Avant de passer en revue le problème de performances des enregistrements transférés et de le résoudre, nous devons revoir la structure des tables SQL Server.
Présentation de la structure des tableaux
Dans SQL Server, l'unité fondamentale du stockage des données est les pages de 8 Ko . Chaque page commence par un en-tête de 96 octets qui stocke les informations système sur cette page. Ensuite, les lignes du tableau seront stockées sur les pages de données en série après l'en-tête. À la fin de la page, la table de décalage de ligne, qui contient une entrée pour chaque ligne, sera stockée en face de la séquence des lignes dans la page. Cette entrée de décalage de ligne indique la distance entre le premier octet de cette ligne et le début de la page.
SQL Server nous fournit deux types de tables, basées sur la structure de cette table. Le cluster La table stocke et trie les données dans les pages de données en fonction de la colonne de clé d'index cluster prédéfinie ou des valeurs de colonnes. De plus, les pages de données de la table clusterisée sont triées et liées ensemble dans une liste liée basée sur les valeurs de clé d'index clusterisé. L'arbre B La structure de l'index clusterisé fournit une méthode d'accès rapide aux données basée sur les valeurs de clé de l'index clusterisé. Si une nouvelle ligne est insérée ou si une valeur de clé existante est mise à jour dans la table en cluster, SQL Server stocke la nouvelle valeur dans la position logique correcte qui correspond à la taille de la ligne insérée sans rompre les critères de classement. Si la valeur insérée ou mise à jour est supérieure à l'espace disponible dans la page de données, la page sera divisée en deux pages pour s'adapter à la nouvelle valeur.
Le deuxième type de tables est le Heap table, dans laquelle les données ne sont pas triées dans les pages de données dans n'importe quel ordre et les pages ne sont pas liées entre elles, car il n'y a pas d'index cluster défini sur cette table, pour appliquer des critères de tri. Suivre les pages qui ne sont triées selon aucun critère de classement ou liées entre elles dans la table de tas n'est pas une mission facile. Pour simplifier le processus de suivi de l'allocation de page dans la table de tas, SQL Server utilise la Index Allocation Map (IAM), la seule connexion logique entre les pages de données dans la table de tas, en conservant une entrée pour chaque page de données dans la table ou l'index dans la table IAM. Pour récupérer des données de la table de tas, SQL Server Engine analyse l'IAM pour localiser l'étendue, qui forme 8 pages qui stockent les données demandées.
Problème d'enregistrements transférés
Si une nouvelle ligne est insérée dans la table de tas, le moteur SQL Server analysera l'espace libre de page (PFS) pour suivre l'état d'allocation et l'utilisation de l'espace sur chaque page de données afin de trouver le premier emplacement disponible dans les pages de données qui correspond à la taille de ligne insérée. Ensuite, la ligne sera ajoutée à la page sélectionnée. Si la valeur insérée est supérieure à l'espace disponible dans les pages de données, une nouvelle page sera ajoutée à ce tableau pour pouvoir insérer la nouvelle valeur.
D'autre part, si les données existantes dans la table de tas sont modifiées, par exemple, nous avons mis à jour une chaîne de longueur variable avec une taille de données plus grande, et l'espace actuel ne correspond pas aux nouvelles données, les données seront déplacées vers un autre emplacement physique. l'emplacement et l'enregistrement transféré sera inséré dans la table de tas à l'emplacement des données d'origine, pour pointer vers le nouvel emplacement de ces données et pour simplifier l'emplacement des données de suivi. Le nouvel emplacement de données contient également un pointeur qui pointe vers le pointeur de transfert afin de le maintenir à jour dans le cas du déplacement des données depuis le nouvel emplacement et d'empêcher la longue chaîne de pointeurs de transfert ou de la supprimer. Cela peut également entraîner la suppression de l'enregistrement de transfert.
Bien que la méthode de redirection des enregistrements transférés réduise la nécessité pour les tables gourmandes en ressources et les opérations de reconstruction des index non clusterisés de mettre à jour les adresses de données chaque fois que l'emplacement des données est modifié, elle double également le nombre de lectures nécessaires pour récupérer les données. SQL Server visitera d'abord l'ancien emplacement, où il trouvera l'enregistrement transféré qui le redirige vers le nouvel emplacement de données. Ensuite, il lira les données demandées, effectuant l'opération de lecture deux fois. De plus, le problème des enregistrements transférés entraîne la modification des données séquentielles lues en données aléatoires, affectant négativement les performances de l'opération de récupération des données dans le temps.
Créons le tas ForwardRecordDemo suivant table à l'aide de l'instruction CREATE TABLE T-SQL ci-dessous :
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Ensuite, remplissez cette table avec des enregistrements 3K à des fins de test, à l'aide de l'instruction INSERT INTO T-SQL ci-dessous :
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identifier le problème des enregistrements transférés
Les informations sur le type de table et le nombre de pages consommées lors du stockage des données de la table, ainsi que le pourcentage de fragmentation de l'index et le nombre d'enregistrements transférés pour une table spécifique peuvent être consultés en interrogeant sys.dm_db_index_physical_stats fonction de gestion dynamique du système et en passant à la fonction DETAILED mode pour renvoyer le nombre d'enregistrements de transfert. Pour cela, utilisez le script T-SQL ci-dessous :
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Comme vous pouvez le voir dans le résultat de la requête, la table précédente est la table de tas sur laquelle aucun index clusterisé n'a été créé pour trier les données dans les pages et lier les pages entre elles. Les lignes 3K insérées dans le tableau sont affectées à 15 pages de données, sans enregistrements transférés et sans pourcentage de fragmentation, comme indiqué dans le résultat ci-dessous :

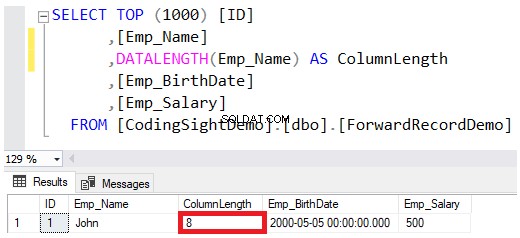
Lorsque vous définissez le type de données d'une colonne en tant que VARCHAR ou NVARCHAR, la valeur spécifiée dans la définition du type de données est la taille maximale autorisée pour cette chaîne, sans réserver entièrement cette quantité lors de l'enregistrement des valeurs dans les pages de données. Par exemple, le Jean le nom de l'employé inséré dans cette table ne réservera que 8 octets sur les 100 octets maximum pour cette colonne, en tenant compte du fait que l'enregistrement de la chaîne NVARCHAR doublera les octets requis pour la colonne VARCHAR, comme indiqué dans le DATALENGTH résultat de la fonction ci-dessous :
Si vous souhaitez mettre à jour la valeur de la colonne Emp_Name afin d'inclure le nom complet de l'employé John, utilisez l'instruction UPDATE ci-dessous :
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
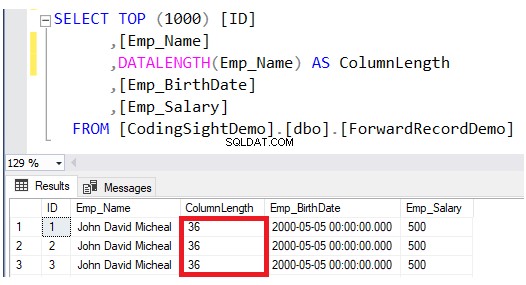
Vérifiez la longueur de la colonne mise à jour à l'aide de DATALENGTH une fonction. Vous verrez que la longueur de la colonne Emp_Name dans les lignes mises à jour a été étendue de 28 octets par colonne, soit environ 3,5 pages de données supplémentaires à ce tableau, comme indiqué dans le résultat ci-dessous :
Vérifiez ensuite le nombre d'enregistrements transférés après l'opération de mise à jour en interrogeant la fonction de gestion dynamique du système sys.dm_db_index_physical_stats. Pour cela, utilisez le script T-SQL ci-dessous :
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Comme vous pouvez le voir, la mise à jour de la colonne Emp_Name sur des enregistrements 1K avec des valeurs de chaîne plus grandes, sans ajouter de nouvel enregistrement, attribuera le supplément 5 pages à ce tableau, au lieu de 3,5 pages comme prévu auparavant. Cela se produira en raison de la génération de 484 enregistrements transférés pour pointer vers les nouveaux emplacements des données déplacées. Cela peut faire en sorte que le tableau soit 33 % fragmenté, comme indiqué clairement ci-dessous :

Encore une fois, si vous parvenez à mettre à jour la valeur de la colonne Emp_Name pour inclure le nom complet de l'employé de Zaid, utilisez l'instruction UPDATE ci-dessous :
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
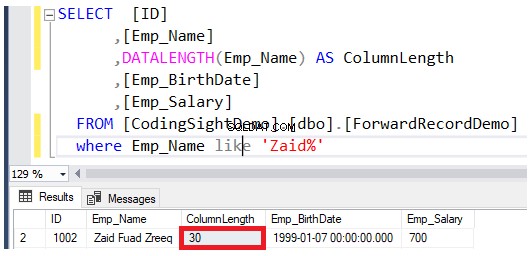
Vérifiez la longueur de la colonne mise à jour à l'aide de DATALENGTH une fonction. Vous verrez que la longueur de la colonne Emp_Name dans les lignes mises à jour a augmenté de 22 octets par colonne, soit environ 2,7 pages de données supplémentaires ajoutées à ce tableau, comme indiqué dans le résultat ci-dessous :
Vérifiez le nombre d'enregistrements transférés après avoir effectué l'opération de mise à jour. Vous pouvez le faire en interrogeant la fonction de gestion dynamique du système sys.dm_db_index_physical_stats à l'aide du même script T-SQL ci-dessous :
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Le résultat vous montrera que la mise à jour de la colonne Emp_Name sur les autres enregistrements 1K avec des valeurs de chaîne plus grandes sans insérer de nouvelle ligne attribuera un autre 4 pages à ce tableau, au lieu de 2,7 pages comme prévu. Cela se produira en raison de la génération de 417 supplémentaires enregistrements transférés afin de pointer vers les nouveaux emplacements des données déplacées et en conservant les mêmes 33 % pourcentage de fragmentation, comme indiqué ci-dessous :

Résoudre le problème des enregistrements transférés
Le moyen le plus simple de résoudre le problème des enregistrements transférés consiste à estimer la longueur maximale de la chaîne qui sera stockée dans la colonne et à l'affecter à l'aide de la longueur fixe type de données pour cette colonne plutôt que d'utiliser le type de données de longueur variable. Le moyen permanent optimal de résoudre le problème des enregistrements transférés consiste à ajouter l'index clusterisé à ce tableau. De cette manière, la table sera complètement convertie en une table clusterisée, qui est triée en fonction des valeurs de clé d'index clusterisées. Il contrôlera l'ordre des données existantes, les données nouvellement insérées et mises à jour qui ne correspondent pas à l'espace actuellement disponible dans la page de données, comme décrit précédemment dans l'introduction de cet article.
Si l'ajout de l'index clusterisé à cette table n'est pas une option pour des besoins spécifiques, tels que les tables intermédiaires ou les tables ETL, vous pouvez résoudre temporairement le problème des enregistrements transférés en surveillant les enregistrements transférés et en reconstruisant la table de tas pour le supprimer, cela met également à jour tous les index non clusterisés sur cette table de tas. La fonctionnalité de reconstruction de la table de tas est introduite dans SQL Server 2008, en utilisant ALTER TABLE…REBUILD Commande T-SQL.
Pour voir l'impact des performances des enregistrements transférés sur les requêtes de récupération de données, exécutons la requête SELECT qui effectue la recherche en fonction des valeurs de la colonne Emp_Nameю Cependant, avant d'exécuter la requête, activez les statistiques TIME et IO :
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
En conséquence, vous verrez que 925 des opérations de lecture logique sont effectuées pour récupérer les données demandées dans un délai de 84 ms comme indiqué ci-dessous :

Pour reconstruire la table de tas afin de supprimer tous les enregistrements transférés, utilisez la commande ALTER TABLE…REBUILD :
ALTER TABLE ForwardRecordDemo REBUILD;
Exécutez à nouveau la même instruction SELECT :
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Les statistiques TIME et IO vous montreront que seulement 21 opérations de lecture logique par rapport au 925 les opérations de lecture logique avec les enregistrements transférés inclus sont effectuées pour récupérer les données demandées dans les 79 ms :

Pour vérifier le nombre d'enregistrements transférés après la reconstruction de la table de tas, exécutez la fonction de gestion dynamique du système sys.dm_db_index_physical_stats, utilisez le même script T-SQL ci-dessous :
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Vous verrez que seulement 21 pages, avec les 3 précédentes pages consommées pour les enregistrements transférés, sont affectées à cette table pour stocker les données, ce qui est similaire au résultat estimé que nous avons obtenu lors des opérations d'insertion et de mise à jour des données (15 + 3,5 + 2,7). Après avoir reconstruit la table de tas, tous les enregistrements transférés sont maintenant supprimés. En conséquence, nous avons une table sans fragmentation :

Le problème des enregistrements transférés est un problème de performances important que les administrateurs de base de données doivent prendre en compte lors de la planification du entretien de la table de tas. Les résultats précédents sont extraits de notre table de test qui ne contient que des enregistrements 3K. Vous pouvez imaginer le nombre de pages qui seront gaspillées par les enregistrements transférés et la dégradation des performances d'E/S, en raison de la lecture d'un grand nombre d'enregistrements transférés lors de la lecture à partir de tables volumineuses !
Références :
- Guide d'architecture des pages et des étendues
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- La connaissance des "enregistrements transférés" peut aider à diagnostiquer des problèmes de performances difficiles à trouver