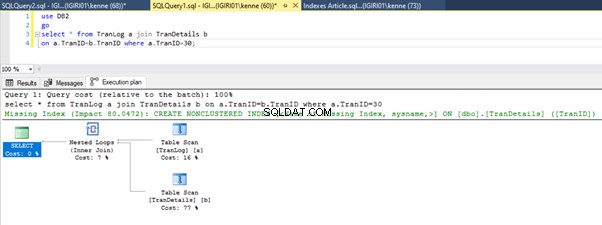
Trois étapes de réglage des performances
La première optimisation que nous faisons consiste à introduire un index (une clé primaire, pour être exact) sur le TranID colonne du TranLog tableau :
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
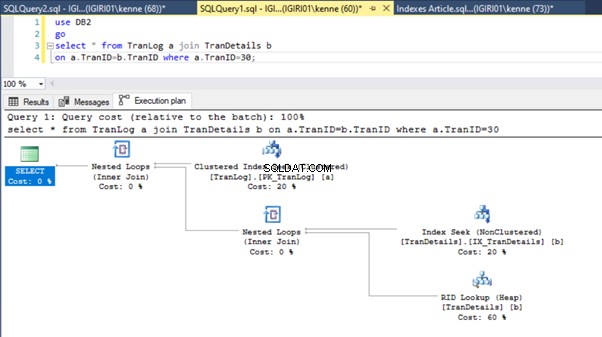
Les figures 3 et 4 montrent que SQL Server utilise cet index dans les deux requêtes, en effectuant une analyse dans le Listing 5a et une recherche dans le Listing 5b.
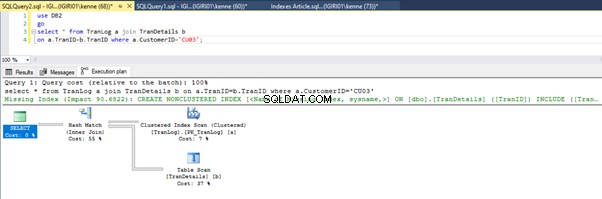
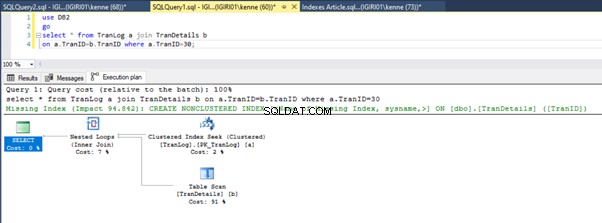
Nous avons une recherche d'index dans le Listing 5b. Cela se produit à cause de la colonne impliquée dans le prédicat de la clause WHERE - TranID. C'est cette colonne sur laquelle nous avons appliqué un index.
Ensuite, nous introduisons une clé étrangère sur le TranID colonne des TranDetails tableau (Liste 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Cela ne change pas grand-chose au plan d'exécution. La situation est pratiquement la même que celle illustrée précédemment dans les figures 3 et 4.
Puis on introduit un index sur la colonne de clé étrangère :
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Cette action modifie considérablement le plan d'exécution du Listing 5b (voir Figure 6). Nous voyons plus d'index cherche à se produire. Notez également la recherche RID dans la figure 6.
Les recherches RID sur les tas se produisent généralement en l'absence de clé primaire. Un tas est une table sans clé primaire.
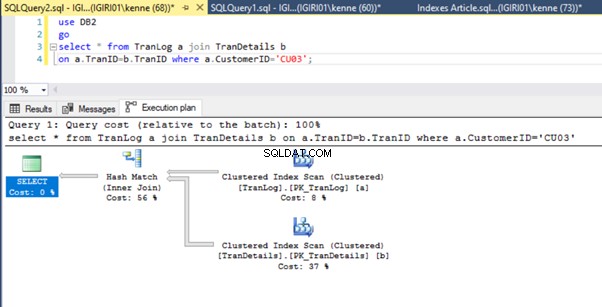
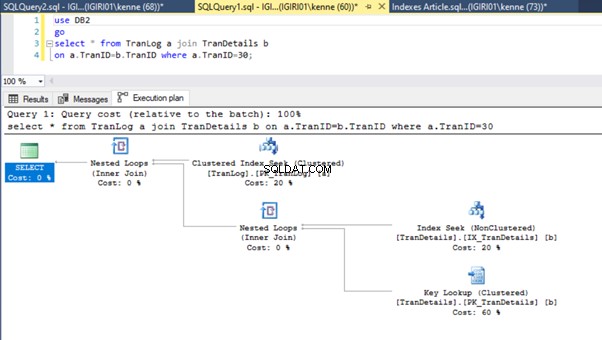
Enfin, nous ajoutons une clé primaire au TranDetails table. Cela supprime l'analyse de table et la recherche de tas RID dans les listes 5a et 5b respectivement (voir les figures 7 et 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusion
L'amélioration des performances introduite par les index est bien connue même des DBA novices. Cependant, nous tenons à souligner que vous devez examiner de près la façon dont les requêtes utilisent les index.
De plus, l'idée est d'établir la solution dans le cas particulier où nous avons les requêtes de jointure entre Transaction Log tableaux et Détail des transactions tableaux.
Il est généralement judicieux d'appliquer la relation entre ces tables à l'aide d'une clé et d'introduire des index dans les colonnes de clé primaire et étrangère.
Lors du développement d'applications qui utilisent une telle conception, les développeurs doivent garder à l'esprit les index et les relations requis au stade de la conception. Les outils modernes pour les spécialistes de SQL Server rendent ces exigences beaucoup plus faciles à remplir. Vous pouvez profiler vos requêtes à l'aide de l'outil spécialisé Query Profiler. Il fait partie de la solution professionnelle polyvalente dbForge Studio pour SQL Server développée par Devart pour simplifier la vie des DBA.



