Nous recevons de bons commentaires concernant notre produit ClusterControl, en particulier sa facilité d'installation et de démarrage. Installer un nouveau logiciel est une chose, mais l'utiliser correctement en est une autre.
Il n'est pas rare d'être impatient de tester un nouveau logiciel et on préfère jouer avec une nouvelle application passionnante plutôt que de lire la documentation avant de se lancer. C'est un peu dommage car vous risquez de manquer des fonctionnalités importantes ou de mal comprendre comment les utiliser.
Cette série de blogs couvre toutes les opérations de base de ClusterControl pour MySQL, MongoDB et PostgreSQL avec des exemples sur la façon de tirer le meilleur parti de votre configuration. Il vous offre une plongée approfondie sur différents sujets pour vous faire gagner du temps.
Voici les sujets abordés dans cette série :
- Déploiement des premiers clusters
- Ajout de votre infrastructure existante
- Surveillance des performances et de l'état
- Rendre vos composants HA
- Gestion des flux de travail
- Protéger vos données
- Protéger vos données
- Cas d'utilisation approfondi
Dans l'article d'aujourd'hui, nous aborderons l'installation de ClusterControl et le déploiement de vos premiers clusters.
Préparatifs
Dans cette série, nous utiliserons un ensemble de boîtiers Vagrant, mais vous pouvez utiliser votre propre infrastructure si vous le souhaitez. Au cas où vous souhaiteriez le tester avec Vagrant, nous avons mis à disposition un exemple de configuration à partir du référentiel Github suivant :https://github.com/severalnines/vagrant
Clonez le dépôt sur votre propre machine :
$ git clone example@sqldat.com:severalnines/vagrant.gitLa topologie des nœuds vagabonds est la suivante :
- vm1 :clustercontrol
- vm2 :nœud de base de données 1
- vm3 :nœud de base de données2
- vm4 :nœud de base de données3
Vous pouvez facilement ajouter des nœuds supplémentaires si vous le souhaitez en modifiant la ligne suivante :
4.times do |n|Le fichier Vagrant est configuré pour installer automatiquement ClusterControl sur le premier nœud et transmettre l'interface utilisateur de ClusterControl au port 8080 sur votre hôte qui exécute Vagrant. Donc, si l'adresse IP de votre hôte est 192.168.1.10, vous trouverez l'interface utilisateur de ClusterControl ici :https://192.168.1.10:8080/clustercontrol/
Installation de ClusterControl
Vous pouvez ignorer cela si vous avez choisi d'utiliser le fichier Vagrant et obtenir l'installation automatique. Mais l'installation de ClusterControl est simple et prendra moins de cinq minutes.
Avec l'installation du package, tout ce que vous avez à faire est d'émettre les trois commandes suivantes sur le nœud ClusterControl pour l'installer :
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userC'est tout :cela ne peut pas être plus facile que cela. Si le script d'installation n'a rencontré aucun problème, ClusterControl doit être installé et opérationnel. Vous pouvez maintenant vous connecter à ClusterControl sur l'URL suivante :https://192.168.1.210/clustercontrol
Après avoir créé un compte administrateur et vous être connecté, vous serez invité à ajouter votre premier cluster.
Déployer un cluster Galera
Vous serez invité à créer un nouveau serveur/cluster de base de données ou à importer un serveur ou un cluster existant (c'est-à-dire déjà déployé) :
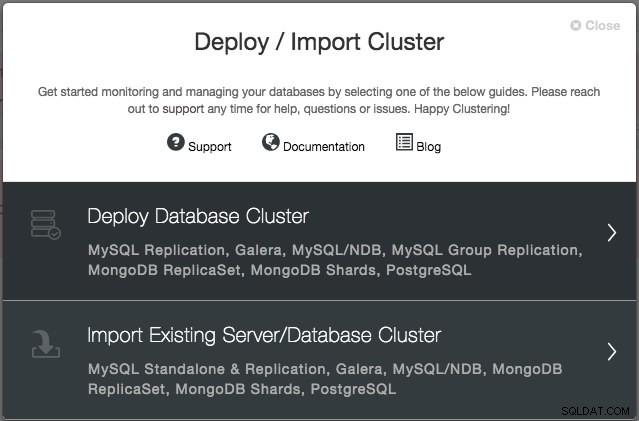
Nous allons déployer un cluster Galera. Deux sections doivent être remplies. Le premier onglet est lié à SSH et aux paramètres généraux :
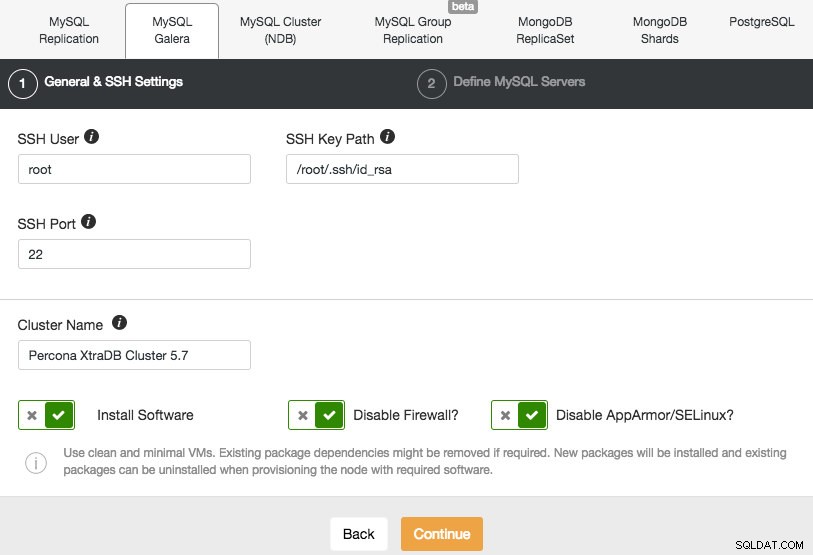
Pour permettre à ClusterControl d'installer les nœuds Galera, nous utilisons l'utilisateur root auquel l'accès SSH a été accordé par les scripts d'amorçage Vagrant. Si vous choisissez d'utiliser votre propre infrastructure, vous devez entrer ici un utilisateur autorisé à effectuer un SSH sans mot de passe sur les nœuds que ClusterControl contrôlera. N'oubliez pas que vous devez au préalable configurer SSH sans mot de passe depuis ClusterControl vers tous les nœuds de la base de données.
Assurez-vous également de désactiver AppArmor/SELinux. Voyez ici pourquoi.
Ensuite, passez à la deuxième étape et spécifiez les informations relatives à la base de données et les hôtes cibles :
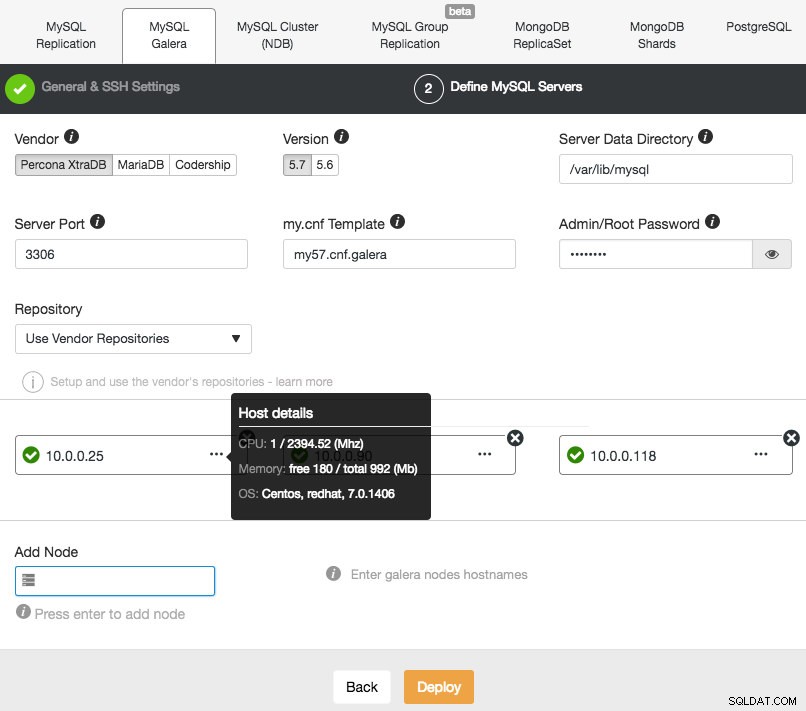
ClusterControl effectuera immédiatement des vérifications d'intégrité chaque fois que vous appuyez sur Entrée lors de l'ajout d'un nœud. Vous pouvez voir le résumé de l'hôte en survolant chaque nœud défini. Une fois que tout est vert, cela signifie que ClusterControl a une connectivité à tous les nœuds, vous pouvez cliquer sur Déployer. Une tâche sera générée pour créer le nouveau cluster. La bonne chose est que vous pouvez suivre l'avancement de ce travail en cliquant sur Activité -> Travaux -> Créer un cluster -> Détails complets du travail :
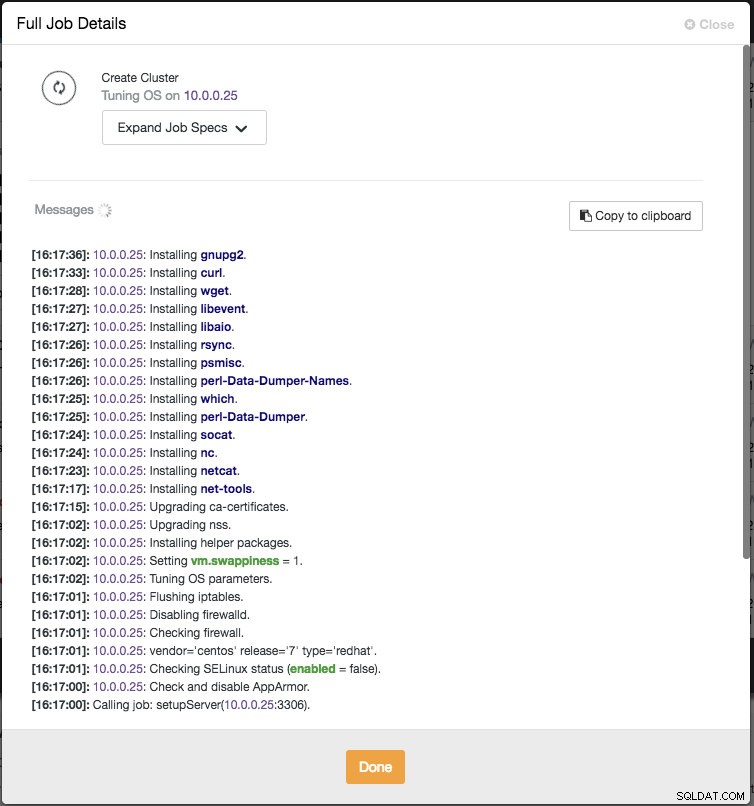
Une fois le travail terminé, vous venez de créer votre premier cluster. L'aperçu du cluster devrait ressembler à ceci :
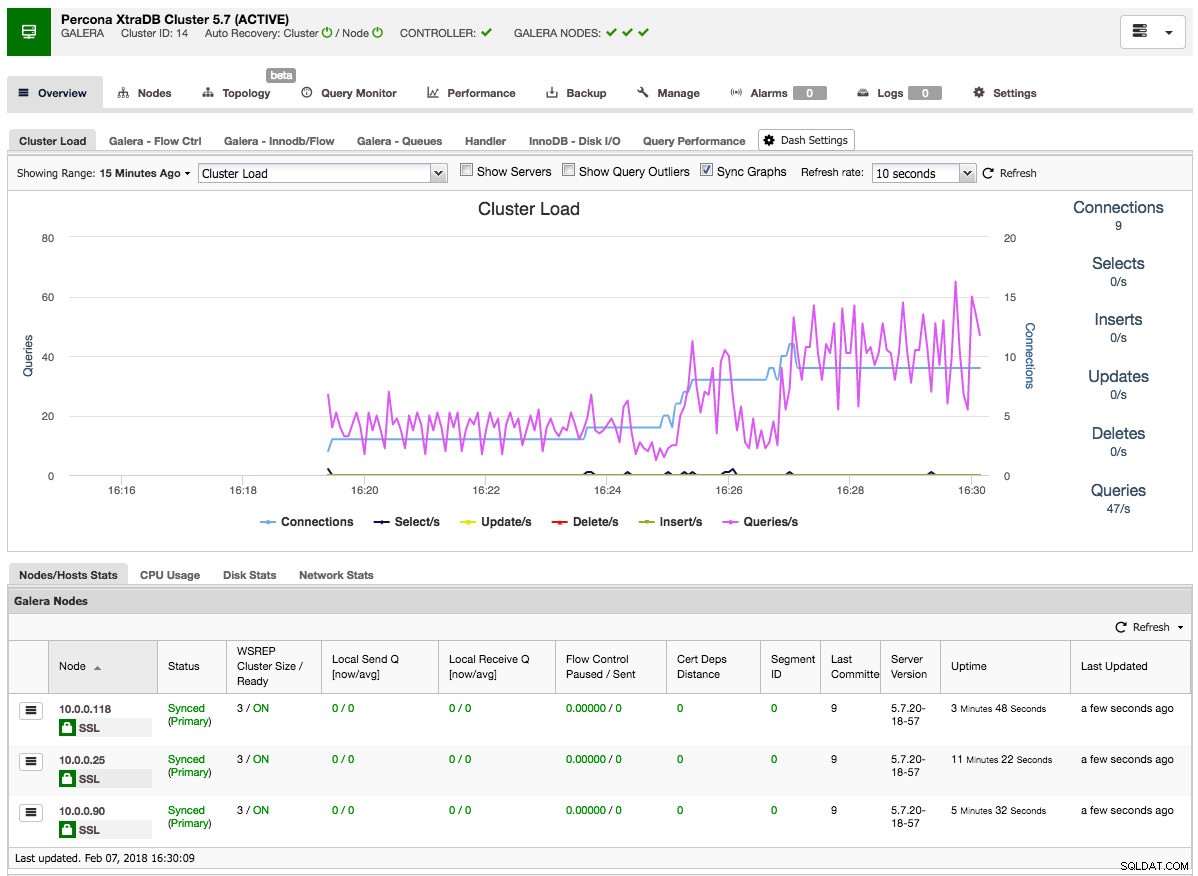
Dans l'onglet nœuds, vous pouvez effectuer toutes les opérations que vous feriez normalement sur un cluster. Le moniteur de requêtes vous donne un bon aperçu des requêtes en cours d'exécution et des requêtes principales. L'onglet Performances vous aidera à surveiller de près les performances de votre cluster et présente également les conseillers qui vous aident à agir de manière proactive sur les tendances des données. L'onglet de sauvegarde vous permet de planifier facilement des sauvegardes et de les stocker sur un stockage local ou cloud. L'onglet Gérer vous permet d'étendre votre cluster ou de le rendre hautement disponible pour vos applications via un équilibreur de charge.
Toutes ces fonctionnalités seront couvertes dans les prochains articles de blog de cette série.
Déployer un cluster de réplication MySQL
Le déploiement d'une configuration de réplication MySQL est similaire au déploiement de la base de données Galera, sauf qu'il comporte un onglet supplémentaire dans la boîte de dialogue de déploiement où vous pouvez définir la topologie de réplication :
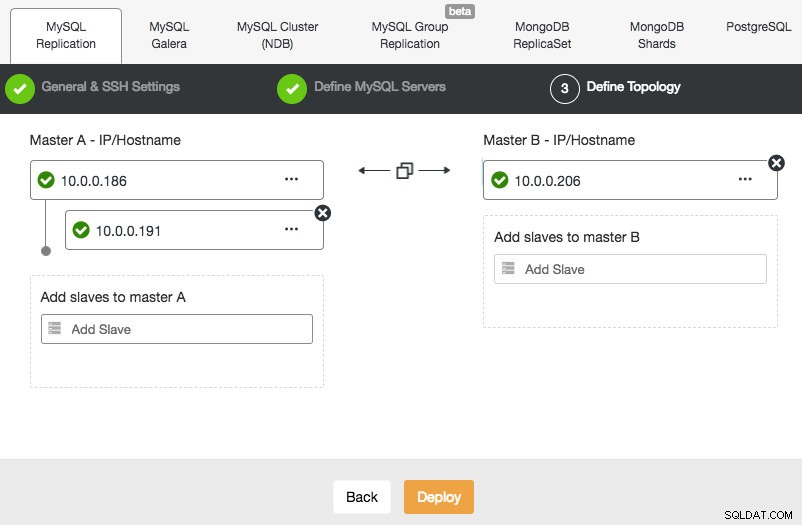
Vous pouvez configurer une réplication maître-esclave standard, ainsi qu'une réplication maître-maître. Dans ce dernier cas, un seul maître restera accessible en écriture à la fois. Gardez à l'esprit que la réplication maître-maître ne s'accompagne pas d'une résolution des conflits et d'une cohérence garantie des données, comme dans le cas de Galera. Utilisez cette configuration avec prudence ou examinez le cluster Galera. Une fois que tout est vert et que vous avez cliqué sur Déployer, une tâche sera générée pour créer le nouveau cluster.
Encore une fois, la progression du déploiement est disponible sous Activité -> Travaux.
Pour faire évoluer l'esclave (copie en lecture), utilisez simplement l'option "Ajouter un nœud" dans la liste des clusters :
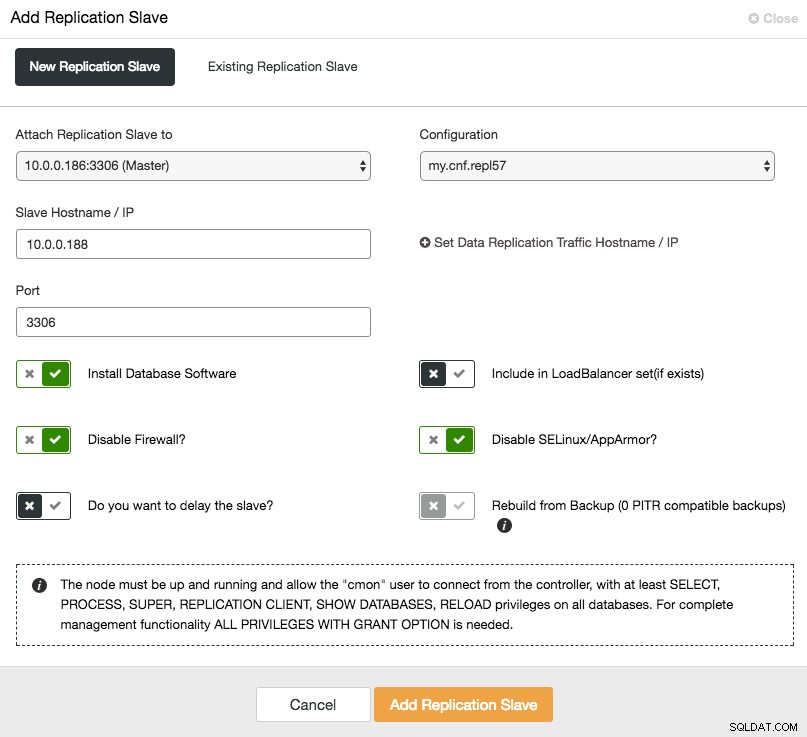
Après avoir ajouté le nœud esclave, ClusterControl fournira à l'esclave une copie des données de son maître à l'aide de Xtrabackup ou de toute sauvegarde compatible PITR existante pour ce cluster.
Déployer la réplication PostgreSQL
ClusterControl prend en charge le déploiement de PostgreSQL version 9.x et supérieure. Les étapes sont similaires avec le déploiement de la réplication MySQL, où à la fin de l'étape de déploiement, vous pouvez définir la topologie de la base de données lors de l'ajout des nœuds :
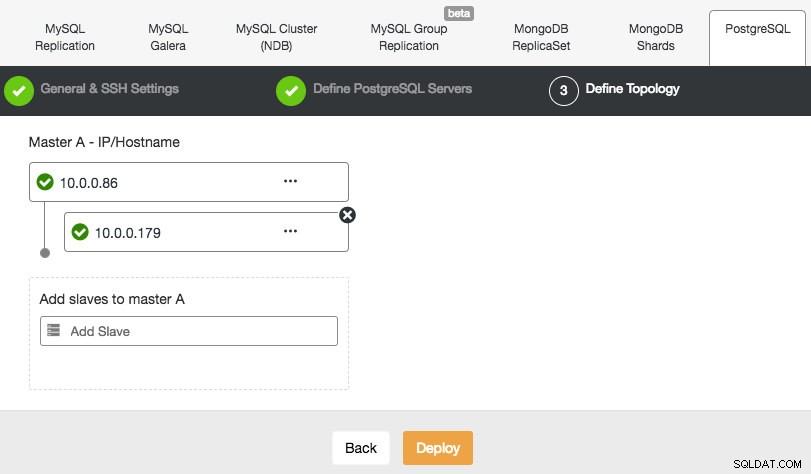
Semblable à la réplication MySQL, une fois le déploiement terminé, vous pouvez évoluer en ajoutant des réplications esclaves au cluster. L'étape est aussi simple que de sélectionner le maître et de renseigner le FQDN du nouvel esclave :
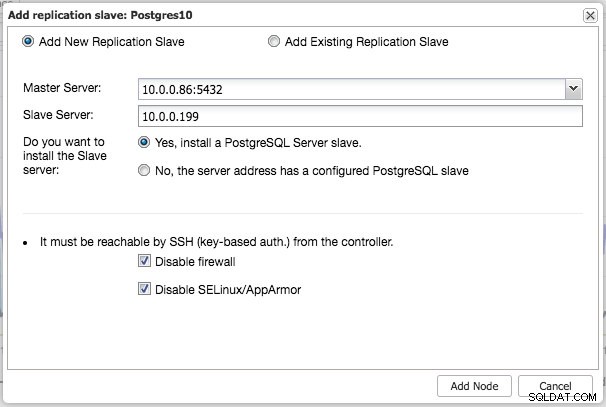
ClusterControl effectuera ensuite le transfert de données nécessaire à partir du maître choisi à l'aide de pg_basebackup, configurera l'utilisateur de réplication et activera la réplication en continu. La vue d'ensemble du cluster PostgreSQL vous donne un aperçu de votre configuration :
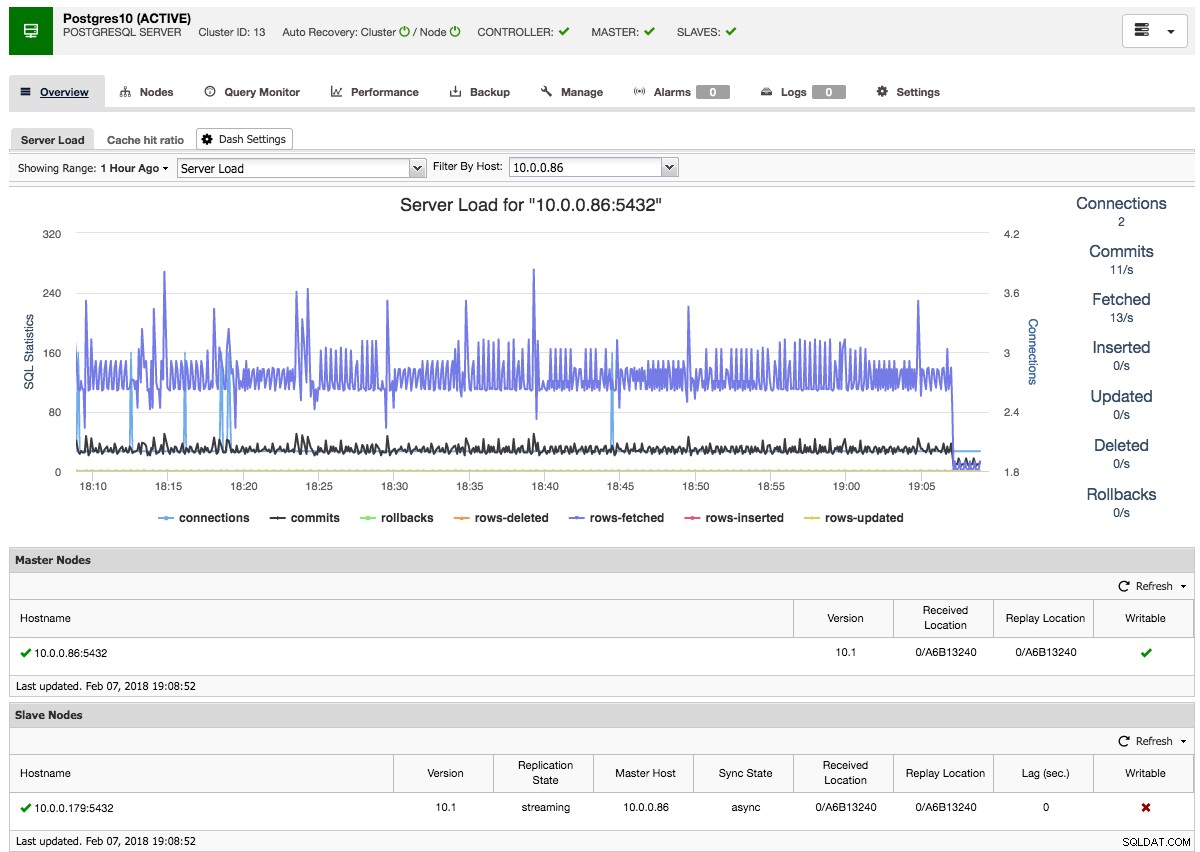
Tout comme avec les aperçus des clusters Galera et MySQL, vous pouvez trouver tous les onglets et fonctions nécessaires ici :le moniteur de requêtes, les performances, les onglets de sauvegarde vous permettent tous d'effectuer les opérations nécessaires.
Déployer un ensemble de répliques MongoDB
Le déploiement d'un nouvel ensemble de répliques MongoDB est similaire aux autres clusters. Dans la boîte de dialogue Déployer le cluster de bases de données, sélectionnez MongoDB ReplicatSet, définissez les options de base de données préférées et ajoutez les nœuds de base de données :
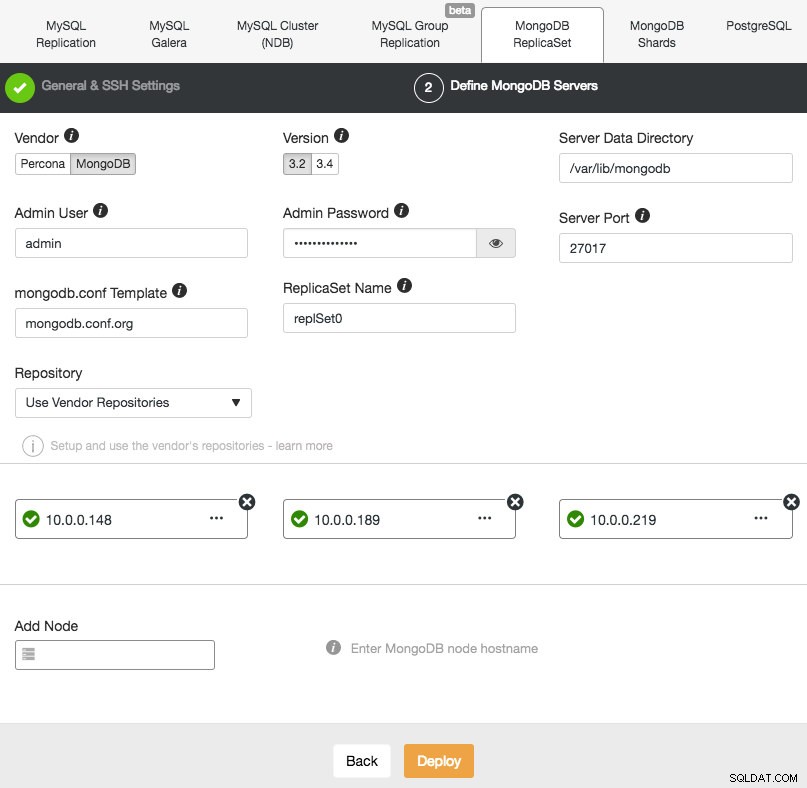
Vous pouvez choisir d'installer Percona Server pour MongoDB de Percona ou MongoDB Server de MongoDB, Inc (anciennement 10gen). Vous devez également spécifier l'utilisateur et le mot de passe administrateur MongoDB car ClusterControl déploiera par défaut un cluster MongoDB avec l'authentification activée.
Après avoir installé le cluster, vous pouvez ajouter un nœud esclave ou arbitre supplémentaire dans le jeu de répliques à l'aide du menu "Ajouter un nœud" sous la même liste déroulante de la vue d'ensemble du cluster :
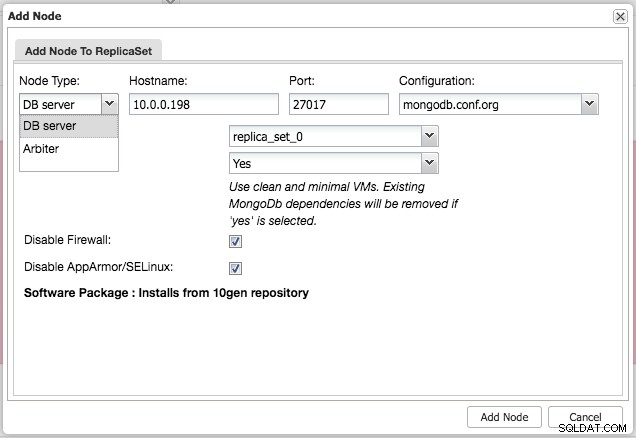
Après avoir ajouté l'esclave ou l'arbitre au jeu de répliques, une tâche sera générée. Une fois ce travail terminé, il faudra un peu de temps avant que MongoDB ne l'ajoute au cluster et qu'il ne devienne visible dans l'aperçu du cluster :
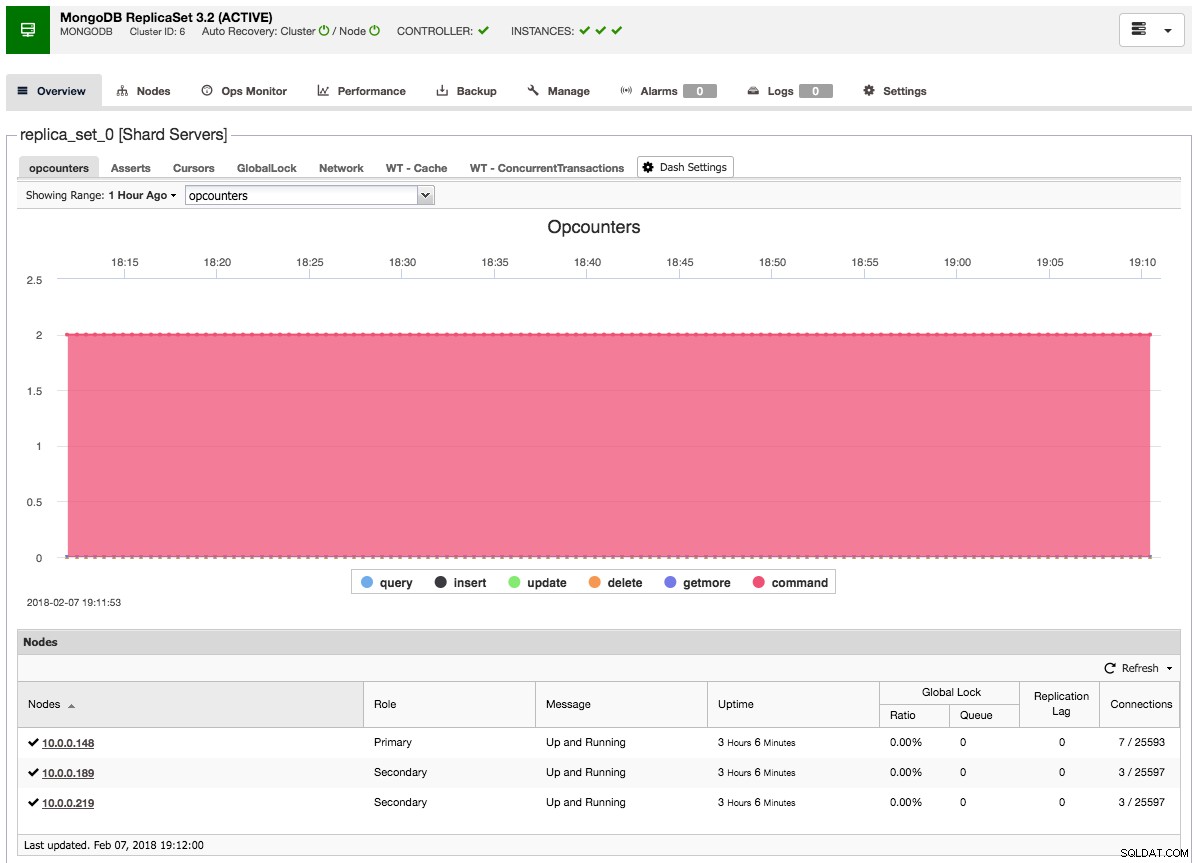
Réflexions finales
Avec ces trois exemples, nous vous avons montré à quel point il est facile de configurer différents clusters à partir de zéro en seulement quelques minutes. La beauté de l'utilisation de cette configuration Vagrant est que, aussi simple que de créer cet environnement, vous pouvez également le supprimer, puis réapparaître. Impressionnez vos collègues en montrant à quelle vitesse vous pouvez configurer un environnement de travail.
Bien sûr, il serait tout aussi intéressant d'ajouter des hôtes existants et des clusters déjà déployés dans ClusterControl, et c'est ce que nous aborderons la prochaine fois.