Dans l'article précédent, j'expliquais comment installer Ubuntu 18.04 et SQL Server 2019 sur les machines virtuelles. Maintenant, avant d'aller plus loin, passons en revue la configuration.
Nous avons créé trois machines virtuelles, et les détails sont les suivants :
| Nom d'hôte | Adresse IP | Rôle |
| LinuxSQL01 | 192.168.0.140 | Réplica principal |
| LinuxSQL02 | 192.168.0.141 | Réplica secondaire synchrone |
| LinuxSQL03 | 192.168.0.142 | Réplica secondaire asynchrone |
Mettez à jour le fichier hôte.
Dans la configuration, nous n'utilisons pas de serveur de domaine. Par conséquent, pour résoudre le nom d'hôte, nous devons ajouter une entrée dans le fichier hôte.
Le fichier hôte est situé sur /etc annuaire. Exécutez la commande ci-dessous pour modifier le fichier :
example@sqldat.com:/# vim /etc/hostsDans le fichier hôte, entrez les noms d'hôte et les adresses IP de toutes les machines virtuelles :
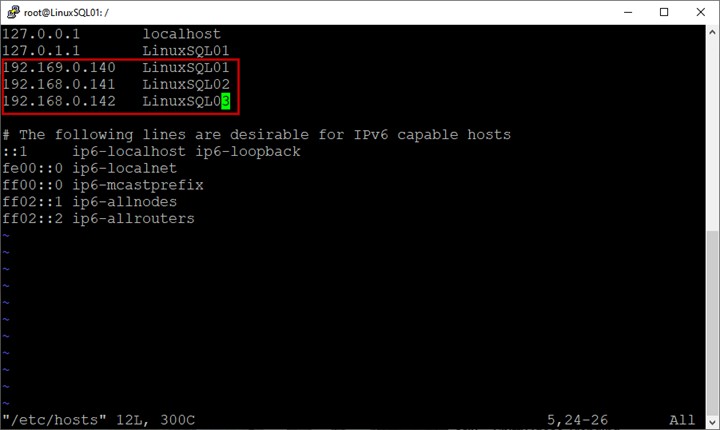
Enregistrez le fichier hôte.
Effectuez les mêmes étapes sur toutes les machines virtuelles.
Activer les groupes de disponibilité SQL Server AlwaysOn
Avant de déployer AlwaysOn, nous devons activer la fonctionnalité de haute disponibilité dans SQL Server.
Dans Windows Server 2016, cette option peut être activée à partir du gestionnaire de configuration SQL Server, mais dans la plate-forme Linux, nous devons le faire avec une commande bash.
Connectez-vous à LinuxSQL01 à l'aide de Putty et exécutez la commande suivante :
example@sqldat.com:~# sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Redémarrez les services SQL Server :
example@sqldat.com:~# service mssql-server restartEffectuez les étapes ci-dessus sur toutes les machines virtuelles.
Créer les certificats pour l'authentification
Contrairement à AlwaysOn sur le serveur Windows, le déploiement Linux ne nécessite pas de contrôleur de domaine. Pour l'authentification et la communication entre les réplicas primaires et secondaires, il utilise le certificat.
Le script suivant crée un certificat et une clé principale. Ensuite, il sauvegarde le certificat et le sécurise avec un mot de passe.
Connectez-vous à LinuxSQL01 et exécutez le script suivant :
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE AG_Auth_Cert
TO FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/ AG_Auth_Cert_backup.pvk',
ENCRYPTION BY PASSWORD = 'abcd!1234'
);
Une fois le certificat et la clé principale créés, nous les copions dans des réplicas secondaires (LinuxSQL02 et LinuxSQL03) en exécutant la commande ci-dessous.
Assurez-vous que la clé principale et l'emplacement du certificat sont identiques sur toutes les répliques et disposent d'une autorisation de lecture-écriture.
/*Copy certificate and the key to LinuxSQL02*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
/*Copy certificate and the key to LinuxSQL03*/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.cer example@sqldat.com:/var/opt/mssql/data/
scp /var/opt/mssql/data/AG_Auth_Cert_backup.pvk example@sqldat.com:/var/opt/mssql/data/
Exécutez la commande suivante sur les nœuds secondaires pour accorder l'autorisation de lecture-écriture sur le certificat et la clé privée :
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
/*Grant read-write permission on certificate and key to example@sqldat.com*/
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.pvk
example@sqldat.com:~# chmod 777 /var/opt/mssql/data/AG_Auth_Cert_backup.cer
Une fois l'autorisation attribuée, nous créons le certificat et la clé principale à l'aide de la sauvegarde du certificat et de la clé principale créés sur LinuxSQL01.
Pour ce faire, exécutez la commande suivante sur les deux réplicas secondaires :
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'abcd!1234';
CREATE CERTIFICATE AG_Auth_Cert
FROM FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/AG_Auth_Cert_backup.pvk',
DECRYPTION BY PASSWORD = 'abcd!1234'
);
Une fois que nous aurons créé le certificat et la clé principale, nous configurerons les points de mise en miroir de la base de données.
Créer les points de terminaison de mise en miroir
Pour communiquer entre les réplicas principal et secondaire, SQL Server utilise des points de terminaison de mise en miroir.
Un point de terminaison de mise en miroir utilise le protocole TCP/IP pour envoyer et recevoir des messages des réplicas principaux et secondaires et écoute sur un port TCP/IP unique.
Exécutez le script suivant pour créer un point de terminaison sur les nœuds principal et secondaire :
/*Run this script on LinuxSQL01*/
CREATE ENDPOINT [AG_LinuxSQL01]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL01] STATE = STARTED;
/*Run this script on LinuxSQL02*/
CREATE ENDPOINT [AG_LinuxSQL02]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL02] STATE = STARTED;
/*Run this script on LinuxSQL03*/
CREATE ENDPOINT [AG_LinuxSQL03]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Auth_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_LinuxSQL03] STATE = STARTED;
Une fois les points de mise en miroir créés, créons un groupe de disponibilité.
Créer un groupe de disponibilité
Nous allons configurer AlwaysON à l'aide de SQL Server Management Studio.
Tout d'abord, lancez-le et connectez-vous à l'instance LinuxSQL01 en utilisant sa crédits. Une fois connecté à l'instance SQL Server, cliquez avec le bouton droit sur Toujours en haute disponibilité et sélectionnez l'assistant Nouveau groupe de disponibilité .
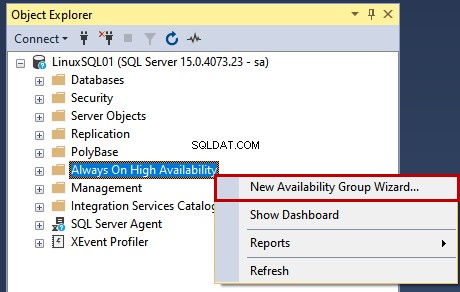
L'assistant de groupe de disponibilité démarre.
1. Présentation
Dans une Introduction , consultez la liste des tâches qui seront exécutées par l'assistant de groupe de disponibilité. Cliquez sur Suivant.
2. Spécifiez l'option de groupe de disponibilité
Sur l'écran Spécifier l'option de groupe de disponibilité, indiquez le nom du groupe de disponibilité souhaité et choisissez EXTERNE du type de cluster menu déroulant.
Cochez également la case Détection de l'intégrité au niveau de la base de données case à cocher. Il permet la session d'événement prolongée pour la disponibilité de la santé de groupe.
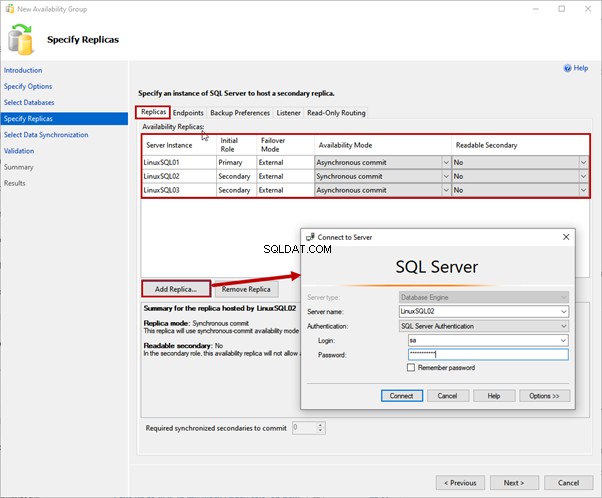
3. Sélectionner des bases de données
Vous pouvez choisir la base de données à ajouter au groupe de disponibilité sur Sélectionner des bases de données filtrer. Remarque :La base de données doit répondre aux prérequis suivants :
- La base de données doit être dans le modèle de récupération COMPLET.
- Une sauvegarde COMPLÈTE de la base de données doit être créée.
J'ai restauré une sauvegarde des WideWorldImportors base de données sur le réplica principal. La base de données est en COMPLET modèle de récupération et une sauvegarde complète a été générée.
Sélectionnez les WideWorldImportors base de données dans la liste et cliquez sur Suivant .
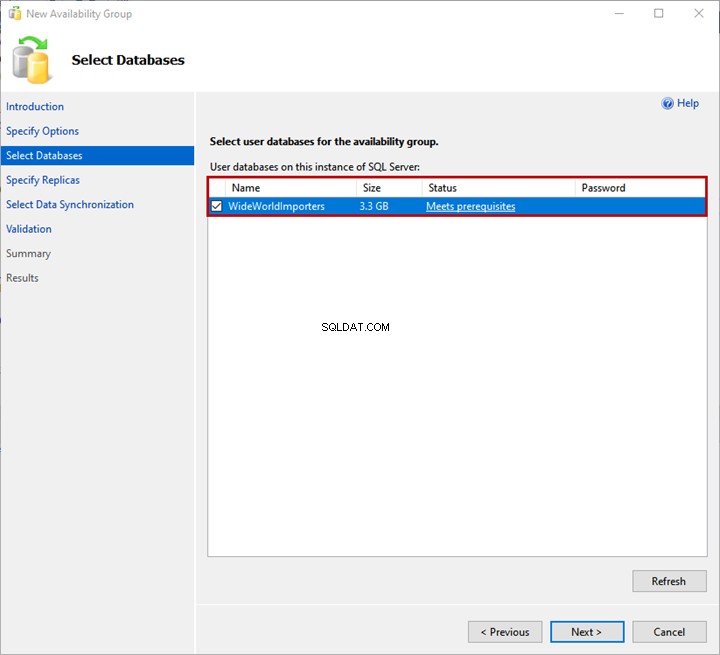
4. Spécifier les répliques
Sur l'onglet Spécifier les répliques écran, nous avons plusieurs onglets pour configurer différentes options. Passons-les tous en revue.
Onglet Réplicas
Ici, nous spécifions les répliques principales et secondaires, le mode de disponibilité et les modes de basculement.
Nous utilisons LinuxSQL01 en tant que réplica principal. LinuxSQL02 et LinuxSQL03 sont un réplica secondaire.
Le mode de disponibilité pour LinuxSQL02 sera Commit synchrone , et pour LinuxSQL03 sera Commit asynchrone .
Pour ajouter le réplica, cliquez sur Ajouter un réplica . Ensuite, sur Se connecter au serveur boîte de dialogue, spécifiez le nom du serveur et les détails de connexion SQL pour se connecter à l'instance :
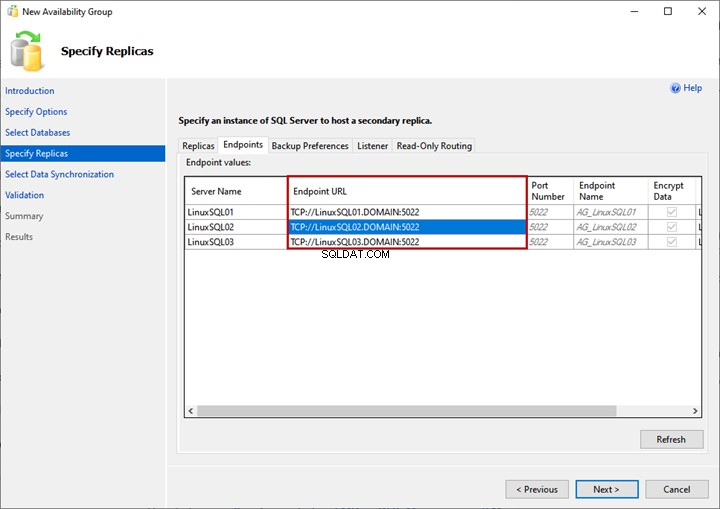
Onglet Points de terminaison
Ici, nous pouvons afficher la liste des répliques et leurs points de terminaison de mise en miroir avec les numéros de port et les noms correspondants :
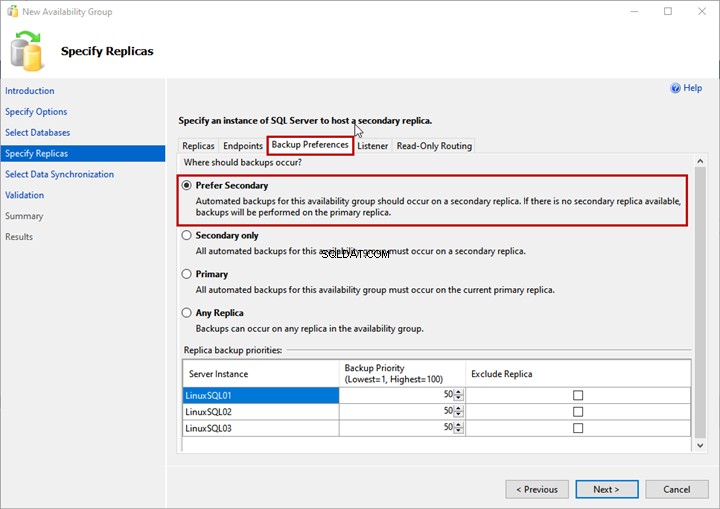
Préférences de sauvegarde
Ici, vous spécifiez la réplique que vous souhaitez utiliser pour générer la sauvegarde. Cette option est utile lorsque vous souhaitez décharger le processus de sauvegarde de la base de données SQL au sein du groupe de disponibilité.
Vous pouvez choisir l'une des options suivantes :
- Préférer le secondaire :la sauvegarde sera générée sur le réplica secondaire. Si le réplica secondaire n'est pas disponible, la sauvegarde sera générée sur le réplica principal.
- Secondaire uniquement :toutes les sauvegardes seront générées sur le réplica secondaire.
- Primaire :les sauvegardes seront générées sur le réplica principal.
- N'importe quel réplica :la sauvegarde sera générée à partir de n'importe quel réplica.
Nous utiliserons le Prefer Secondary choix :
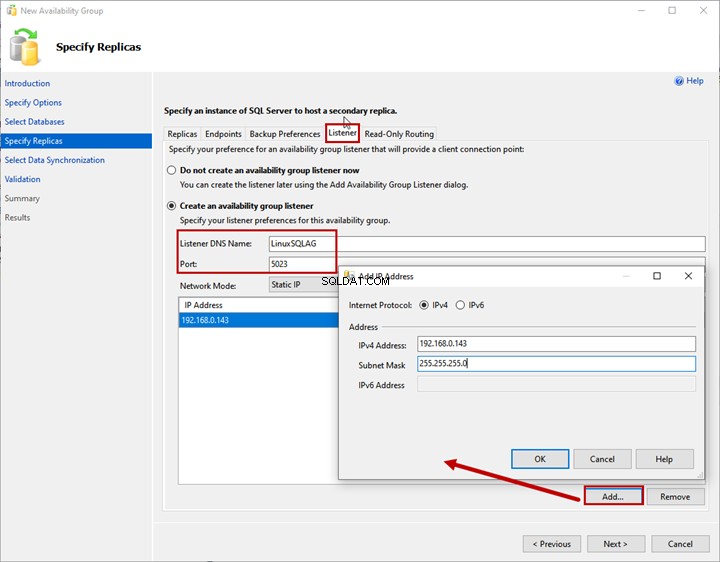
Auditeur
L'écouteur du groupe de disponibilité est un nom virtuel utilisé par une application pour connecter les bases de données du groupe de disponibilité. Spécifiez le nom DNS de l'écouteur et son port dans Nom DNS de l'écouteur et Port zones de texte.
Sélectionnez IP statique depuis le mode réseau menu déroulant.
Pour ajouter l'adresse IP de l'écouteur du groupe de disponibilité, cliquez sur Ajouter>Entrez l'adresse IP etMasque de sous-réseau .
Routage en lecture seule
Ici, vous pouvez fournir l'URL de routage en lecture seule et Liste de routage en lecture seule pour les réplicas principaux et secondaires.
Nous ne configurerons pas le routage en lecture seule dans notre démonstration. Par conséquent, cliquez sur Suivant. Pour en savoir plus sur le routage en lecture seule, vous pouvez vous référer à Routage en lecture seule pour un Always On.
Revenons maintenant au processus principal sur lequel nous travaillons.
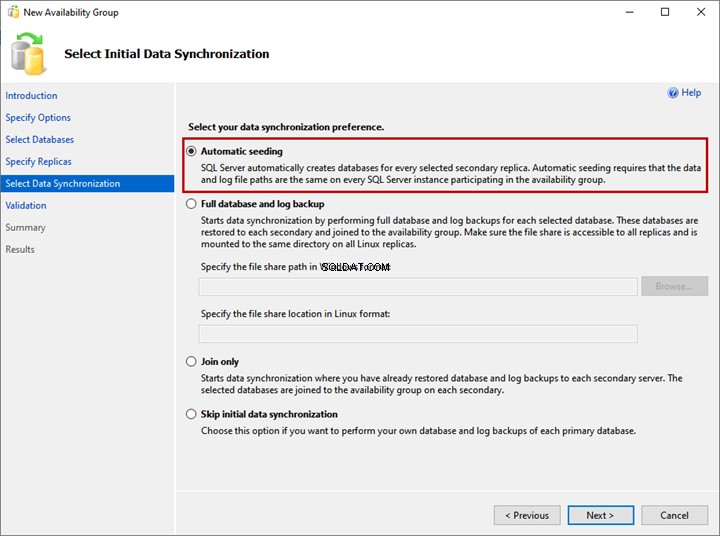
5. Sélectionner la synchronisation initiale des données
Sur le Sélectionner la synchronisation initiale des données l'écran, définissez vos préférences pour la synchronisation initiale des données. Les détails de chaque option sont fournis sur l'écran de l'assistant, et vous pouvez choisir l'une d'entre elles :
- Répartition automatique.
- Sauvegarde complète de la base de données et des journaux.
- Participer uniquement.
- Ignorer la synchronisation initiale des données.
Je n'ai pas créé les WideWorldImportors base de données sur les réplicas LinuxSQL02 et LinuxSQL03, en sélectionnant le amorçage automatique option. Il créera la base de données sur les deux répliques et lancera la synchronisation des données. Cliquez sur Suivant.
6. Validation et résumé
Sur la Validation l'écran, l'assistant valide toutes les configurations.
Pour déployer le groupe de disponibilité Always On avec succès, vous devez avoir réussi toutes les validations. S'il y a une erreur, vous devez la résoudre.
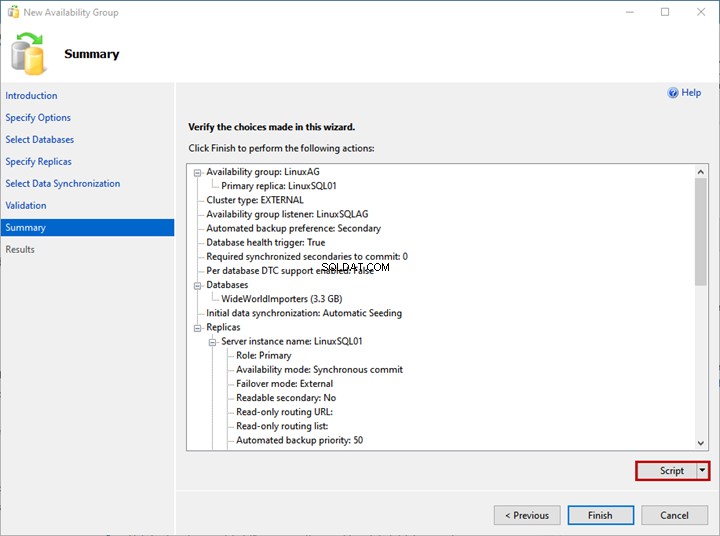
Sur le Résumé écran, vous pouvez voir la liste des configurations choisies pour déployer le groupe de disponibilité.
Vérifiez les détails une fois de plus, puis cliquez sur Terminer – il lance le processus de déploiement.
Si vous souhaitez générer le script du processus de déploiement, cliquez sur Script .
Comme nous le voyons, le processus de déploiement AlwaysOn démarre. Une fois qu'il est terminé avec succès, cliquez sur Fermer pour quitter l'assistant.
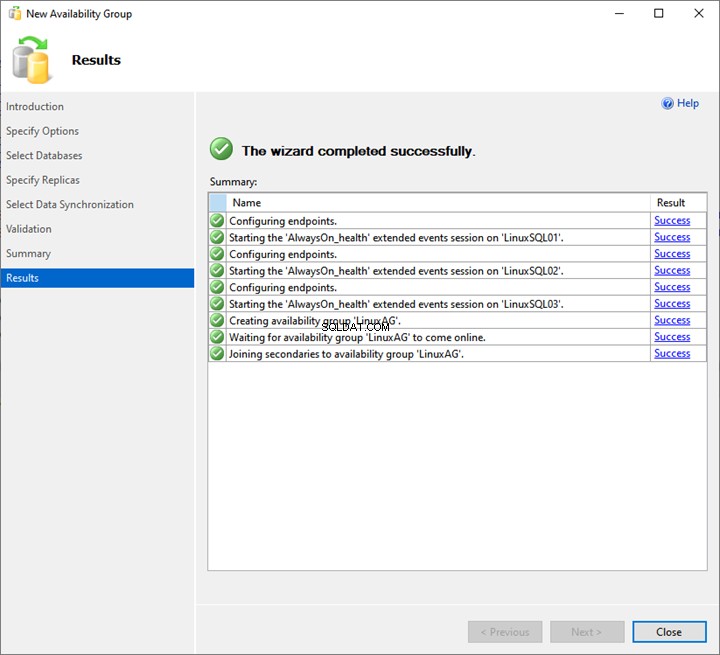
Ainsi, le déploiement du groupe de disponibilité AlwaysOn sur SQL Server 2019 est terminé.
Résumé
Cet article nous aide à comprendre le processus de déploiement étape par étape du groupe de disponibilité SQL Server AlwaysOn sous Linux.
Le prochain article expliquera comment nous pouvons configurer l'écouteur du groupe de disponibilité et effectuer un basculement manuel à l'aide de SQL Server Management Studio. Restez à l'écoute !