Galera Cluster 4.0 a été publié pour la première fois dans le cadre de MariaDB 10.4 et il y a beaucoup d'améliorations significatives dans cette version. La fonctionnalité la plus impressionnante de cette version est la réplication en continu, conçue pour gérer les problèmes suivants.
- Problèmes avec les longues transactions
- Problèmes avec les grosses transactions
- Problèmes avec les points chauds dans les tableaux
Dans un blog précédent, nous avons approfondi la nouvelle fonctionnalité de réplication en continu dans un blog en deux parties (Partie 1 et Partie 2). Une partie de cette nouvelle fonctionnalité de Galera 4.0 sont de nouvelles tables système qui sont très utiles pour interroger et vérifier les nœuds Galera Cluster ainsi que les journaux qui ont été traités dans Streaming Replication.
Aussi dans les blogs précédents, nous vous avons également montré comment déployer facilement un cluster MySQL Galera sur AWS et comment déployer un cluster MySQL Galera 4.0 sur Amazon AWS EC2.
Percona n'a pas encore publié d'AG pour son Percona XtraDB Cluster (PXC) 8.0 car certaines fonctionnalités sont encore en cours de développement, telles que la fonction MySQL wsrep WSREP_SYNC_WAIT_UPTO_GTID qui semble ne pas encore être présente (au moins sur la version PXC 8.0.15-5-27dev.4.2). Pourtant, lorsque PXC 8.0 sera publié, il sera doté de fonctionnalités exceptionnelles telles que...
- Cluster résilient amélioré
- Cluster convivial pour le cloud
- emballage amélioré
- Prise en charge du chiffrement
- DDL atomique
En attendant la sortie de PXC 8.0 GA, nous expliquerons dans ce blog comment vous pouvez créer un nœud de redondance d'UC sur Amazon AWS pour Galera Cluster 4.0 à l'aide de MariaDB.
Qu'est-ce qu'un Hot Standby ?
Une redondance d'UC est un terme courant en informatique, en particulier sur les systèmes hautement distribués. C'est une méthode de redondance dans laquelle un système fonctionne simultanément avec un système principal identique. Lorsqu'une défaillance se produit sur le nœud principal, le système de secours automatique prend immédiatement le relais pour remplacer le système principal. Les données sont mises en miroir sur les deux systèmes en temps réel.
Pour les systèmes de base de données, un serveur de secours automatique est généralement le deuxième nœud après le maître principal qui s'exécute sur des ressources puissantes (identiques au maître). Ce nœud secondaire doit être aussi stable que le maître principal pour fonctionner correctement.
Il sert également de nœud de récupération de données si le nœud maître ou l'ensemble du cluster tombe en panne. Le nœud de secours à chaud remplacera le nœud ou le cluster défaillant tout en répondant en permanence à la demande des clients.
Dans Galera Cluster, tous les serveurs faisant partie du cluster peuvent servir de nœud de secours. Cependant, si la région ou l'ensemble du cluster tombe en panne, comment pourrez-vous y faire face ? La création d'un nœud de secours en dehors de la région ou du réseau spécifique de votre cluster est une option ici.
Dans la section suivante, nous allons vous montrer comment créer un nœud de secours sur AWS EC2 à l'aide de MariaDB.
Déployer une redondance d'UC sur Amazon AWS
Précédemment, nous vous avons montré comment créer un cluster Galera sur AWS. Vous voudrez peut-être lire Déploiement de MySQL Galera Cluster 4.0 sur Amazon AWS EC2 si vous débutez avec Galera 4.0.
Le déploiement de votre nœud de secours à chaud peut se faire sur un autre ensemble de Galera Cluster qui utilise la réplication synchrone (consultez ce blog Zero Downtime Network Migration With MySQL Galera Cluster Using Relay Node) ou en déployant un nœud MySQL/MariaDB asynchrone . Dans ce blog, nous allons configurer et déployer le nœud de secours à chaud se répliquant de manière asynchrone à partir de l'un des nœuds Galera.
Configuration du cluster Galera
Dans cet exemple de configuration, nous avons déployé un cluster à 3 nœuds à l'aide de la version MariaDB 10.4.8. Ce cluster est en cours de déploiement dans la région USA Est (Ohio) et la topologie est illustrée ci-dessous :
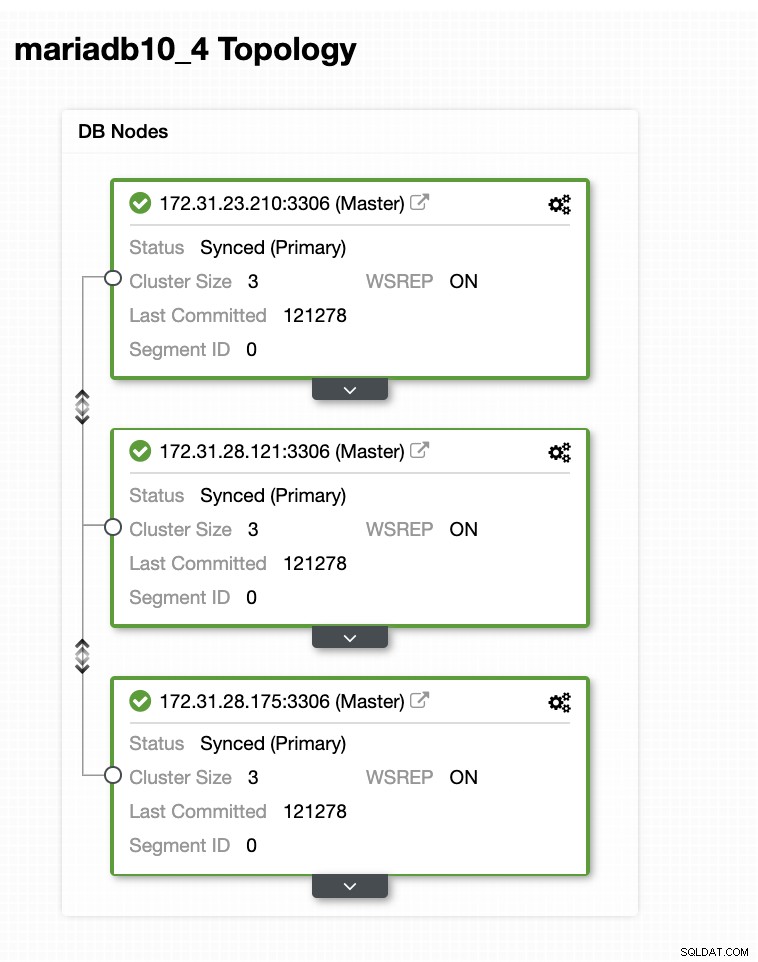
Nous utiliserons le serveur 172.31.26.175 comme maître pour notre esclave asynchrone qui servira de nœud de secours.
Configuration de votre instance EC2 pour le nœud de redondance d'UC
Dans la console AWS, accédez à EC2 dans la section Compute et cliquez sur Launch Instance pour créer une instance EC2 comme ci-dessous.
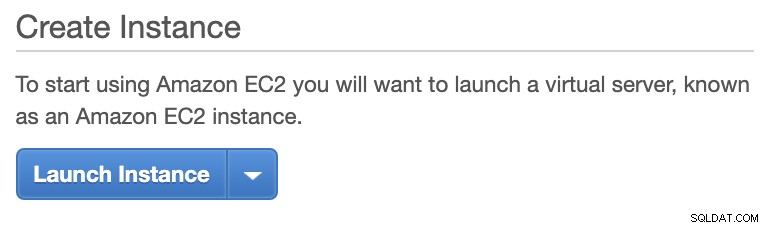
Nous allons créer cette instance sous la région USA Ouest (Oregon). Pour votre type de système d'exploitation, vous pouvez choisir le serveur que vous aimez (je préfère Ubuntu 18.04) et choisir le type d'instance en fonction de votre type de cible préféré. Pour cet exemple, j'utiliserai t2.micro car il ne nécessite aucune configuration sophistiquée et il est uniquement destiné à cet exemple de déploiement.
Comme nous l'avons mentionné précédemment, il est préférable que votre nœud de secours à chaud soit situé dans une région différente et non colocalisé ou dans la même région. Ainsi, si le centre de données régional tombe en panne ou subit une panne de réseau, votre serveur de secours peut être votre cible de basculement lorsque les choses tournent mal.
Avant de continuer, dans AWS, différentes régions auront leur propre Virtual Private Cloud (VPC) et leur propre réseau. Afin de communiquer avec les nœuds du cluster Galera, nous devons d'abord définir un peering VPC afin que les nœuds puissent communiquer au sein de l'infrastructure Amazon et n'aient pas besoin de sortir du réseau, ce qui ne fait qu'ajouter des problèmes de surcharge et de sécurité.
Tout d'abord, accédez à votre VPC à partir duquel votre nœud de secours automatique doit résider, puis accédez à Peering Connections. Ensuite, vous devez spécifier le VPC de votre nœud de secours et le VPC du cluster Galera. Dans l'exemple ci-dessous, j'ai us-west-2 interconnecté à us-east-2.
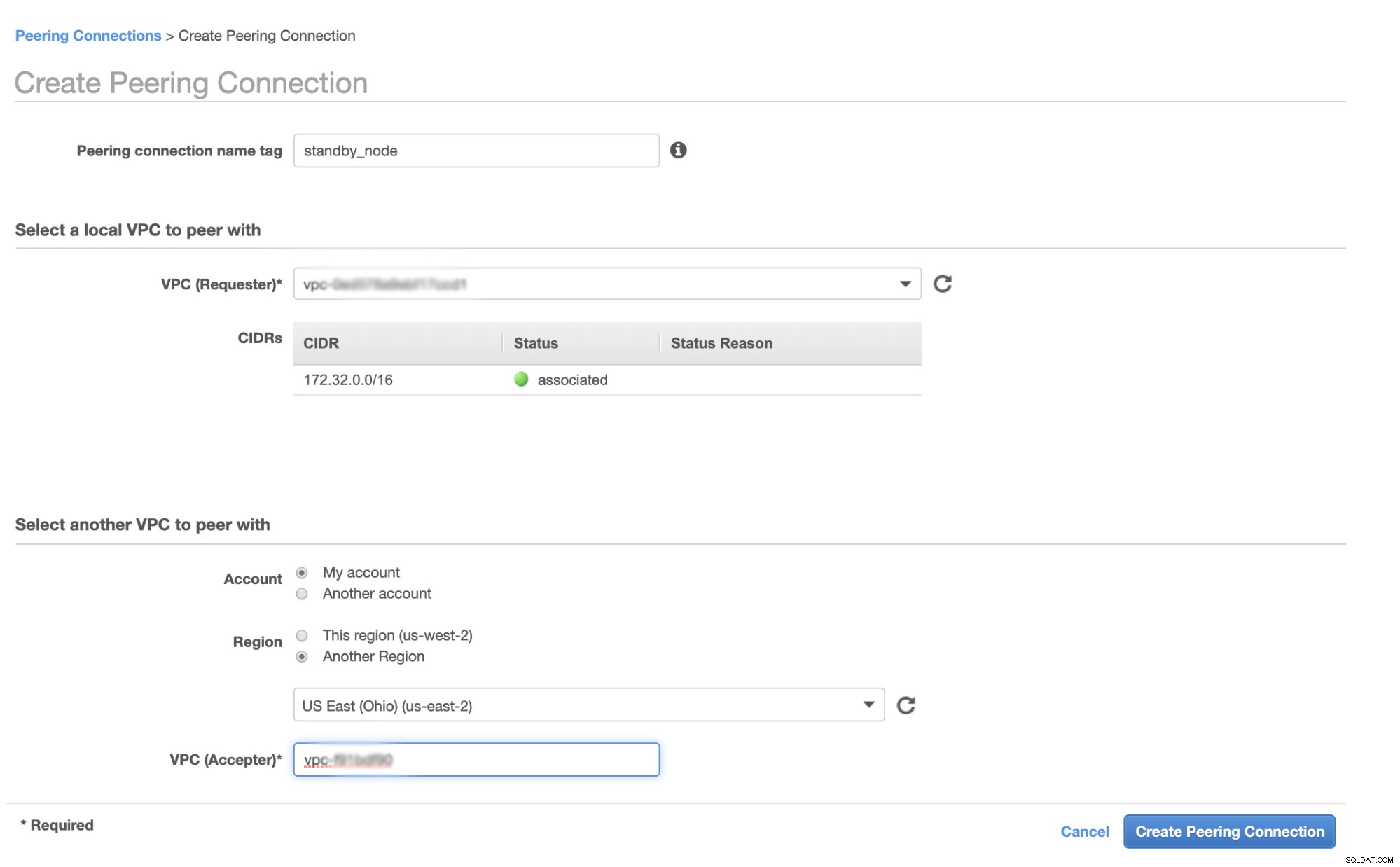
Une fois créé, vous verrez une entrée sous vos connexions d'appairage. Cependant, vous devez accepter la demande du VPC du cluster Galera, qui se trouve sur us-east-2 dans cet exemple. Voir ci-dessous,
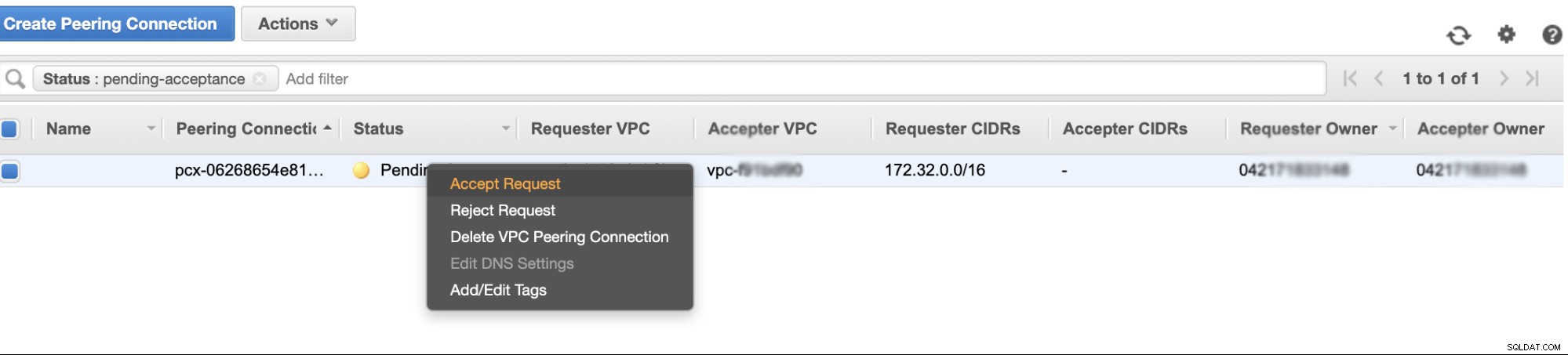
Une fois accepté, n'oubliez pas d'ajouter le CIDR à la table de routage. Consultez ce blog externe VPC Peering pour savoir comment procéder après VPC Peering.
Maintenant, revenons en arrière et continuons à créer le nœud EC2. Assurez-vous que votre groupe de sécurité dispose des règles correctes ou des ports requis qui doivent être ouverts. Consultez le manuel des paramètres du pare-feu pour plus d'informations à ce sujet. Pour cette configuration, j'ai simplement configuré Tout le trafic pour qu'il soit accepté, car il ne s'agit que d'un test. Voir ci-dessous,
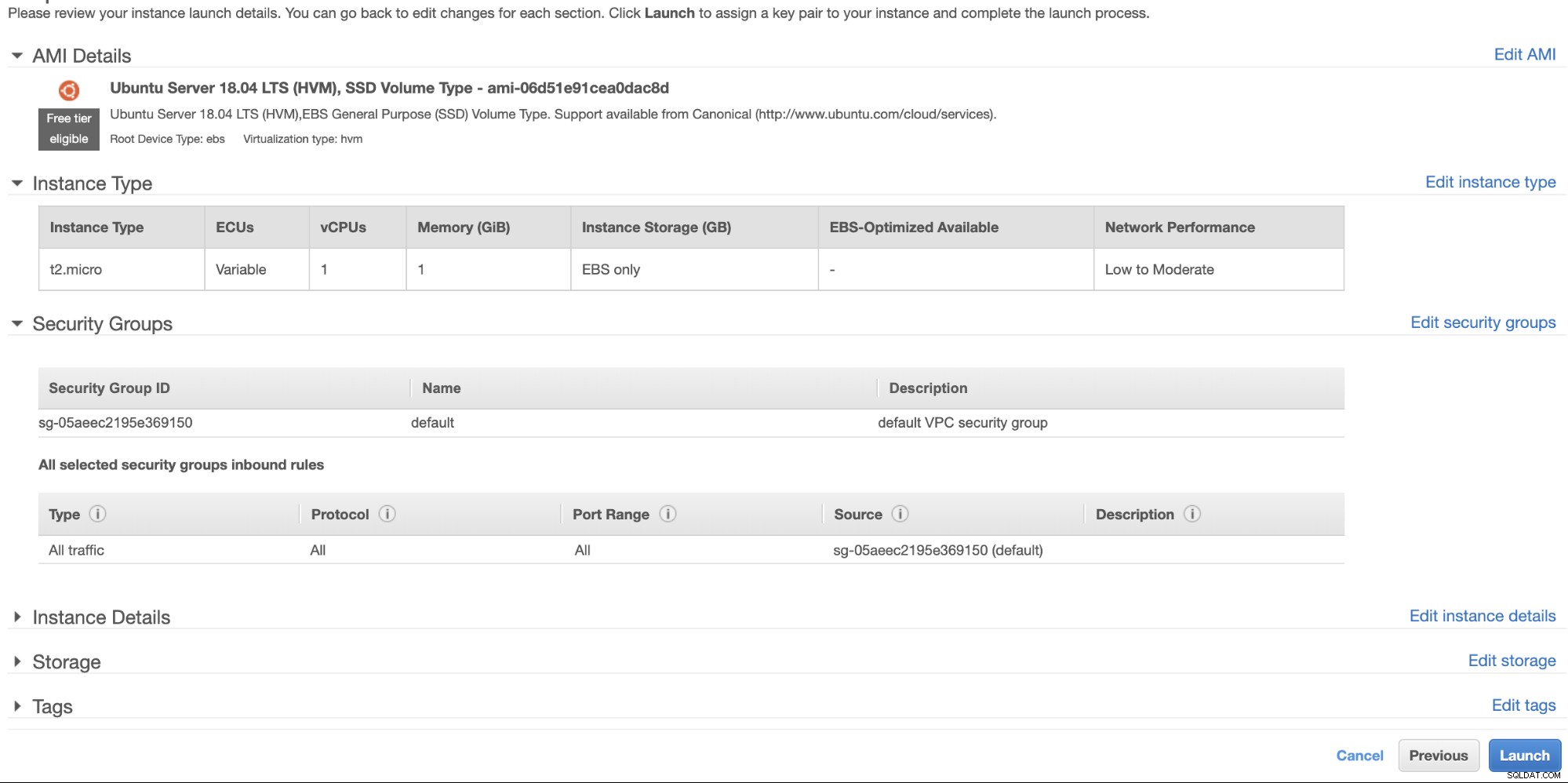
Assurez-vous lors de la création de votre instance, que vous avez défini le bon VPC et que vous avez défini votre propre sous-réseau. Vous pouvez consulter ce blog au cas où vous auriez besoin d'aide à ce sujet.
Configuration de l'esclave asynchrone MariaDB
Première étape
Nous devons d'abord configurer le référentiel, ajouter les clés du référentiel et mettre à jour la liste des packages dans le cache du référentiel,
$ vi /etc/apt/sources.list.d/mariadb.list
$ apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8
$ apt updateÉtape 2
Installer les packages MariaDB et ses binaires requis
$ apt-get install mariadb-backup mariadb-client mariadb-client-10.4 libmariadb3 libdbd-mysql-perl mariadb-client-core-10.4 mariadb-common mariadb-server-10.4 mariadb-server-core-10.4 mysql-commonÉtape 3
Maintenant, prenons une sauvegarde en utilisant xbstream pour transférer les fichiers sur le réseau depuis l'un des nœuds de notre Galera Cluster.
## Effacez le répertoire de données du MySQL nouvellement installé dans votre nœud de secours à chaud.
$ systemctl stop mariadb
$ rm -rf /var/lib/mysql/*## Ensuite, sur le nœud de secours à chaud, exécutez ceci sur le terminal,
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | mbstream -x -C /var/lib/mysql## Ensuite, sur le maître cible, c'est-à-dire l'un des nœuds de votre cluster Galera (qui est le nœud 172.31.28.175 dans cet exemple), exécutez ceci sur le terminal,
$ mariabackup --backup --target-dir=/tmp --stream=xbstream | socat - TCP4:172.32.31.2:9999où 172.32.31.2 est l'adresse IP du nœud de secours de l'hôte.
Étape 4
Préparez votre fichier de configuration MySQL. Comme c'est dans Ubuntu, j'édite le fichier dans /etc/mysql/my.cnf et avec l'exemple suivant my.cnf tiré de notre modèle ClusterControl,
[MYSQLD]
user=mysql
basedir=/usr/
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
pid_file=/var/lib/mysql/mysql.pid
port=3306
log_error=/var/log/mysql/mysqld.log
log_warnings=2
# log_output = FILE
#Slow logging
slow_query_log_file=/var/log/mysql/mysql-slow.log
long_query_time=2
slow_query_log=OFF
log_queries_not_using_indexes=OFF
### INNODB OPTIONS
innodb_buffer_pool_size=245M
innodb_flush_log_at_trx_commit=2
innodb_file_per_table=1
innodb_data_file_path = ibdata1:100M:autoextend
## You may want to tune the below depending on number of cores and disk sub
innodb_read_io_threads=4
innodb_write_io_threads=4
innodb_doublewrite=1
innodb_log_file_size=64M
innodb_log_buffer_size=16M
innodb_buffer_pool_instances=1
innodb_log_files_in_group=2
innodb_thread_concurrency=0
# innodb_file_format = barracuda
innodb_flush_method = O_DIRECT
innodb_rollback_on_timeout=ON
# innodb_locks_unsafe_for_binlog = 1
innodb_autoinc_lock_mode=2
## avoid statistics update when doing e.g show tables
innodb_stats_on_metadata=0
default_storage_engine=innodb
# CHARACTER SET
# collation_server = utf8_unicode_ci
# init_connect = 'SET NAMES utf8'
# character_set_server = utf8
# REPLICATION SPECIFIC
server_id=1002
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
report_host=172.31.29.72
gtid_ignore_duplicates=ON
gtid_strict_mode=ON
# OTHER THINGS, BUFFERS ETC
key_buffer_size = 24M
tmp_table_size = 64M
max_heap_table_size = 64M
max_allowed_packet = 512M
# sort_buffer_size = 256K
# read_buffer_size = 256K
# read_rnd_buffer_size = 512K
# myisam_sort_buffer_size = 8M
skip_name_resolve
memlock=0
sysdate_is_now=1
max_connections=500
thread_cache_size=512
query_cache_type = 0
query_cache_size = 0
table_open_cache=1024
lower_case_table_names=0
# 5.6 backwards compatibility (FIXME)
# explicit_defaults_for_timestamp = 1
performance_schema = OFF
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0
[MYSQL]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[client]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[mysqldump]
socket=/var/lib/mysql/mysql.sock
max_allowed_packet = 512M
# default_character_set = utf8
[xtrabackup]
[MYSQLD_SAFE]
# log_error = /var/log/mysqld.log
basedir=/usr/
# datadir = /var/lib/mysqlBien sûr, vous pouvez modifier cela en fonction de votre configuration et de vos besoins.
Étape 5
Préparez la sauvegarde à partir de l'étape 3, c'est-à-dire la sauvegarde finale qui se trouve maintenant dans le nœud de secours en exécutant la commande ci-dessous,
$ mariabackup --prepare --target-dir=/var/lib/mysqlÉtape 6
Définissez la propriété du répertoire de données dans le nœud de secours automatique,
$ chown -R mysql.mysql /var/lib/mysqlÉtape 7
Maintenant, démarrez l'instance MariaDB
$ systemctl start mariadbÉtape huit
Enfin, nous devons configurer la réplication asynchrone,
## Créer l'utilisateur de réplication sur le nœud maître, c'est-à-dire le nœud du cluster Galera
MariaDB [(none)]> CREATE USER 'cmon_replication'@'172.32.31.2' IDENTIFIED BY 'PahqTuS1uRIWYKIN';
Query OK, 0 rows affected (0.866 sec)
MariaDB [(none)]> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cmon_replication'@'172.32.31.2';
Query OK, 0 rows affected (0.127 sec)## Obtenez la position de l'esclave GTID à partir de xtrabackup_binlog_info comme suit,
$ cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000002 71131632 1000-1000-120454## Ensuite, configurez la réplication esclave comme suit,
MariaDB [(none)]> SET GLOBAL gtid_slave_pos='1000-1000-120454';
Query OK, 0 rows affected (0.053 sec)
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='172.31.28.175', MASTER_USER='cmon_replication', master_password='PahqTuS1uRIWYKIN', MASTER_USE_GTID = slave_pos;## Maintenant, vérifiez l'état de l'esclave,
MariaDB [(none)]> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.31.28.175
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-120454
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Ajout de votre nœud de redondance d'UC à ClusterControl
Si vous utilisez ClusterControl, il est facile de surveiller la santé de votre serveur de base de données. Pour l'ajouter en tant qu'esclave, sélectionnez le cluster de nœuds Galera que vous avez, puis accédez au bouton de sélection comme indiqué ci-dessous pour ajouter un esclave de réplication :
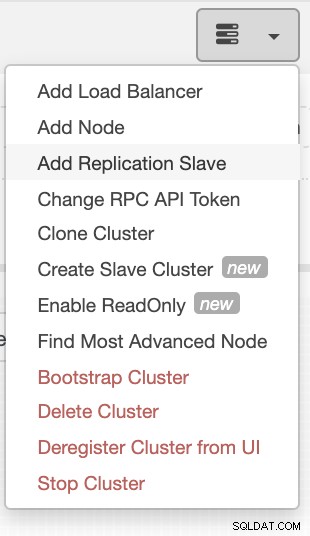
Cliquez sur Ajouter un esclave de réplication et choisissez d'ajouter un esclave existant comme ci-dessous,
Notre topologie semble prometteuse.
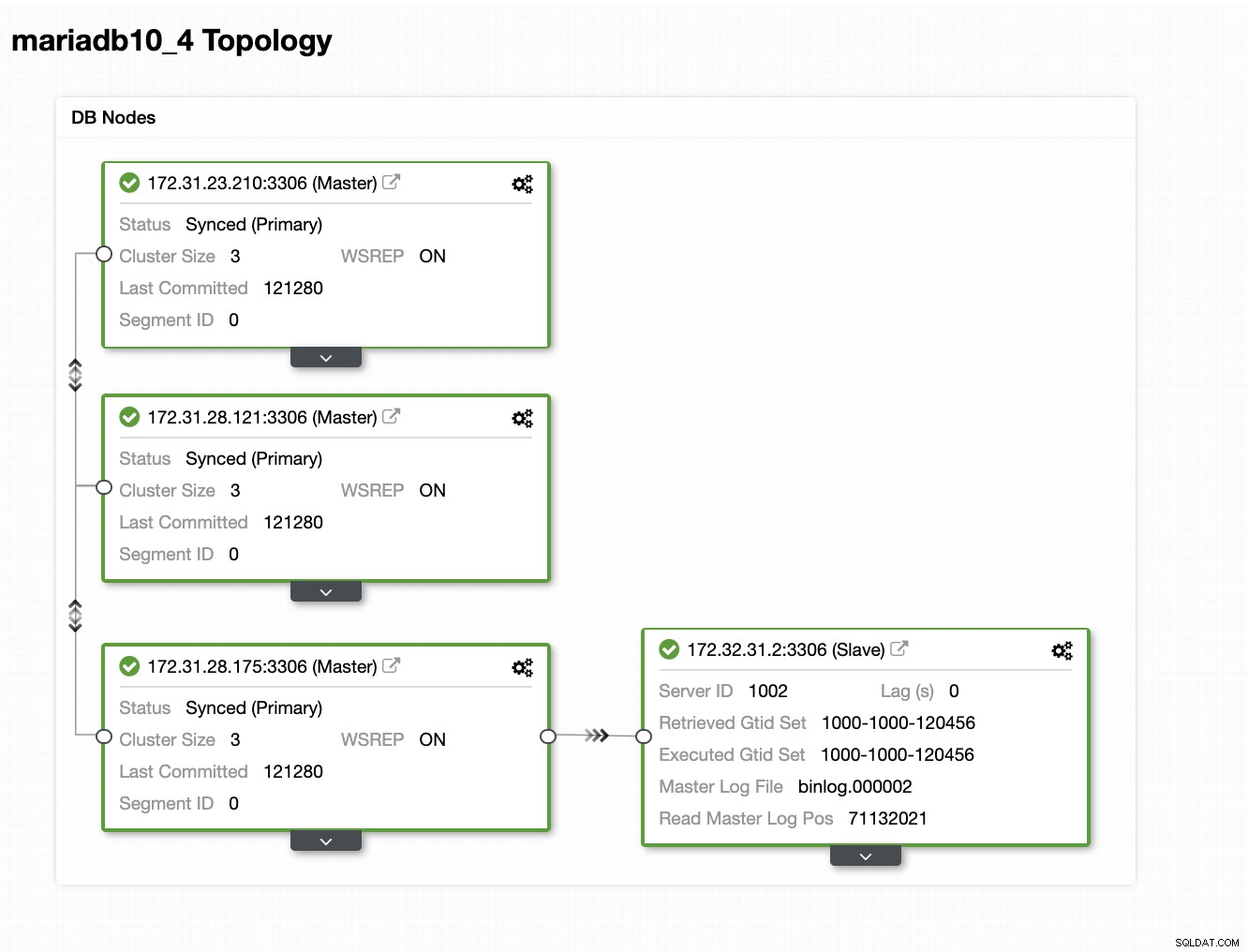
Comme vous le remarquerez peut-être, notre nœud 172.32.31.2 sert de serveur de secours Le nœud a un CIDR différent qui préfixe comme 172.32.% us-west-2 (Oregon) tandis que les autres nœuds sont de 172.31.% situés sur us-east-2 (Ohio). Ils sont totalement sur une région différente, donc en cas de panne de réseau sur vos nœuds Galera, vous pouvez basculer vers votre nœud de secours à chaud.
Conclusion
Créer une redondance d'UC sur Amazon AWS est simple et direct. Tout ce dont vous avez besoin est de déterminer vos besoins en capacité et la topologie, la sécurité et les protocoles de votre réseau qui doivent être configurés.
L'utilisation de VPC Peering permet d'accélérer l'intercommunication entre différentes régions sans passer par l'Internet public, de sorte que la connexion reste au sein de l'infrastructure réseau d'Amazon.
L'utilisation de la réplication asynchrone avec un esclave n'est bien sûr pas suffisante, mais ce blog sert de base sur la façon dont vous pouvez l'initier. Vous pouvez maintenant facilement créer un autre cluster où l'esclave asynchrone se réplique et créer une autre série de clusters Galera servant de nœuds de reprise après sinistre, ou vous pouvez également utiliser la variable gmcast.segment dans Galera pour répliquer de manière synchrone, tout comme ce que nous avons sur ce blog.