Dans mon article précédent, j'ai expliqué comment effectuer une sauvegarde logique à l'aide des utilitaires shell mysql. Dans cet article, nous comparerons la vitesse du processus de sauvegarde et de restauration.
Test de vitesse du shell MySQL
Nous allons comparer la vitesse de sauvegarde et de récupération des outils utilitaires mysqldump et MySQL.
Les outils ci-dessous sont utilisés pour la comparaison de vitesse :
- mysqldump
- util.dumpInstance
- util.loadDump
Configuration matérielle
Deux serveurs autonomes avec des configurations identiques.
Serveur 1
* IP :192.168.33.14
* Processeur :2 cœurs
* RAM :4 Go
* DISQUE :SSD de 200 Go
Serveur 2
* IP :192.168.33.15
* Processeur :2 cœurs
* RAM :4 Go
* DISQUE :SSD de 200 Go
Préparation de la charge de travail
Sur le serveur 1 (192.168.33.14), nous avons chargé environ 10 Go de données.
Maintenant, nous voulons restaurer les données du serveur 1 (192.168.33.14) vers le serveur 2 (192.168.33.15).
Configuration MySQL
Version MySQL :8.0.22
Taille du pool de tampons InnoDB :1 Go
Taille du fichier journal InnoDB :16 Mo
Journalisation binaire :activée
Nous avons chargé 50 millions d'enregistrements à l'aide de sysbench.
[example@sqldat.com sysbench]# sysbench oltp_insert.lua --table-size=5000000 --num-threads=8 --rand-type=uniform --db-driver=mysql --mysql-db=sbtest --tables=10 --mysql-user=root --mysql-password=****** prepare
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest3'...
Creating table 'sbtest4'...
Creating table 'sbtest7'...
Creating table 'sbtest1'...
Creating table 'sbtest2'...
Creating table 'sbtest8'...
Creating table 'sbtest5'...
Creating table 'sbtest6'...
Inserting 5000000 records into 'sbtest1'
Inserting 5000000 records into 'sbtest3'
Inserting 5000000 records into 'sbtest7
.
.
.
Creating a secondary index on 'sbtest9'...
Creating a secondary index on 'sbtest10'...Cas de test 1
Dans ce cas, nous allons effectuer une sauvegarde logique à l'aide de la commande mysqldump.
Exemple
[example@sqldat.com vagrant]# time /usr/bin/mysqldump --defaults-file=/etc/my.cnf --flush-privileges --hex-blob --opt --master-data=2 --single-transaction --triggers --routines --events --set-gtid-purged=OFF --all-databases |gzip -6 -c > /home/vagrant/test/mysqldump_schemaanddata.sql.gzstart_time =2020-11-09 17:40:02
end_time =2020-11-09 37:19:08
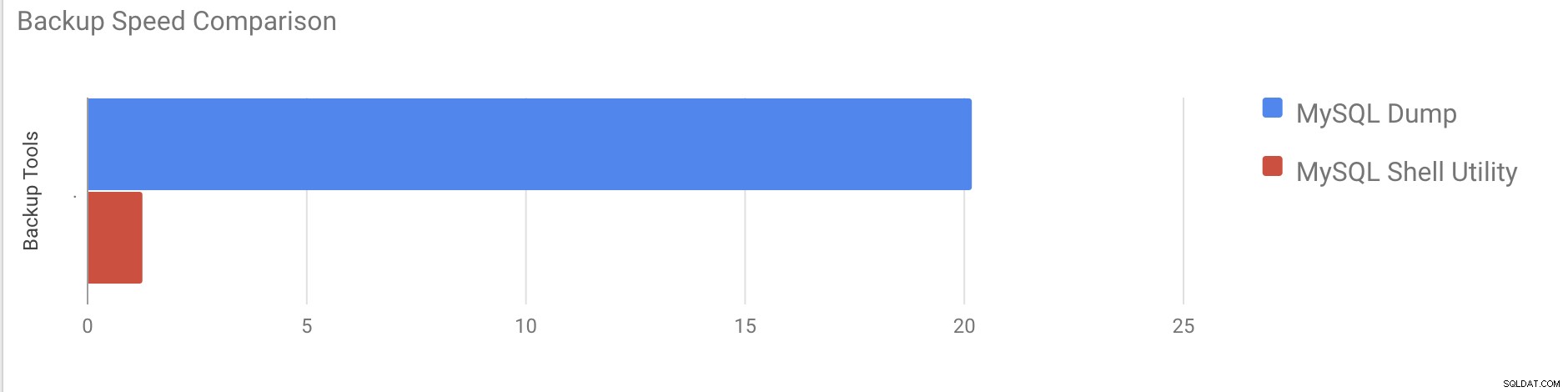
Il a fallu près de 20 minutes et 19 secondes pour effectuer un vidage de toutes les bases de données d'une taille totale d'environ 10 Go.
Cas de test 2
Essayons maintenant avec l'utilitaire shell MySQL. Nous allons utiliser dumpInstance pour effectuer une sauvegarde complète.
Exemple
MySQL localhost:33060+ ssl JS > util.dumpInstance("/home/vagrant/production_backup", {threads: 2, ocimds: true,compatibility: ["strip_restricted_grants"]})
Acquiring global read lock
Global read lock acquired
All transactions have been started
Locking instance for backup
Global read lock has been released
Checking for compatibility with MySQL Database Service 8.0.22
NOTE: Progress information uses estimated values and may not be accurate.
Data dump for table `sbtest`.`sbtest1` will be written to 38 files
Data dump for table `sbtest`.`sbtest10` will be written to 38 files
Data dump for table `sbtest`.`sbtest3` will be written to 38 files
Data dump for table `sbtest`.`sbtest2` will be written to 38 files
Data dump for table `sbtest`.`sbtest4` will be written to 38 files
Data dump for table `sbtest`.`sbtest5` will be written to 38 files
Data dump for table `sbtest`.`sbtest6` will be written to 38 files
Data dump for table `sbtest`.`sbtest7` will be written to 38 files
Data dump for table `sbtest`.`sbtest8` will be written to 38 files
Data dump for table `sbtest`.`sbtest9` will be written to 38 files
2 thds dumping - 36% (17.74M rows / ~48.14M rows), 570.93K rows/s, 111.78 MB/s uncompressed, 50.32 MB/s compressed
1 thds dumping - 100% (50.00M rows / ~48.14M rows), 587.61K rows/s, 115.04 MB/s uncompressed, 51.79 MB/s compressed
Duration: 00:01:27s
Schemas dumped: 3
Tables dumped: 10
Uncompressed data size: 9.78 GB
Compressed data size: 4.41 GB
Compression ratio: 2.2
Rows written: 50000000
Bytes written: 4.41 GB
Average uncompressed throughput: 111.86 MB/s
Average compressed throughput: 50.44 MB/s Il a fallu un total de 1 minute 27 secondes pour effectuer un vidage de l'intégralité de la base de données (les mêmes données que celles utilisées pour mysqldump) et il montre également sa progression, ce qui sera très utile pour savoir quelle partie de la sauvegarde a été effectuée. Il donne le temps qu'il a fallu pour effectuer la sauvegarde.
Le parallélisme dépend du nombre de cœurs du serveur. Augmenter approximativement la valeur ne sera pas utile dans mon cas. (Ma machine a 2 cœurs).
Test de vitesse de restauration
Dans la partie restauration, nous allons restaurer la sauvegarde mysqldump sur un autre serveur autonome. Le fichier de sauvegarde a déjà été déplacé vers le serveur de destination à l'aide de rsync.
Cas de test 1
Exemple
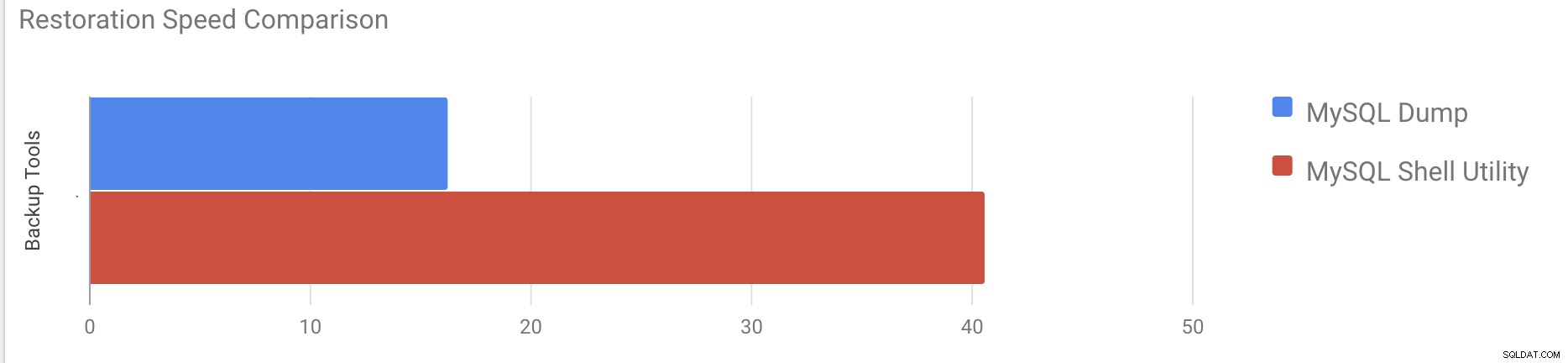
[example@sqldat.com vagrant]#time gunzip < /mnt/mysqldump_schemaanddata.sql.gz | mysql -u root -pIl a fallu environ 16 minutes et 26 secondes pour restaurer les 10 Go de données.
Cas de test 2
Dans ce cas, nous utilisons l'utilitaire shell mysql pour charger le fichier de sauvegarde sur un autre hôte autonome. Nous avons déjà déplacé le fichier de sauvegarde vers le serveur de destination. Commençons le processus de restauration.
Exemple
MySQL localhost:33060+ ssl JS > util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
Executing DDL script for schema `cluster_control`
Executing DDL script for schema `proxydemo`
Executing DDL script for schema `sbtest`
.
.
.
2 thds loading \ 1% (150.66 MB / 9.78 GB), 6.74 MB/s, 4 / 10 tables done
2 thds loading / 100% (9.79 GB / 9.79 GB), 1.29 MB/s, 10 / 10 tables done
[Worker001] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
[Worker002] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
Executing common postamble SQL
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 2 schemas were loaded in 40 min 6 sec (avg throughput 4.06 MB/s)Il a fallu environ 40 minutes et 6 secondes pour restaurer les 10 Go de données.
Essayons maintenant de désactiver le journal de rétablissement et de démarrer l'importation des données à l'aide de mysql utilitaire shell.
mysql> alter instance disable innodb redo_log;
Query OK, 0 rows affected (0.00 sec)
MySQL localhost:33060+ ssl JS >util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
.
.
.
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 3 schemas were loaded in 19 min 56 sec (avg throughput 8.19 MB/s)
0 warnings were reported during the load.Après la désactivation du journal de rétablissement, le débit moyen a été multiplié par 2.
Remarque :Ne désactivez pas la journalisation redo sur un système de production. Il permet l'arrêt et le redémarrage du serveur lorsque la journalisation redo est désactivée, mais un arrêt inattendu du serveur alors que la journalisation redo est désactivée peut entraîner une perte de données et une corruption d'instance.
Sauvegardes physiques
Comme vous l'avez peut-être remarqué, les méthodes de sauvegarde logique, même multithread, prennent beaucoup de temps, même pour un petit ensemble de données sur lequel nous les avons testées. C'est l'une des raisons pour lesquelles ClusterControl fournit une méthode de sauvegarde physique basée sur la copie des fichiers - dans ce cas, nous ne sommes pas limités par la couche SQL qui traite la sauvegarde logique mais plutôt par le matériel - la vitesse à laquelle le disque peut lire les fichiers et la vitesse à laquelle le réseau peut transférer des données entre le nœud de la base de données et le serveur de sauvegarde.
ClusterControl propose différentes manières d'implémenter des sauvegardes physiques, la méthode disponible dépendra du type de cluster et parfois même du fournisseur. Jetons un coup d'œil à l'Xtrabackup exécuté par ClusterControl qui créera une sauvegarde complète des données sur notre environnement de test.
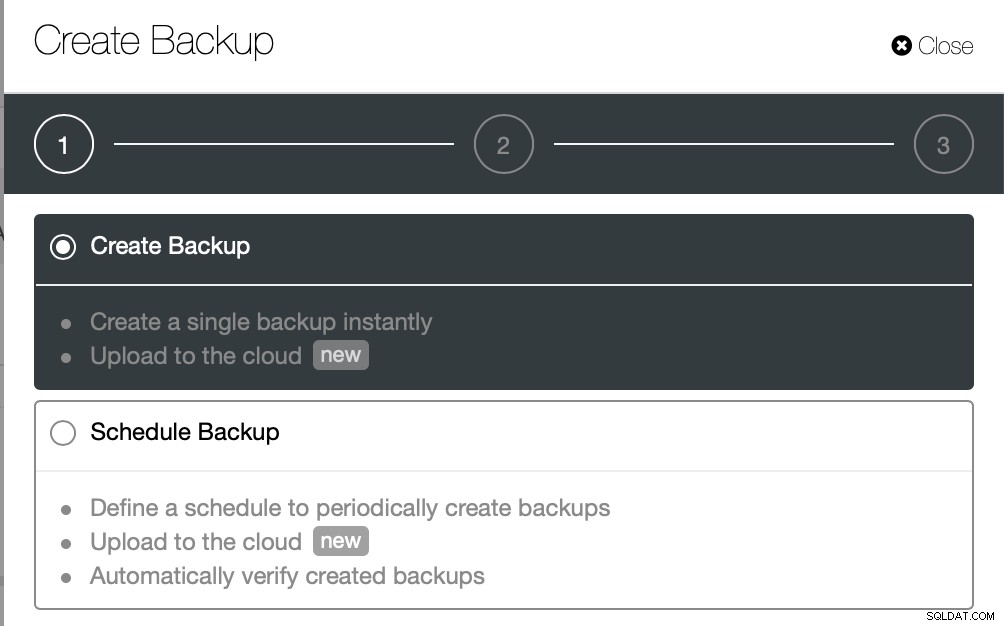
Nous allons créer une sauvegarde ad hoc cette fois mais ClusterControl permet vous créez également une planification de sauvegarde complète.
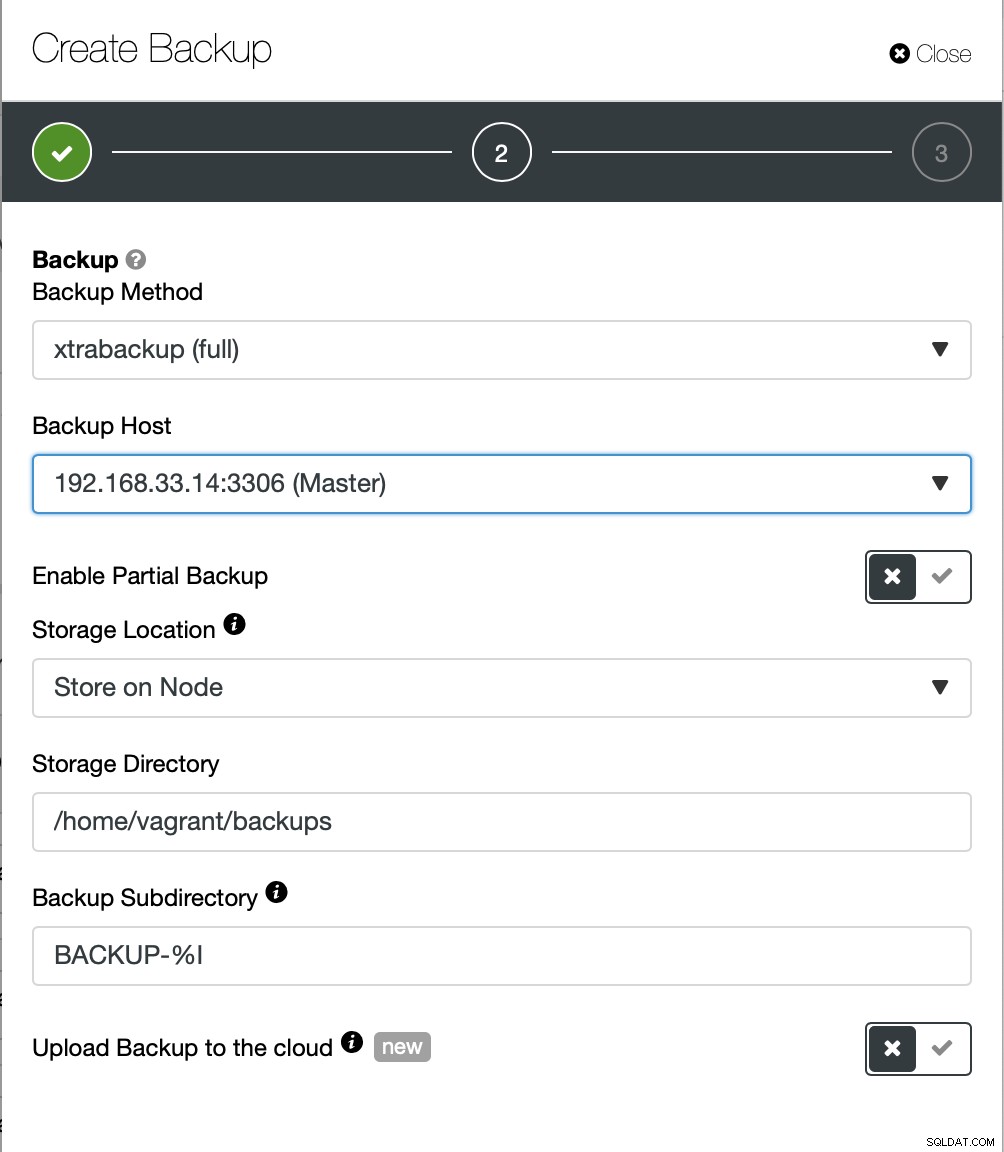
Ici, nous choisissons la méthode de sauvegarde (xtrabackup) ainsi que l'hôte que nous vont prendre la sauvegarde à partir de. Nous pouvons également le stocker localement sur le nœud ou le diffuser sur une instance ClusterControl. De plus, vous pouvez télécharger la sauvegarde sur le cloud (AWS, Google Cloud et Azure sont pris en charge).
La sauvegarde a duré environ 10 minutes. Voici les journaux du fichier cmon_backup.metadata.
[example@sqldat.com BACKUP-9]# cat cmon_backup.metadata
{
"class_name": "CmonBackupRecord",
"backup_host": "192.168.33.14",
"backup_tool_version": "2.4.21",
"compressed": true,
"created": "2020-11-17T23:37:15.000Z",
"created_by": "",
"db_vendor": "oracle",
"description": "",
"encrypted": false,
"encryption_md5": "",
"finished": "2020-11-17T23:47:47.681Z"
}Essayons maintenant la même chose pour restaurer à l'aide de ClusterControl. ClusterControl > Sauvegarde > Restaurer la sauvegarde
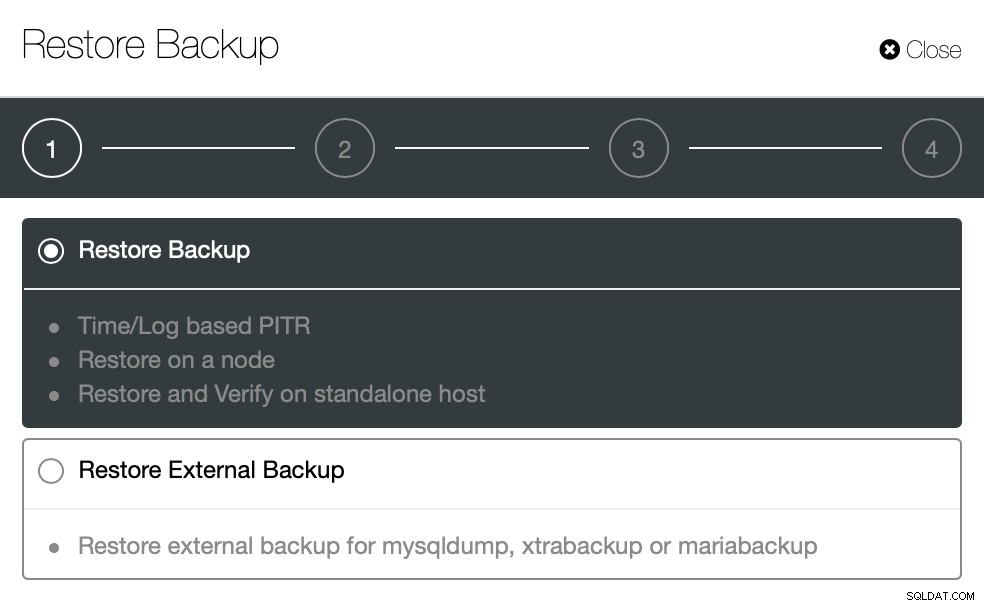
Ici, nous choisissons l'option de sauvegarde de restauration, elle prendra en charge l'heure et le journal récupération aussi.
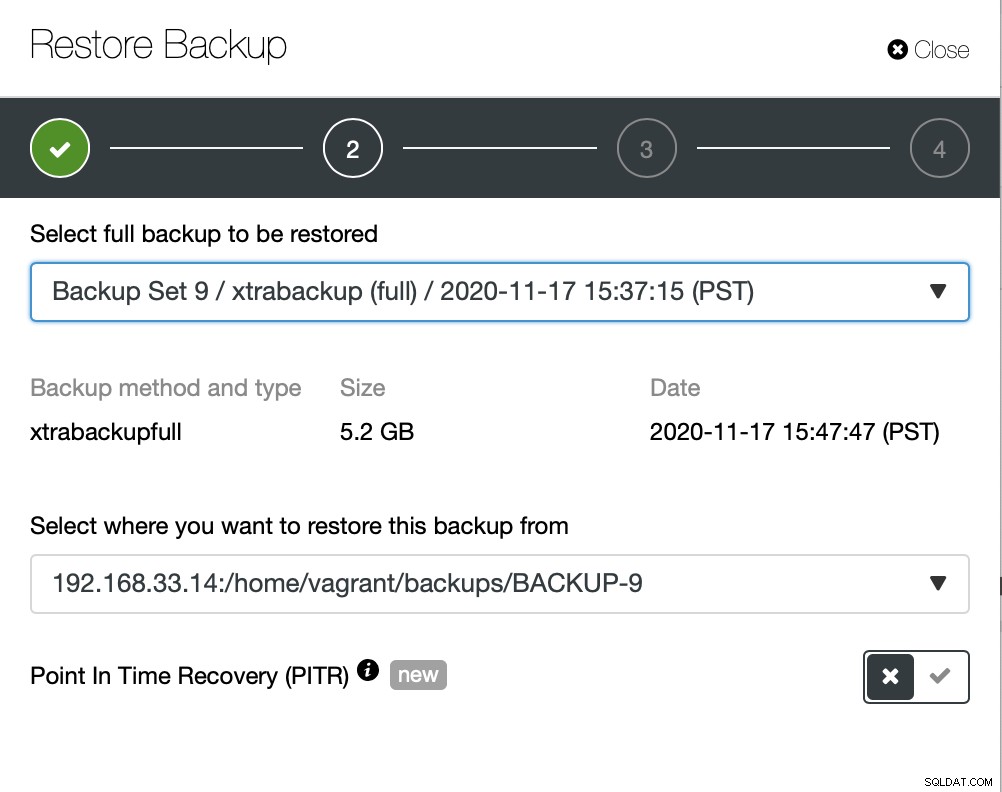
Ici, nous choisissons le chemin source du fichier de sauvegarde, puis le serveur de destination. Vous devez également vous assurer que cet hôte est accessible à partir du nœud ClusterControl à l'aide de SSH.
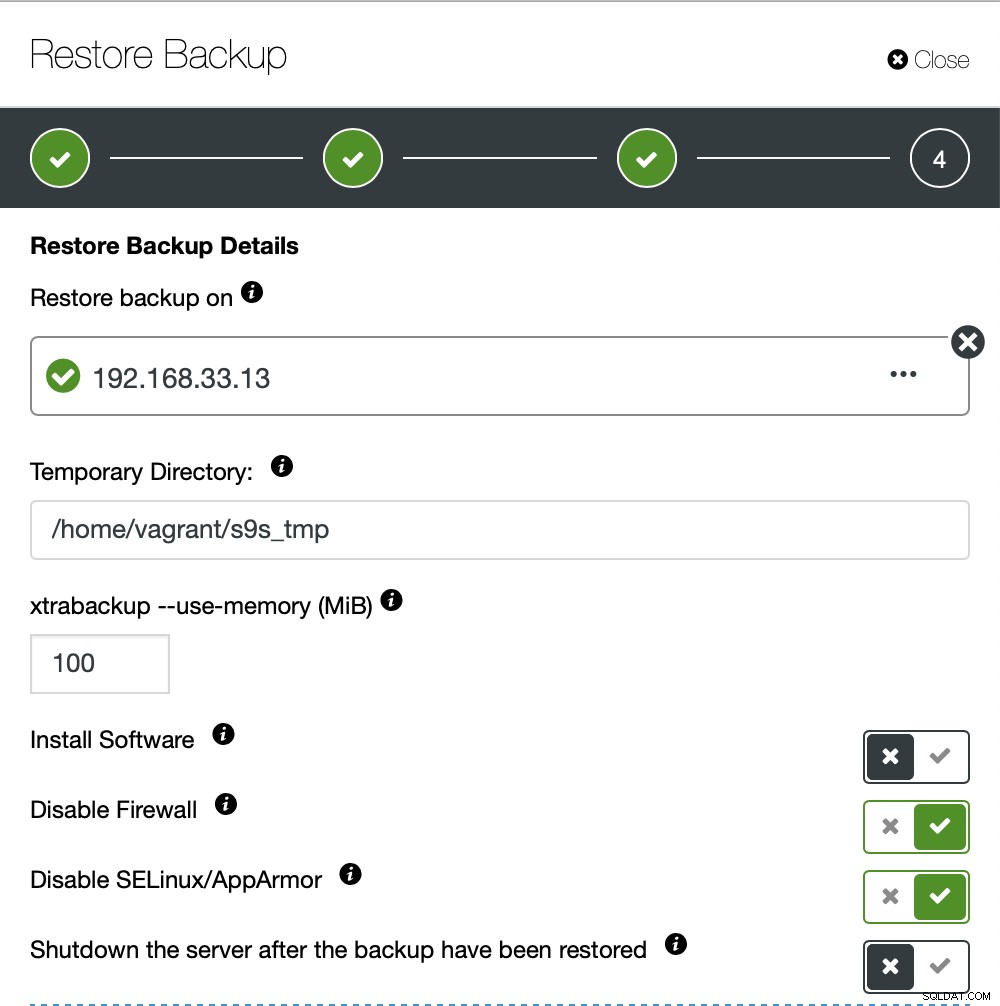
Nous ne voulons pas que ClusterControl configure le logiciel, nous avons donc désactivé cette option. Après la restauration, le serveur continuera de fonctionner.
Il a fallu environ 4 minutes 18 secondes pour restaurer les 10 Go de données. Xtrabackup ne verrouille pas votre base de données pendant le processus de sauvegarde. Pour les grandes bases de données (plus de 100 Go), il offre un temps de restauration bien meilleur par rapport à l'utilitaire mysqldump/shell. LustreControl prend également en charge la sauvegarde et la restauration partielles comme l'un de mes collègues l'a expliqué dans son blog :Sauvegarde et restauration partielles.
Conclusion
Chaque méthode a ses propres avantages et inconvénients. Comme nous l'avons vu, il n'y a pas une seule méthode qui fonctionne le mieux pour tout ce que vous devez faire. Nous devons choisir notre outil en fonction de notre environnement de production et du temps cible pour la récupération.