Les requêtes doivent être mises en cache dans chaque base de données fortement chargée, il n'y a tout simplement aucun moyen pour une base de données de gérer tout le trafic avec des performances raisonnables. Il existe divers mécanismes dans lesquels un cache de requêtes peut être implémenté. À partir du cache de requêtes MySQL, qui fonctionnait très bien pour la plupart des charges de travail en lecture seule et à faible simultanéité et qui n'a pas sa place dans les charges de travail simultanées élevées (dans la mesure où Oracle l'a supprimé dans MySQL 8.0), aux magasins de clé-valeur externes comme Redis, memcached ou CouchBase.
Le principal problème avec l'utilisation d'un magasin de données dédié externe (car nous ne recommandons à personne d'utiliser le cache de requêtes MySQL) est qu'il s'agit encore d'un autre magasin de données à gérer. C'est encore un autre environnement à maintenir, des problèmes de mise à l'échelle à gérer, des bogues à déboguer, etc.
Alors pourquoi ne pas faire d'une pierre deux coups en utilisant votre proxy ? L'hypothèse ici est que vous utilisez un proxy dans votre environnement de production, car il permet d'équilibrer la charge des requêtes entre les instances et de masquer la topologie de base de données sous-jacente en fournissant un point de terminaison simple aux applications. ProxySQL est un excellent outil pour le travail, car il peut également fonctionner comme une couche de mise en cache. Dans cet article de blog, nous allons vous montrer comment mettre en cache des requêtes dans ProxySQL à l'aide de ClusterControl.
Comment fonctionne le cache de requêtes dans ProxySQL ?
Tout d'abord, un peu de contexte. ProxySQL gère le trafic via des règles de requête et peut effectuer la mise en cache des requêtes en utilisant le même mécanisme. ProxySQL stocke les requêtes mises en cache dans une structure de mémoire. Les données mises en cache sont supprimées à l'aide du paramètre de durée de vie (TTL). Le TTL peut être défini pour chaque règle de requête individuellement, c'est donc à l'utilisateur de décider si les règles de requête doivent être définies pour chaque requête individuelle, avec un TTL distinct ou s'il a juste besoin de créer quelques règles qui correspondront à la majorité des le trafic.
Il existe deux paramètres de configuration qui définissent comment un cache de requêtes doit être utilisé. Tout d'abord, mysql-query_cache_size_MB qui définit une limite souple sur la taille du cache de requête. Ce n'est pas une limite stricte donc ProxySQL peut utiliser un peu plus de mémoire que cela, mais c'est suffisant pour garder l'utilisation de la mémoire sous contrôle. Le deuxième paramètre que vous pouvez modifier est mysql-query_cache_stores_empty_result . Il définit si un jeu de résultats vide est mis en cache ou non.
Le cache de requête ProxySQL est conçu comme un magasin clé-valeur. La valeur est le jeu de résultats d'une requête et la clé est composée de valeurs concaténées telles que :utilisateur, schéma et texte de la requête. Ensuite, un hachage est créé à partir de cette chaîne et ce hachage est utilisé comme clé.
Configuration de ProxySQL en tant que cache de requêtes à l'aide de ClusterControl
Comme configuration initiale, nous avons un cluster de réplication composé d'un maître et d'un esclave. Nous avons également un seul ProxySQL.
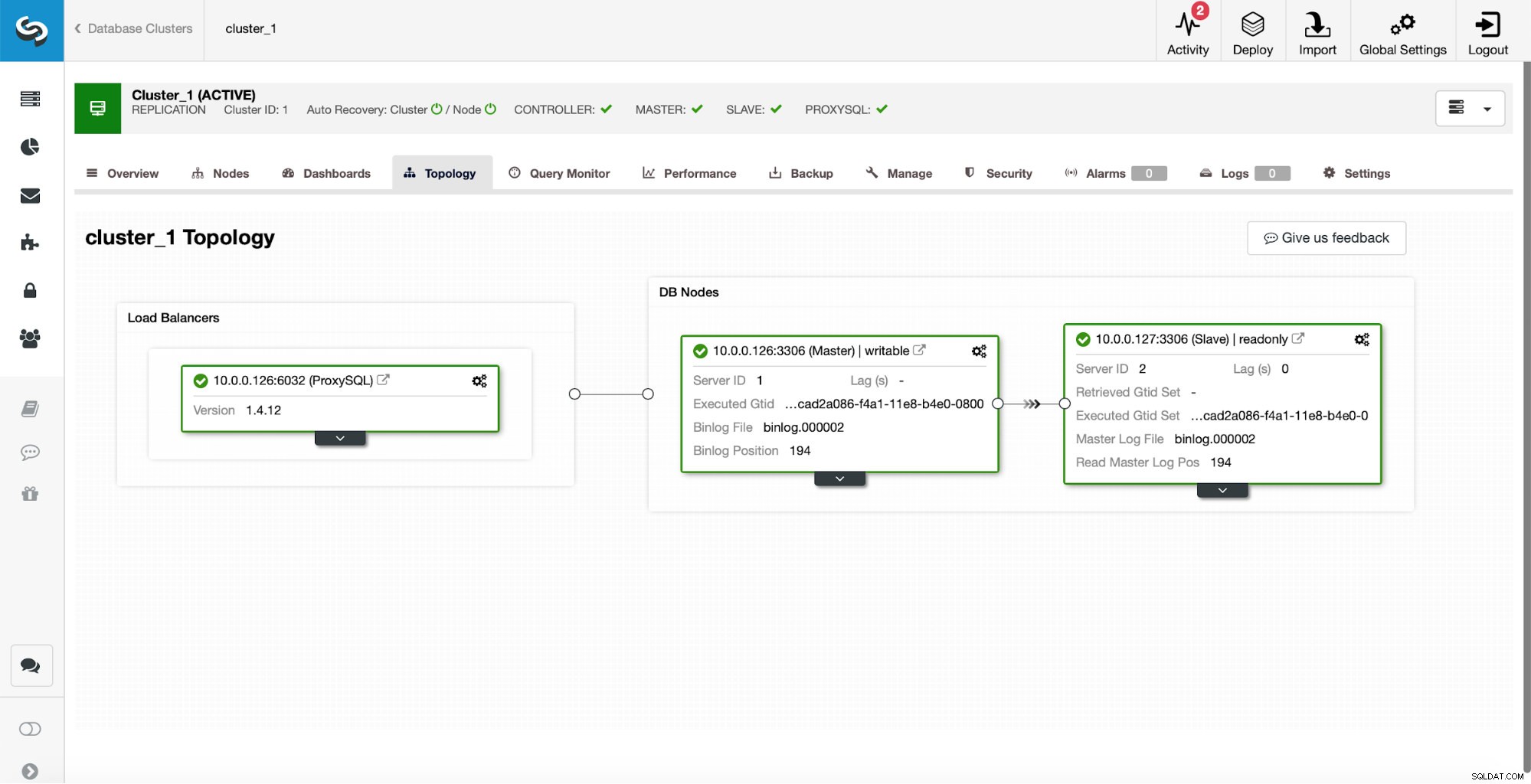
Il ne s'agit en aucun cas d'une configuration de niveau production car nous devrions implémenter une sorte de haute disponibilité pour la couche proxy (par exemple en déployant plus d'une instance ProxySQL, puis en les gardant en vie pour l'IP virtuelle flottante), mais ce sera plus que suffisant pour nos tests.
Tout d'abord, nous allons vérifier la configuration de ProxySQL pour nous assurer que les paramètres du cache de requête sont ce que nous voulons qu'ils soient.
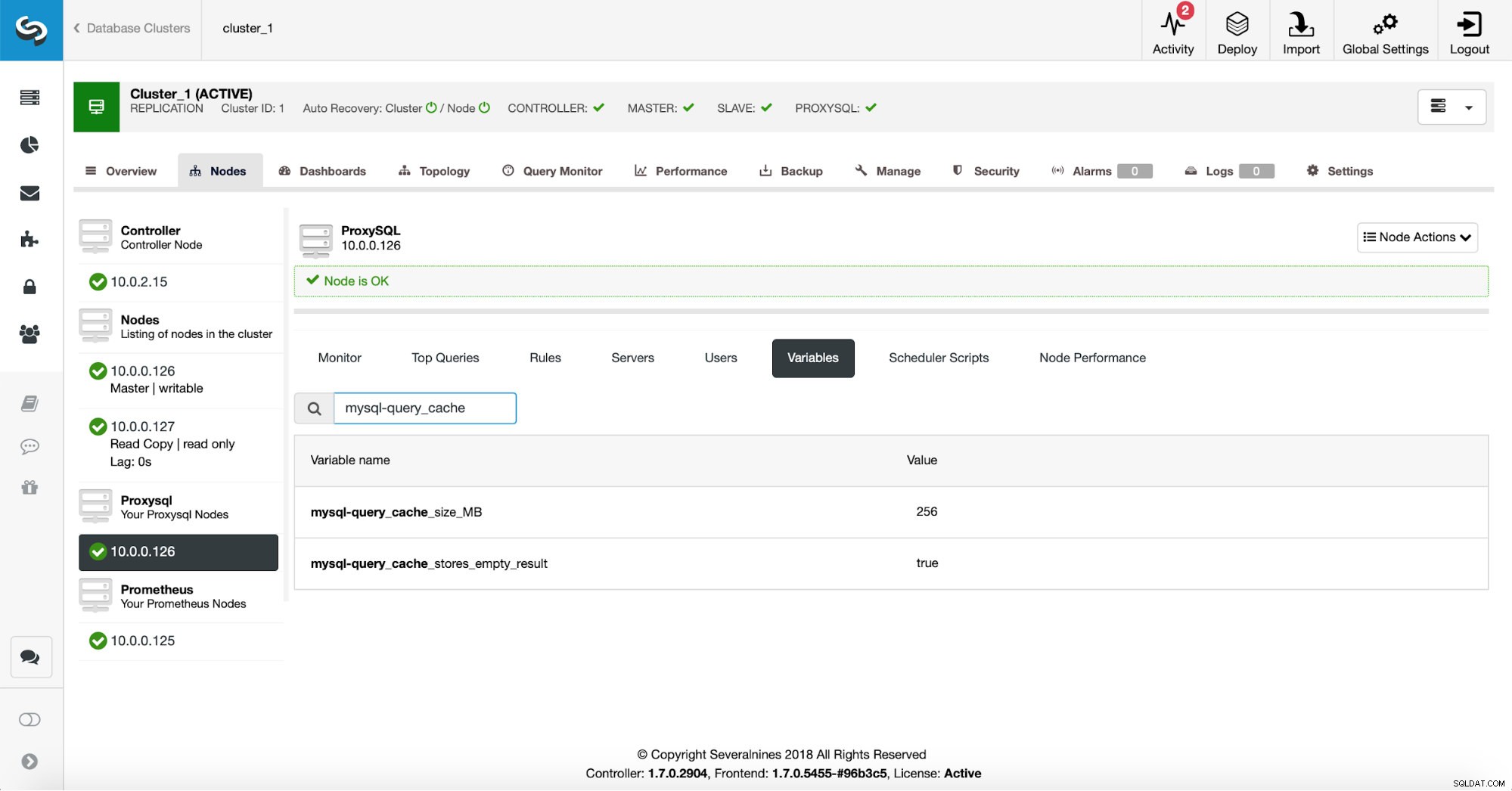
256 Mo de cache de requêtes devraient être à peu près corrects et nous voulons également mettre en cache les ensembles de résultats vides - parfois, une requête qui ne renvoie aucune donnée doit encore faire beaucoup de travail pour vérifier qu'il n'y a rien à renvoyer.
L'étape suivante consiste à créer des règles de requête qui correspondent aux requêtes que vous souhaitez mettre en cache. Il existe deux façons de procéder dans ClusterControl.
Ajout manuel de règles de requête
La première méthode nécessite un peu plus d'actions manuelles. À l'aide de ClusterControl, vous pouvez facilement créer la règle de requête de votre choix, y compris les règles de requête qui effectuent la mise en cache. Voyons d'abord la liste des règles :
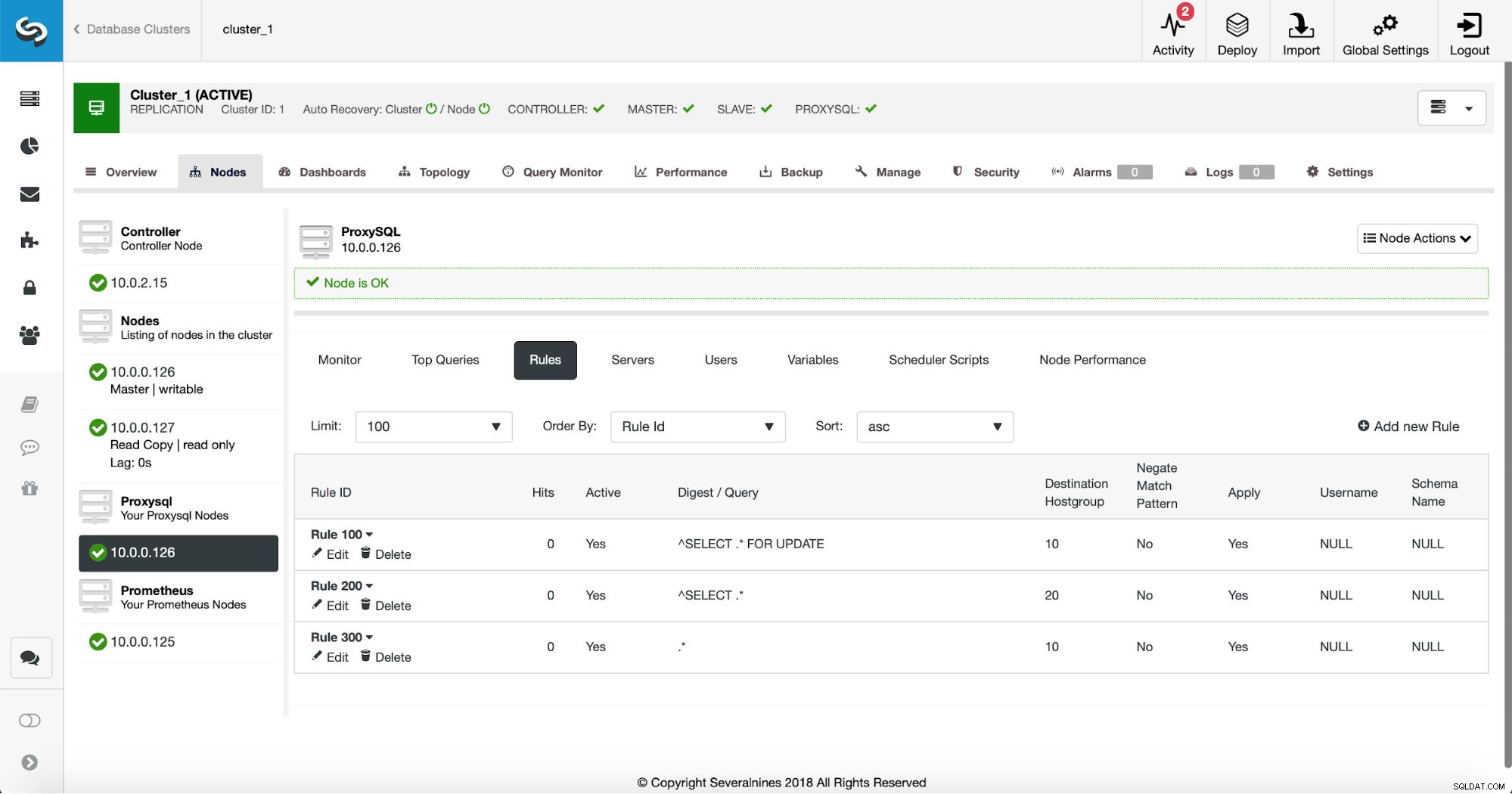
À ce stade, nous avons un ensemble de règles de requête pour effectuer la séparation lecture/écriture. La première règle a un ID de 100. Notre nouvelle règle de requête doit être traitée avant celle-ci, nous utiliserons donc un ID de règle inférieur. Créons une règle de requête qui effectuera la mise en cache des requêtes similaires à celle-ci :
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c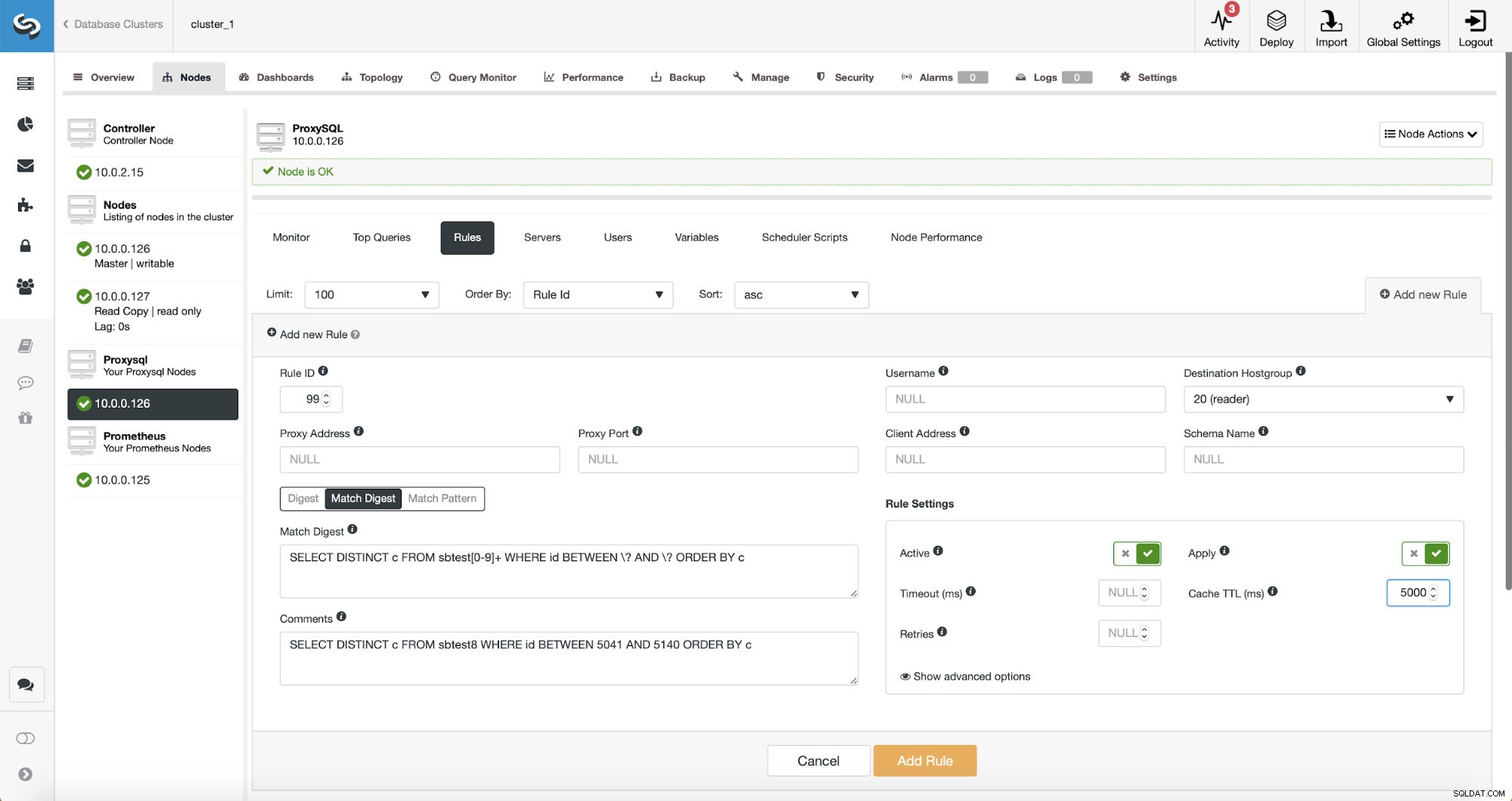
Il existe trois façons de faire correspondre la requête :Digest, Match Digest et Match Pattern. Parlons un peu d'eux ici. Tout d'abord, Match Digest. Nous pouvons définir ici une expression régulière qui correspondra à une chaîne de requête généralisée qui représente un type de requête. Par exemple, pour notre requête :
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cLa représentation générique sera :
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cComme vous pouvez le voir, il a supprimé les arguments de la clause WHERE. Par conséquent, toutes les requêtes de ce type sont représentées sous la forme d'une seule chaîne. Cette option est assez agréable à utiliser car elle correspond à l'ensemble du type de requête et, ce qui est encore plus important, elle supprime tous les espaces. Cela facilite grandement l'écriture d'une expression régulière car vous n'avez pas à tenir compte des sauts de ligne bizarres, des espaces au début ou à la fin de la chaîne, etc.
Digest est essentiellement un hachage que ProxySQL calcule sur le formulaire Match Digest.
Enfin, Match Pattern correspond au texte complet de la requête, tel qu'il a été envoyé par le client. Dans notre cas, la requête aura la forme :
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cNous allons utiliser Match Digest car nous voulons que toutes ces requêtes soient couvertes par la règle de requête. Si nous voulions mettre en cache uniquement cette requête particulière, une bonne option serait d'utiliser Match Pattern.
L'expression régulière que nous utilisons est :
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cNous faisons correspondre littéralement la chaîne de requête généralisée exacte à une exception près :nous savons que cette requête touche plusieurs tables, nous avons donc ajouté une expression régulière pour toutes les correspondre.
Une fois cela fait, nous pouvons voir si la règle de requête est en vigueur ou non.
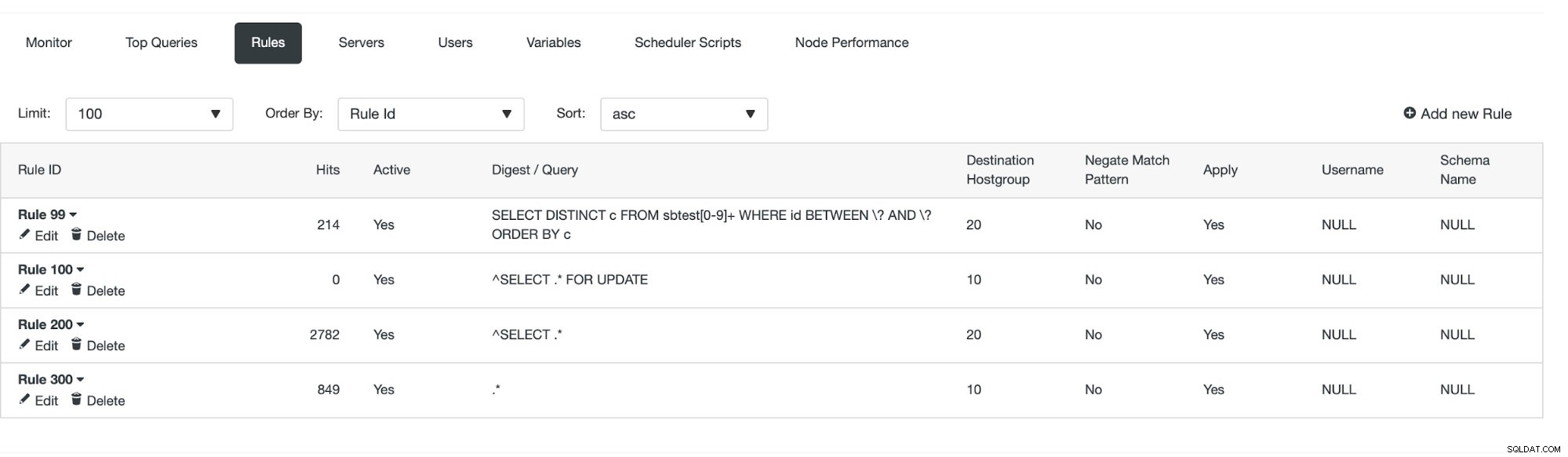
Nous pouvons voir que les "hits" augmentent, ce qui signifie que notre règle de requête est utilisée. Ensuite, nous verrons une autre manière de créer une règle de requête.
Utilisation de ClusterControl pour créer des règles de requête
ProxySQL a une fonctionnalité utile de collecte de statistiques sur les requêtes qu'il a acheminées. Vous pouvez suivre des données telles que le temps d'exécution, le nombre de fois qu'une requête donnée a été exécutée, etc. Ces données sont également présentes dans ClusterControl :
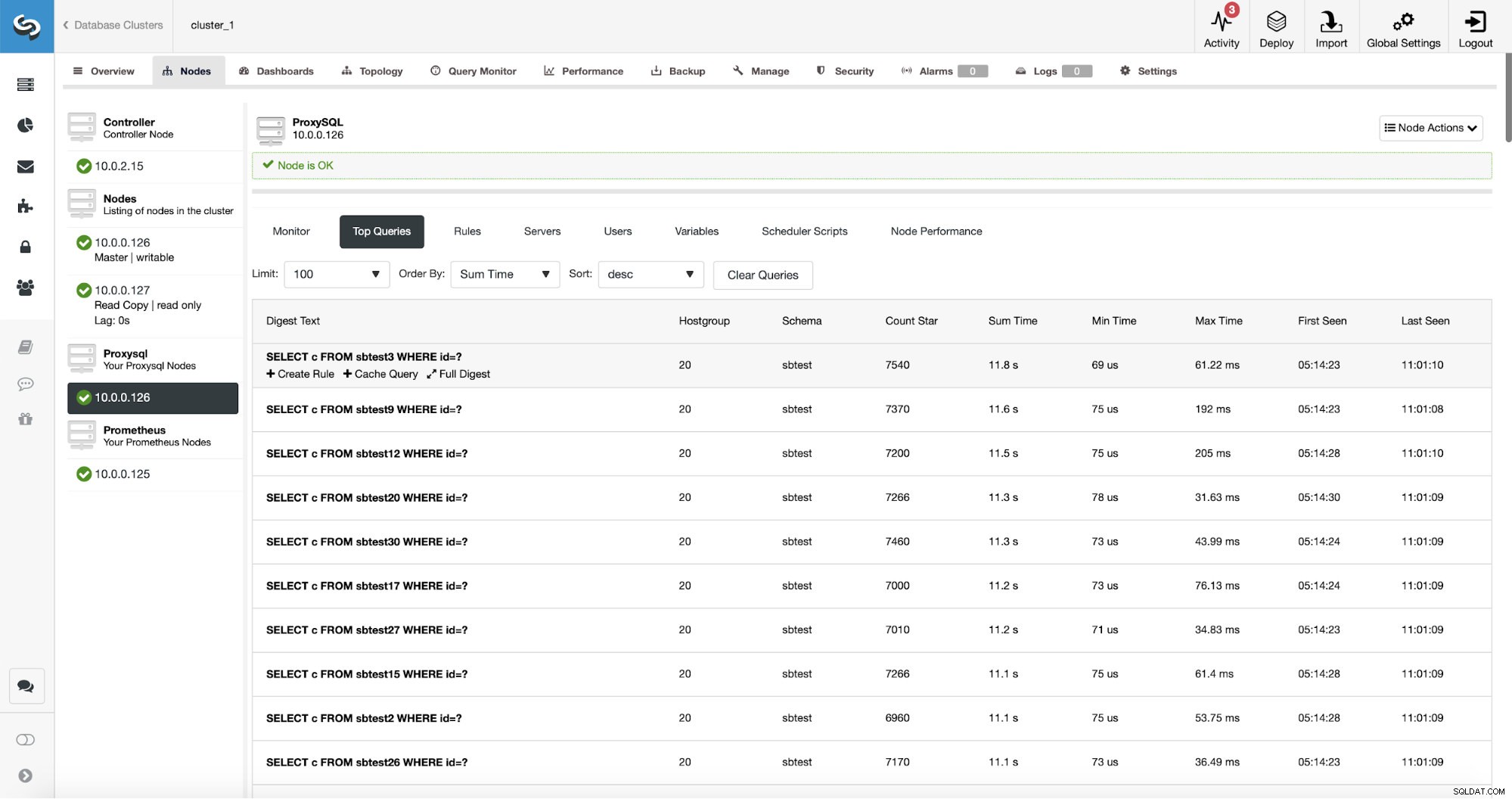
Ce qui est encore mieux, si vous pointez sur un type de requête donné, vous pouvez créer une règle de requête qui lui est associée. Vous pouvez également facilement mettre en cache ce type de requête particulier.
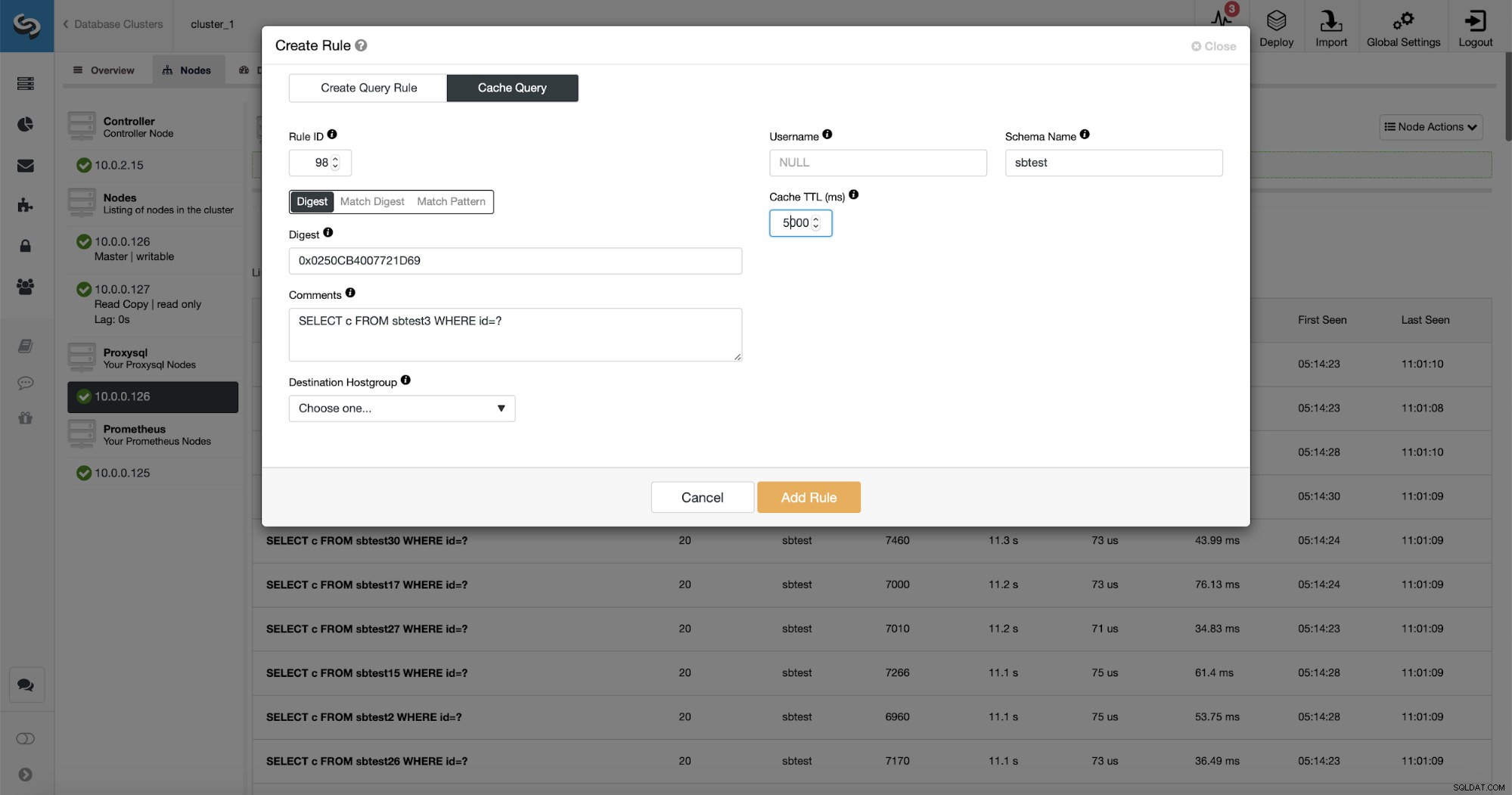
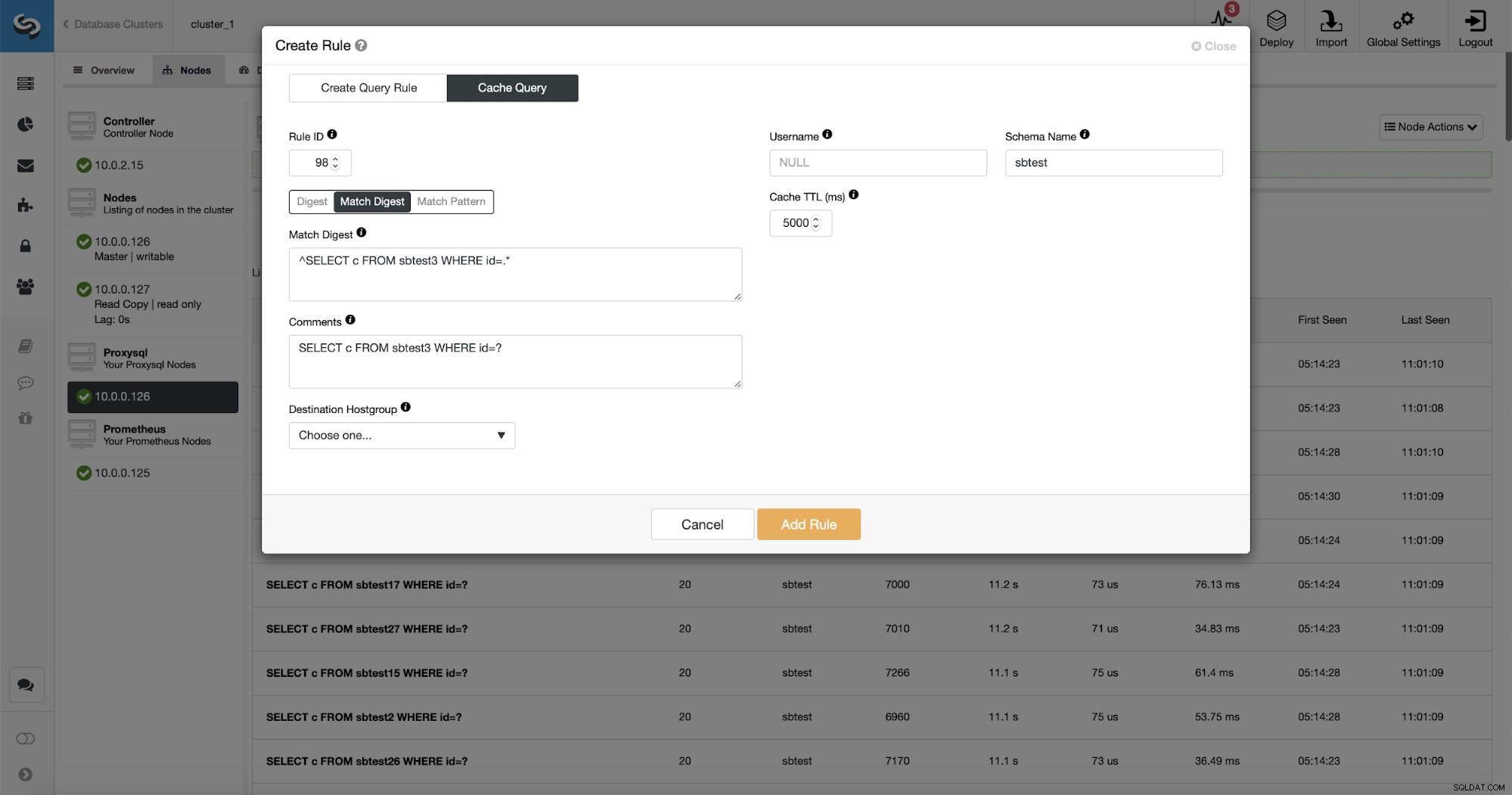
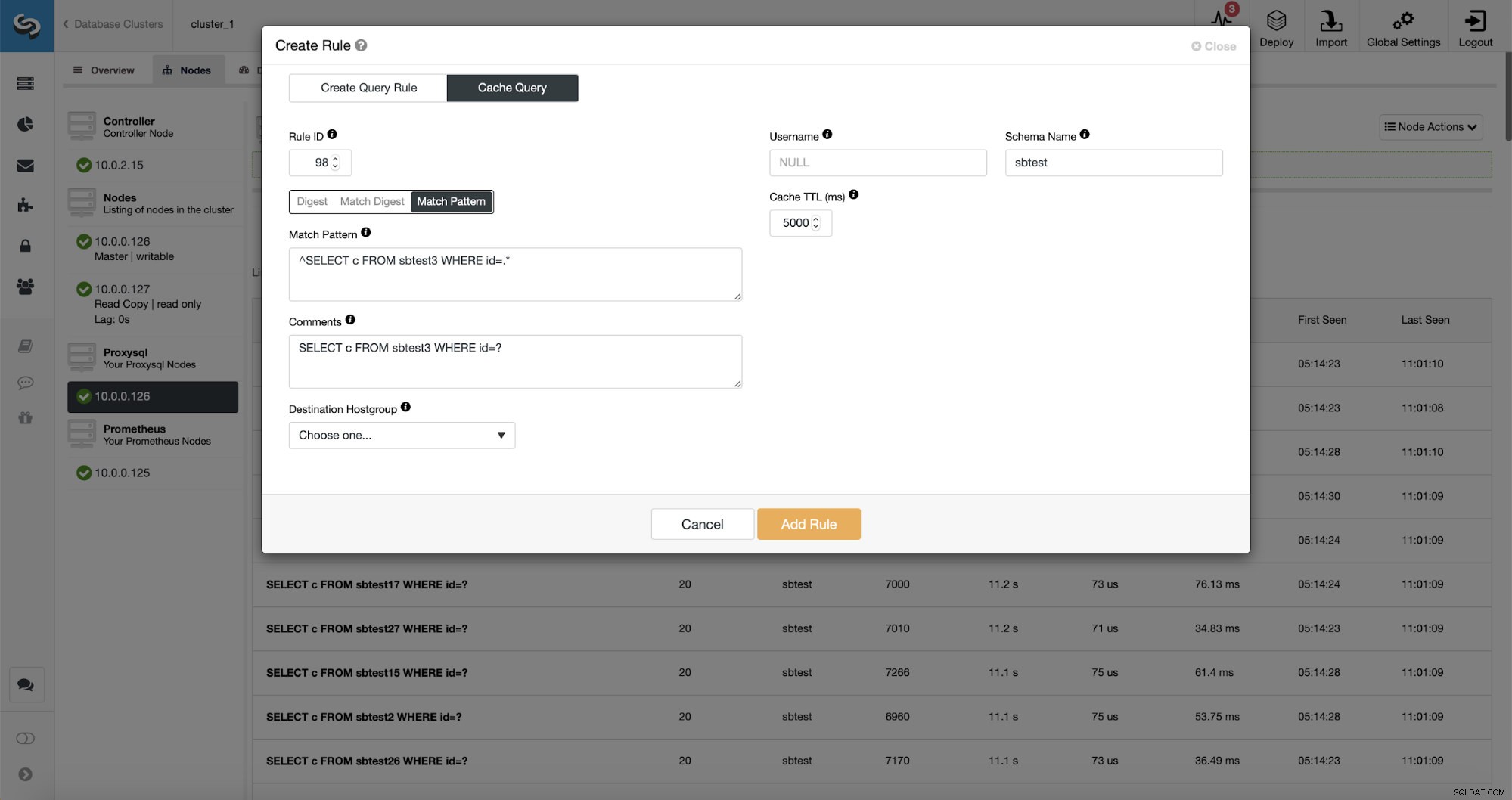
Comme vous pouvez le constater, certaines données telles que Rule IP, Cache TTL ou Schema Name sont déjà renseignées. ClusterControl remplira également les données en fonction du mécanisme de correspondance que vous avez décidé d'utiliser. Nous pouvons facilement utiliser soit le hachage pour un type de requête donné, soit utiliser Match Digest ou Match Pattern si nous souhaitons affiner l'expression régulière (par exemple, en faisant la même chose que précédemment et en étendant l'expression régulière pour correspondre à tous les tables dans le schéma sbtest).
C'est tout ce dont vous avez besoin pour créer facilement des règles de cache de requêtes dans ProxySQL. Téléchargez ClusterControl pour l'essayer dès aujourd'hui.