Le sujet de la mise en cache est apparu dans PostgreSQL il y a déjà 22 ans, et à cette époque, l'accent était mis sur la fiabilité de la base de données.
Avance rapide jusqu'en 2020, les plateaux de disques sont cachés encore plus profondément dans les environnements virtualisés, les hyperviseurs et les appareils de stockage associés. De plus, les applications interconnectées et distribuées opérant à l'échelle mondiale réclament des connexions à faible latence et, tout d'un coup, des caches de serveur de réglage, et les requêtes SQL rivalisent pour garantir que les résultats sont renvoyés aux clients en quelques millisecondes. Les caches au niveau de l'application et en mémoire sont nés, et les requêtes de lecture sont désormais enregistrées à proximité des serveurs d'application. Par conséquent, les opérations d'E/S sont réduites aux seules écritures et la latence du réseau est considérablement améliorée. Avec un seul hic. Les implémentations sont responsables de leur propre gestion du cache, ce qui entraîne parfois une dégradation des performances.
La mise en cache des écritures est une question beaucoup plus compliquée, comme expliqué dans le wiki PostgreSQL.
Ce blog est un aperçu des caches de requêtes en mémoire et des équilibreurs de charge utilisés avec PostgreSQL.
Équilibrage de charge PostgreSQL
L'idée de l'équilibrage de charge a été évoquée en même temps que la mise en cache, en 1999, lorsque Bruce Momjiam a écrit :
[...] il est possible que nous soyons _très_ populaires dans un futur proche.
La base de l'implémentation de l'équilibrage de charge dans PostgreSQL est fournie par la fonctionnalité intégrée de redondance d'UC. La seule exigence est que l'application gère le basculement et c'est là qu'interviennent les solutions tierces. Nous examinerons certaines de ces solutions dans les sections suivantes.
Les requêtes à charge équilibrée ne peuvent renvoyer des résultats cohérents que tant que le délai de réplication synchrone est maintenu faible. En pratique, même une infrastructure réseau de pointe telle qu'AWS peut présenter des retards de plusieurs dizaines de millisecondes :
Nous observons généralement des temps de latence de l'ordre de 10 s de millisecondes. [...] Cependant, dans des conditions typiques, moins d'une minute de retard de réplication est courant. [...]
Les réplicas entre régions utilisant la réplication logique seront influencés par le taux de changement/d'application et les retards dans la communication réseau entre les régions spécifiques sélectionnées. Les réplicas interrégionaux utilisant Aurora Global Database auront un décalage typique de moins d'une seconde.
Comme indiqué précédemment, les solutions tierces reposent sur les fonctionnalités de base de PostgreSQL. Par exemple, l'équilibrage de charge des requêtes de lecture est réalisé à l'aide de plusieurs veilles synchrones.
Solutions
pgpool-II
pgpool-II est un produit riche en fonctionnalités fournissant à la fois l'équilibrage de charge et la mise en cache des requêtes en mémoire. Il s'agit d'un remplacement instantané, aucune modification du côté de l'application n'est requise.
En tant qu'équilibreur de charge, pgpool-II examine chaque requête SQL — pour être équilibrées en charge, les requêtes SELECT doivent remplir plusieurs conditions.
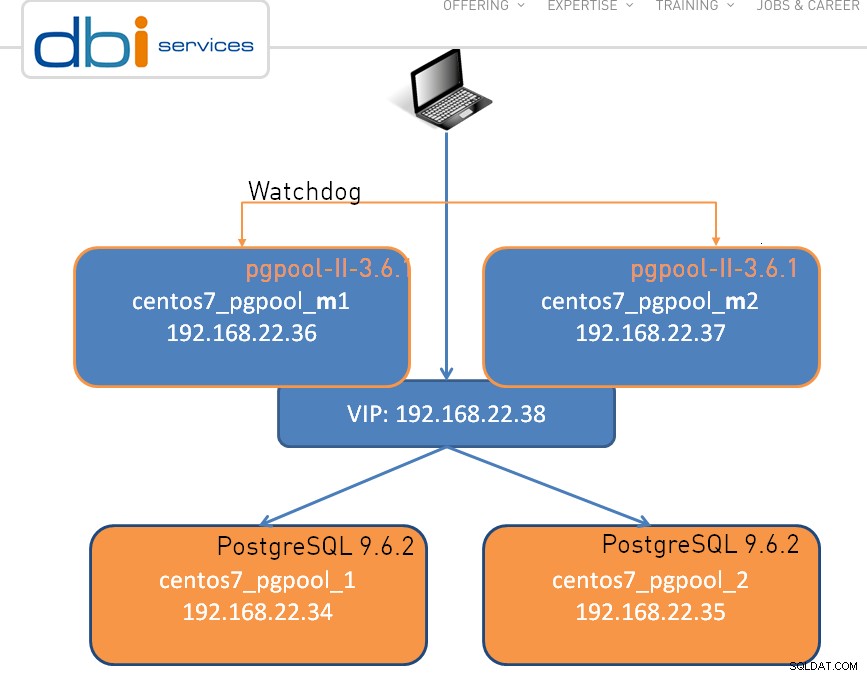
La configuration peut être aussi simple qu'un seul nœud, illustré ci-dessous est un cluster à deux nœuds :
Comme c'est le cas avec tout bon logiciel, il existe certaines limitations , et pgpool-II ne fait pas exception :
- Il ne gère pas les requêtes multi-instructions.
- Les requêtes SELECT sur les tables temporaires nécessitent le commentaire SQL /*NO LOAD BALANCE*/.
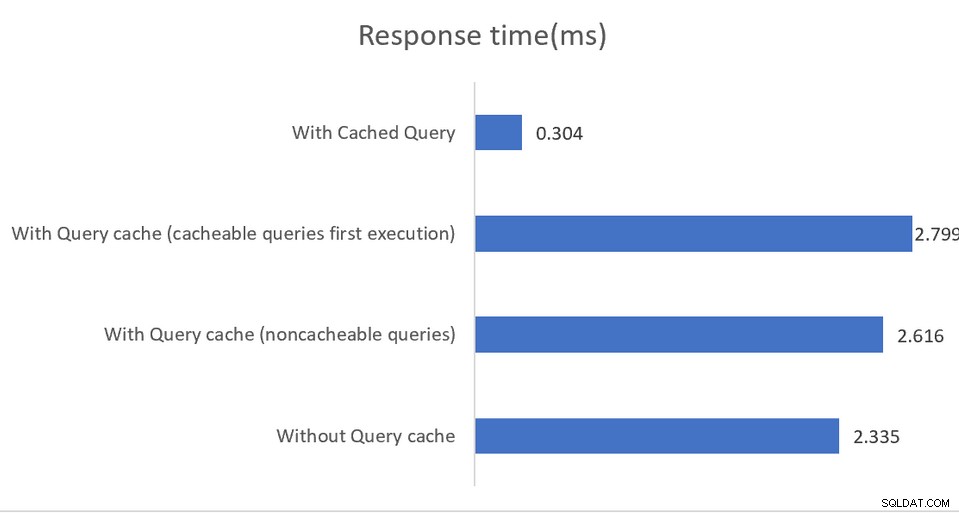
Les applications s'exécutant dans des environnements hautes performances bénéficieront d'une configuration mixte où pgBouncer est le pooleur de connexions et pgpool-II gère l'équilibrage de charge et la mise en cache. Le résultat est une augmentation impressionnante du débit multipliée par 4 et une réduction de la latence de 40 % :
La mise en cache en mémoire fonctionne, encore une fois, uniquement sur les requêtes de lecture, avec mise en cache les données sont enregistrées soit dans la mémoire partagée, soit dans une installation memcached externe. Bien que la documentation explique assez bien les différentes options de configuration, elle suggère indirectement que les implémentations doivent surveiller la sortie SHOW POOL CACHE afin d'alerter sur les taux de réussite tombant en dessous de la barre des 70 %, auquel cas le gain de performances fourni par la mise en cache est perdu.
Bucardo
Bucardo est un outil de réplication PostgreSQL écrit en Perl et PL/Perl.
J'ai mentionné Bucardo, car l'équilibrage de charge est l'une de ses fonctionnalités, selon le wiki PostgreSQL, cependant, une recherche sur Internet ne donne aucun résultat pertinent. Pour clarifier, je me suis dirigé vers la documentation officielle qui détaille le fonctionnement réel du logiciel :

C'est assez clair, Bucardo n'est pas un équilibreur de charge, tout comme a été signalé par les gens de Database Soup.
HA Proxy
HAProxy est un équilibreur de charge à usage général qui fonctionne au niveau TCP (pour les connexions à la base de données). Les vérifications de l'état garantissent que les requêtes ne sont envoyées qu'aux nœuds actifs.
Par rapport à pgpool-II, les applications utilisant HAProxy comme équilibreur de charge doivent être informées que le point de terminaison envoie les requêtes aux nœuds lecteurs.
Apache Ignite
Apache Ignite est un cache de second niveau qui comprend ANSI-99 SQL et prend en charge les transactions ACID. Apache Ignite ne comprend pas le protocole PostgreSQL Frontend/Backend et, par conséquent, les applications doivent utiliser une couche de persistance telle que Hibernate ORM. Comme alternative à la modification des applications, Apache Ignite fournit une `intégration memcached`_ qui nécessite l'extension PostgreSQL memcached. Malheureusement, cette dernière option n'est pas compatible avec les versions récentes de PostgreSQL, car l'extension pgmemcache a été mise à jour pour la dernière fois en 2017.
Données Heimdall
En tant que produit commercial, Heimdall Data coche les deux cases :équilibrage de charge et mise en cache. C'est un produit mature, ayant été présenté lors de conférences PostgreSQL dès PGCon 2017 :

Vous trouverez plus de détails et une démonstration du produit sur le blog Azure pour PostgreSQL .
Conclusion
Dans l'informatique distribuée d'aujourd'hui, la mise en cache des requêtes et l'équilibrage de charge sont aussi importants pour le réglage des performances de PostgreSQL que les célèbres GUC, le noyau du système d'exploitation, le stockage et l'optimisation des requêtes. Bien que pgpool-II et Heimdall Data soient les solutions open source et respectivement les solutions commerciales préférées, il existe des cas où des outils spécialement conçus peuvent être utilisés comme blocs de construction pour obtenir des résultats similaires.