L'espace disque est une ressource exigeante de nos jours. Vous souhaiterez généralement stocker les données aussi longtemps que possible, mais cela pourrait être un problème si vous ne prenez pas les mesures nécessaires pour éviter un problème potentiel de "manque d'espace disque".
Dans ce blog, nous verrons comment détecter ce problème pour PostgreSQL, le prévenir, et s'il est trop tard, quelques options qui vous aideront probablement à le résoudre.
Comment identifier les problèmes d'espace disque PostgreSQL
Si vous êtes malheureusement dans cette situation de manque d'espace disque, vous pourrez voir quelques erreurs dans les journaux de la base de données PostgreSQL :
2020-02-20 19:18:18.131 UTC [4400] LOG: could not close temporary statistics file "pg_stat_tmp/global.tmp": No space left on deviceou même dans votre journal système :
Feb 20 19:29:26 blog-pg1 rsyslogd: imjournal: fclose() failed for path: '/var/lib/rsyslog/imjournal.state.tmp': No space left on device [v8.24.0-41.el7_7.2 try https://www.rsyslog.com/e/2027 ]PostgreSQL peut continuer à fonctionner pendant un certain temps en exécutant des requêtes en lecture seule, mais finalement, il échouera en essayant d'écrire sur le disque, alors vous verrez quelque chose comme ceci dans votre session client :
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.Ensuite, si vous regardez l'espace disque, vous aurez cette sortie indésirable…
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-vm--125--disk--0 30G 30G 0 100% /Comment éviter les problèmes d'espace disque PostgreSQL
Le principal moyen d'éviter ce type de problème consiste à surveiller l'utilisation de l'espace disque et la croissance de l'utilisation de la base de données ou du disque. Pour cela, un graphique devrait être un moyen convivial de surveiller l'augmentation de l'espace disque :

Et pareil pour la croissance de la base de données :
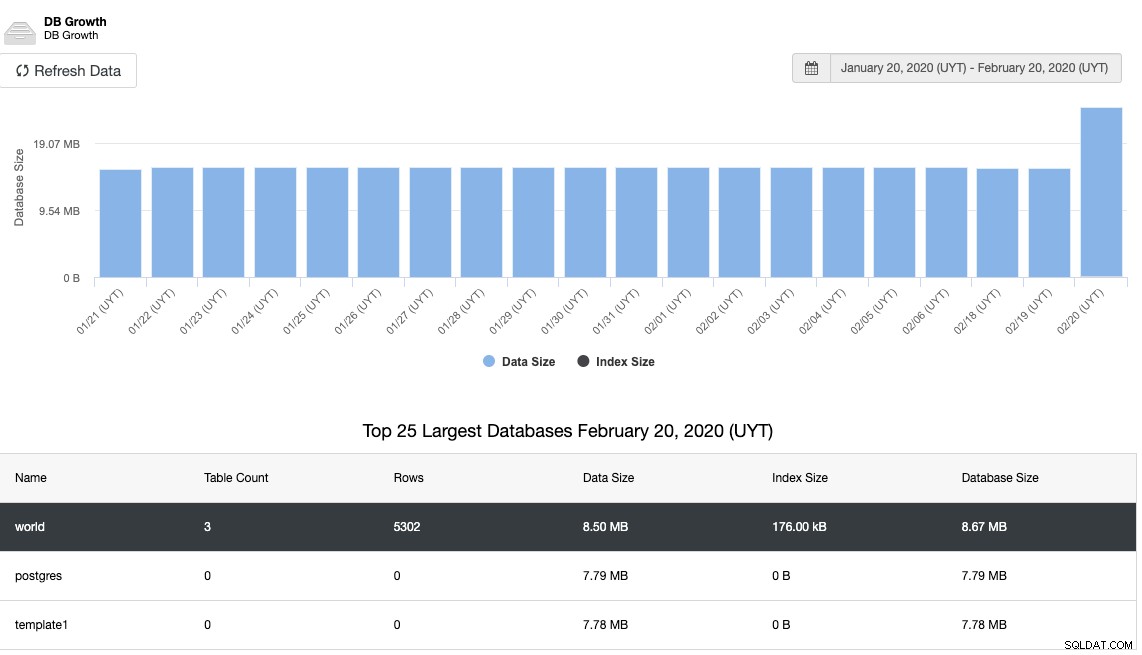
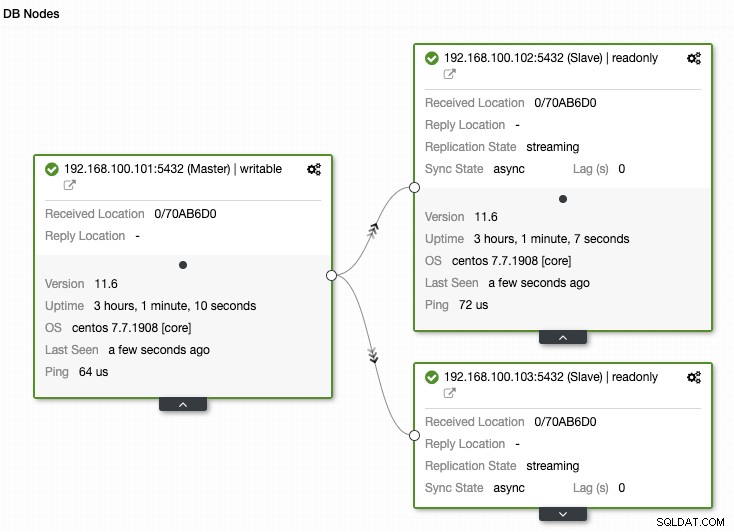
Une autre chose importante à surveiller est l'état de la réplication. Si vous avez une réplique et que, pour une raison quelconque, cela cesse de fonctionner, selon la configuration, il est possible que PostgreSQL stocke tous les fichiers WAL pour restaurer la réplique lorsqu'elle revient.
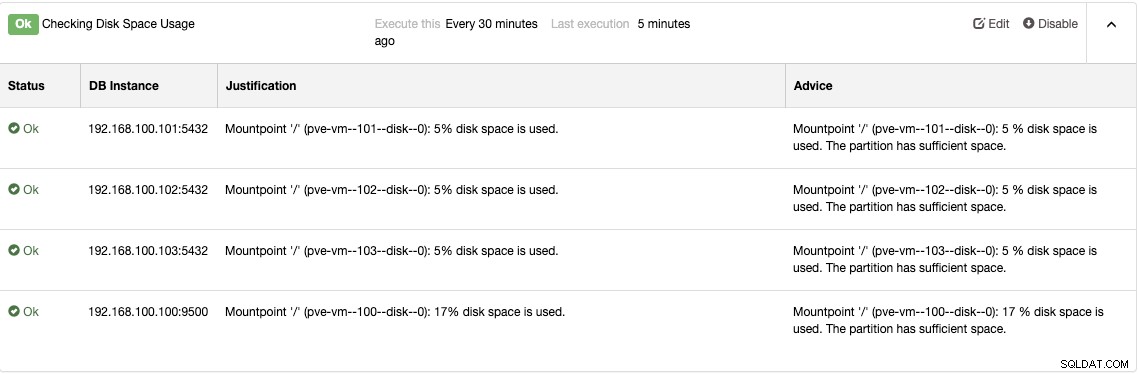
Tout ce système de surveillance n'a pas de sens sans un système d'alerte pour savoir lorsque vous devez prendre des mesures :
Comment résoudre les problèmes d'espace disque PostgreSQL
Eh bien, si vous rencontrez ce problème de manque d'espace disque même avec le système de surveillance et d'alerte implémenté (ou non), il existe de nombreuses options pour essayer de résoudre ce problème sans perte de données (ou moins que possible).
Qu'est-ce qui consomme votre espace disque ?
La première étape devrait être de déterminer où se trouve mon espace disque. Une bonne pratique consiste à avoir des partitions séparées, au moins une partition séparée pour le stockage de votre base de données, afin que vous puissiez facilement vérifier si votre base de données ou votre système utilise un espace disque excessif. Un autre avantage est de minimiser les dégâts. Si votre partition racine est pleine, votre base de données peut toujours écrire dans sa propre partition sans problème.
Utilisation de l'espace de la base de données
Voyons maintenant quelques commandes utiles pour vérifier l'utilisation de l'espace disque de votre base de données.
Un moyen simple de vérifier l'utilisation de l'espace de la base de données consiste à vérifier le répertoire de données dans le système de fichiers :
$ du -sh /var/lib/pgsql/11/data/
819M /var/lib/pgsql/11/data/Ou si vous avez une partition séparée pour votre répertoire de données, vous pouvez utiliser df -h directement.
La commande PostgreSQL "\l+" liste les bases de données en ajoutant les informations de taille :
$ postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace
| Description
-----------+----------+-----------+---------+-------+-----------------------+---------+------------
+--------------------------------------------
postgres | postgres | SQL_ASCII | C | C | | 7965 kB | pg_default
| default administrative connection database
template0 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| unmodifiable empty database
| | | | | postgres=CTc/postgres | |
|
template1 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| default template for new databases
| | | | | postgres=CTc/postgres | |
|
world | postgres | SQL_ASCII | C | C | | 8629 kB | pg_default
|
(4 rows)En utilisant pg_database_size et le nom de la base de données, vous pouvez voir la taille de la base :
postgres=# SELECT pg_database_size('world');
pg_database_size
------------------
8835743
(1 row)Et utiliser pg_size_pretty pour voir cette valeur d'une manière lisible par l'homme pourrait être encore mieux :
postgres=# SELECT pg_size_pretty(pg_database_size('world'));
pg_size_pretty
----------------
8629 kB
(1 row)Lorsque vous savez où se trouve l'espace, vous pouvez prendre les mesures correspondantes pour le réparer. Gardez à l'esprit qu'il ne suffit pas de supprimer des lignes pour récupérer de l'espace disque, vous devrez exécuter un VACUUM ou un VACUUM FULL pour terminer la tâche.
Fichiers journaux
Le moyen le plus simple de récupérer de l'espace disque consiste à supprimer les fichiers journaux. Vous pouvez consulter le répertoire des journaux PostgreSQL ou même les journaux système pour vérifier si vous pouvez gagner de l'espace à partir de là. Si vous avez quelque chose comme ça :
$ du -sh /var/lib/pgsql/11/data/log/
18G /var/lib/pgsql/11/data/log/Vous devriez vérifier le contenu du répertoire pour voir s'il y a un problème de rotation/rétention des journaux ou si quelque chose se passe dans votre base de données et l'écrit dans les journaux.
$ ls -lah /var/lib/pgsql/11/data/log/
total 18G
drwx------ 2 postgres postgres 4.0K Feb 21 00:00 .
drwx------ 21 postgres postgres 4.0K Feb 21 00:00 ..
-rw------- 1 postgres postgres 18G Feb 21 14:46 postgresql-Fri.log
-rw------- 1 postgres postgres 9.3K Feb 20 22:52 postgresql-Thu.log
-rw------- 1 postgres postgres 3.3K Feb 19 22:36 postgresql-Wed.logAvant de supprimer les journaux, si vous en avez un énorme, une bonne pratique consiste à conserver les 100 dernières lignes environ, puis à les supprimer. Ainsi, vous pouvez vérifier ce qui se passe après avoir généré de l'espace libre.
$ tail -100 postgresql-Fri.log > /tmp/log_temp.logEt ensuite :
$ cat /dev/null > /var/lib/pgsql/11/data/log/postgresql-Fri.logSi vous le supprimez simplement avec "rm" et que le fichier journal est utilisé par le serveur PostgreSQL (ou un autre service), l'espace ne sera pas libéré, vous devez donc tronquer ce fichier en utilisant ce chat / commande dev/null à la place.
Cette action est uniquement pour PostgreSQL et les fichiers journaux système. Ne supprimez pas le contenu pg_wal ou un autre fichier PostgreSQL car cela pourrait endommager gravement votre base de données.
ballonnement
Dans une opération PostgreSQL normale, les tuples supprimés ou rendus obsolètes par une mise à jour ne sont pas physiquement supprimés de la table ; ils sont présents jusqu'à ce qu'un VACUUM soit effectué. Il est donc nécessaire de faire le VACUUM périodiquement (AUTOVACUUM), en particulier dans les tables fréquemment mises à jour.
Le problème ici est que l'espace n'est pas renvoyé au système d'exploitation en utilisant uniquement VACUUM, il n'est disponible que pour une utilisation dans la même table.
VACUUM FULL réécrit la table dans un nouveau fichier disque, renvoyant l'espace inutilisé au système d'exploitation. Malheureusement, il nécessite un verrou exclusif sur chaque table pendant son exécution.
Vous devriez vérifier les tables pour voir si un processus VACUUM (FULL) est requis.
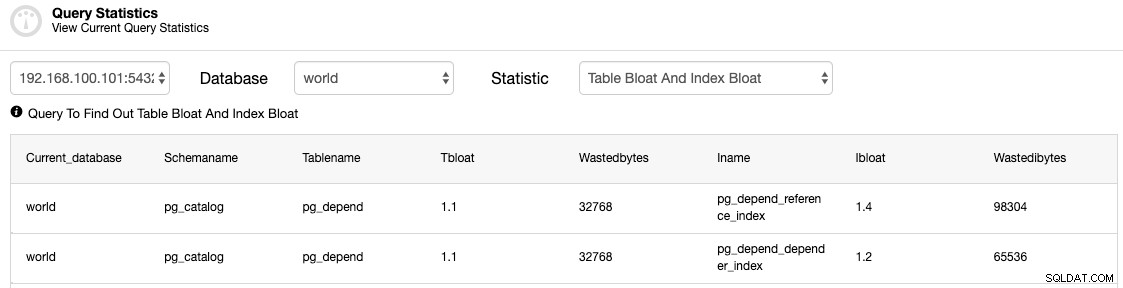
Emplacements de réplication
Si vous utilisez des emplacements de réplication et qu'ils ne sont pas actifs pour une raison quelconque :
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-----------+-----------+--------
slot1 | physical | f
(1 row)Cela pourrait être un problème pour votre espace disque car il stockera les fichiers WAL jusqu'à ce qu'ils aient été reçus par tous les nœuds de secours.
Le moyen de résoudre ce problème consiste à récupérer la réplique (si possible) ou à supprimer l'emplacement :
postgres=# SELECT pg_drop_replication_slot('slot1');
pg_drop_replication_slot
--------------------------
(1 row)Ainsi, l'espace utilisé par les fichiers WAL sera libéré.
Conclusion
Comme nous l'avons mentionné, les systèmes de surveillance et d'alerte sont les clés pour éviter ce genre de problèmes. De cette manière, ClusterControl peut vous aider à faire fonctionner vos systèmes, en vous envoyant des alarmes en cas de besoin ou même en prenant des mesures de récupération pour que votre cluster de base de données continue de fonctionner. Vous pouvez également déployer/importer différentes technologies de base de données et les faire évoluer si nécessaire.



