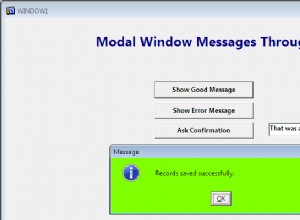
L'index clusterisé n'est pas "juste une contrainte", c'est une méthode de stockage.
Lorsque vous le déposez, vos données sont réorganisées du stockage en cluster au stockage en tas
D'autres index sont mis à jour pour faire référence à RID au lieu de PRIMARY KEY valeurs.