Dans cet article, nous aborderons plusieurs problèmes auxquels vous pourriez être confronté lors de la création, de la configuration ou de la maintenance d'un site Always on Availability Group.
Avant de parcourir cet article, il est recommandé de lire l'article précédent, Configuration et configuration du groupe de disponibilité Always on dans SQL Server, pour se familiariser avec le concept de groupe de disponibilité Always on et les assistants Nouveau groupe de disponibilité présentés dans cet article.
Fonctionnalité de groupe de disponibilité Always on non activée
Supposons que, lors de la tentative de création d'un nouveau groupe de disponibilité Always On, à partir du nœud Always On High Availability, sous l'Explorateur d'objets de SQL Server Management Studio, vous ayez rencontré le message d'erreur ci-dessous :
La fonctionnalité Always On Availability Groups doit être activée pour l'instance de serveur « SQL1 » avant de pouvoir créer un groupe de disponibilité sur cette instance. Pour activer cette fonctionnalité, ouvrez le gestionnaire de configuration SQL Server, sélectionnez Services SQL Server, cliquez avec le bouton droit sur le nom du service SQL Server, sélectionnez Propriétés et utilisez l'onglet Groupes de disponibilité AlwaysOn de la boîte de dialogue Propriétés du serveur. L'activation des groupes de disponibilité AlwaysOn peut nécessiter que l'instance de serveur soit hébergée par un nœud de cluster de basculement Windows Server (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

Il ressort clairement du message d'erreur que la fonctionnalité Groupes de disponibilité AlwaysOn doit être activée sur chaque instance SQL Server qui participe au site du groupe de disponibilité AlwaysOn, avant de créer ce site.
Vous pouvez facilement activer la fonctionnalité Toujours sur le groupe de disponibilité, en ouvrant la console SQL Server Configuration Manager, parcourez l'onglet Services SQL Server, puis cliquez avec le bouton droit sur le service Moteur de base de données SQL Server et choisissez l'option Propriétés.
Dans la fenêtre Propriétés de SQL Server ouverte, accédez à l'onglet Toujours en haute disponibilité et cochez la case à côté de Activer le groupe de disponibilité en permanence , en tenant compte du fait que cette modification nécessite le redémarrage du service SQL Server pour prendre effet, comme indiqué ci-dessous :

Problème de validation des prérequis de la base de données
Dans les étapes précédentes de l'assistant Nouveau groupe de disponibilité, il vous sera demandé de spécifier la ou les bases de données qui participeront au groupe de disponibilité Always on. Avant d'ajouter la base de données, la base de données doit réussir le contrôle de validation des prérequis. Sinon, la base de données ne peut pas être sélectionnée dans les listes de bases de données, comme indiqué dans le message d'erreur ci-dessous :
Pour être ajoutée à un groupe de disponibilité, cette base de données doit être définie sur le modèle de récupération complète. Définissez la propriété de base de données du modèle de récupération sur Complète et effectuez une sauvegarde de base de données complète ou différentielle sur la base de données. Vous devrez ensuite programmer des sauvegardes de journaux sur la base de données.

Le message est clair. Où la base de données doit être configurée avec un modèle de récupération complète et une sauvegarde complète ou différentielle doit être effectuée sur cette base de données.
En outre, l'assistant vous avertit de planifier une sauvegarde du journal des transactions pour cette base de données après avoir défini le modèle de récupération sur Complète, afin de tronquer automatiquement le fichier journal des transactions et d'empêcher l'exécution de ce fichier journal des transactions à court d'espace libre.
Pour résoudre ce problème, modifiez le modèle de récupération de la base de données de Simple à Complet, dans l'onglet Options de la fenêtre des propriétés de la base de données, puis effectuez une sauvegarde complète de cette base de données, comme indiqué ci-dessous :

En actualisant la fenêtre Sélectionner des bases de données, l'état de la base de données sera modifié en Répondre aux prérequis, comme indiqué ci-dessous :

Problème d'autorisation d'emplacement réseau partagé
Lors de la tentative de configuration d'un site Always on Availability Group, l'étape de validation de l'assistant Nouveau groupe de disponibilité a échoué avec le message d'erreur ci-dessous :
Le serveur principal 'SQL1' ne peut pas écrire dans '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
La sauvegarde a échoué pour le serveur 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Impossible d'ouvrir le périphérique de sauvegarde '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Erreur de système d'exploitation 5 (accès refusé.).
BACKUP DATABASE se termine anormalement. (Fournisseur de données .Net SqlClient)
Dans la méthode de synchronisation initiale de la sauvegarde complète de la base de données et du journal, un dossier partagé est requis pour conserver temporairement les fichiers de sauvegarde complète et de sauvegarde du journal des transactions afin de les restaurer sur tous les réplicas secondaires. Si le réplica principal n'est pas en mesure d'y écrire les fichiers de sauvegarde, ou si les réplicas secondaires ne sont pas en mesure de lire les fichiers de sauvegarde à partir de celui-ci, le processus de validation du nouveau groupe de disponibilité échouera comme ci-dessous :

Pour résoudre ce problème, nous devons accorder au compte de service SQL Server des réplicas principal et secondaire l'autorisation de lecture et d'écriture sur le dossier partagé affiché dans le message d'erreur, puis relancer le processus de validation pour nous assurer que toutes les vérifications sont réussies. , comme indiqué ci-dessous :

Problème de cluster de basculement Windows
Supposons que vous vérifiez l'état d'un site Always on Availability Group existant et que vous constatez que :
- Le rôle principal est déplacé de l'instance SQL1 vers SQL2.
- En SQL2, les bases de données sont à l'état Synchronisé.
- En SQL1, les bases de données ne sont pas synchronisées.
- SQL1 est en état de résolution.
Comme vous pouvez le voir clairement dans l'explorateur d'objets SSMS ci-dessous :

En vérifiant les journaux d'erreurs SQL Server dans le nœud problématique, nous pouvons voir que le réplica du groupe de disponibilité est hors ligne et que le groupe de disponibilité a cessé de fonctionner en raison d'un problème dans le cluster de basculement Windows Server, comme indiqué dans les erreurs ci-dessous :
- Groupes de disponibilité toujours actifs :le nœud local de clustering de basculement Windows Server n'est plus en ligne . Il s'agit d'un message d'information uniquement. Aucune action de l'utilisateur n'est requise.
- Toujours activé :le gestionnaire de réplicas de disponibilité se déconnecte car le nœud local de clustering de basculement Windows Server (WSFC) a perdu le quorum. Il s'agit d'un message d'information uniquement. Aucune action de l'utilisateur n'est requise.
- Toujours activé :le réplica local du groupe de disponibilité "DemoGroup" s'arrête. Il s'agit d'un message d'information uniquement. Aucune action de l'utilisateur n'est requise.

La même chose peut être détectée à partir de l'Observateur d'événements de Windows Server, qui montre progressivement comment la réplique passe à l'état de résolution, comme ci-dessous :
- Toujours activé :le réplica local du groupe de disponibilité "DemoGroup" se prépare à passer au rôle de résolution . Il s'agit d'un message d'information uniquement. Aucune action de l'utilisateur n'est requise.
- Le groupe de disponibilité "DemoGroup" est invité à arrêter le renouvellement du bail car le groupe de disponibilité est en train de se déconnecter . Il s'agit d'un message d'information uniquement. Aucune action de l'utilisateur n'est requise.
- L'état du réplica de disponibilité local dans le groupe de disponibilité 'DemoGroup' est passé de 'PRIMARY_NORMAL' à 'RESOLVING_NORMAL'. L'état a changé car le groupe de disponibilité est en train de se déconnecter. Le réplica se déconnecte car le groupe de disponibilité associé a été supprimé, ou l'utilisateur a mis le groupe de disponibilité associé hors ligne dans la console de gestion du clustering de basculement Windows Server (WSFC), ou le groupe de disponibilité bascule vers une autre instance de SQL Server. Pour plus d'informations, consultez le journal des erreurs SQL Server ou le journal du cluster. S'il s'agit d'un groupe de disponibilité Windows Server Failover Clustering (WSFC), vous pouvez également voir la console de gestion WSFC.

Pour vérifier l'état du site du cluster Windows, nous utiliserons le gestionnaire de cluster de basculement pour voir quelle partie du cluster Windows est défaillante.
Mais le gestionnaire de cluster de basculement indique que l'ensemble du cluster est en panne, comme indiqué ci-dessous :

La première chose à valider ici du côté du cluster de basculement Windows est le service de cluster, qui peut être vérifié depuis la console des services Windows, comme ci-dessous :

Il ressort clairement de la console Services que le service de cluster n'est pas en cours d'exécution. Pour résoudre ce problème, démarrez le service à partir de cette console, puis actualisez la console du gestionnaire de cluster de basculement pour vous assurer que le site du cluster Windows est opérationnel, comme indiqué ci-dessous :

En vérifiant à nouveau le groupe de disponibilité Always on, vous verrez que les bases de données sont à nouveau synchronisées et que le site du groupe de disponibilité Always on est à nouveau en état de santé, comme indiqué ci-dessous :

Le fichier journal des transactions est plein du côté principal
Supposons que vous receviez le message d'erreur ci-dessous lorsque vous essayez d'exécuter une nouvelle requête sur l'une des bases de données Always on Availability Group :

En vérifiant ce qui bloque le fichier des journaux de transactions et l'empêche d'être tronqué, vous verrez que le fichier journal des transactions de cette base de données est en attente d'opération de sauvegarde du journal pour être tronqué, comme indiqué ci-dessous :

Effectuez une sauvegarde du journal des transactions pour cette base de données, au cas où vous oublieriez de planifier une tâche de sauvegarde du journal des transactions, comme suit :

Et vérifiez à nouveau ce qui bloque le journal des transactions de cette base de données, cela montre dans mon scénario qu'il attend Availability_Replica. Ce qui signifie que les journaux attendent d'être écrits sur le réplica secondaire, mais ne sont pas en mesure d'envoyer ces journaux de transactions aux réplicas secondaires en raison d'un problème sur le site Always on Availability Group, comme ci-dessous :

Le meilleur emplacement pour vérifier et dépanner le site Always on Availability Group est le tableau de bord Always on, qui peut être ouvert en cliquant avec le bouton droit sur le nom du groupe de disponibilité et en choisissant l'option Afficher le tableau de bord.
Dans le tableau de bord, vous pouvez voir que le réplica secondaire SQL2 n'est pas synchronisé avec le réplica principal, en raison d'un problème de connectivité, comme indiqué ci-dessous :

Vérifiez le réplica secondaire et assurez-vous que le service SQL Server est opérationnel du côté secondaire, comme suit :

Ensuite, en actualisant à nouveau le tableau de bord du groupe de disponibilité, vous verrez que le site Always on Availability Group est à nouveau sain. Checking if the transaction logs file is blocked by any operation, we will see that it is pending OLDEST_PAGE, indicating that the oldest page of the database is older than the checkpoint LSN. This issue can be fixed easily by taking another transaction log backup and the transaction log file will be blocked by nothing, as shown clearly below:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

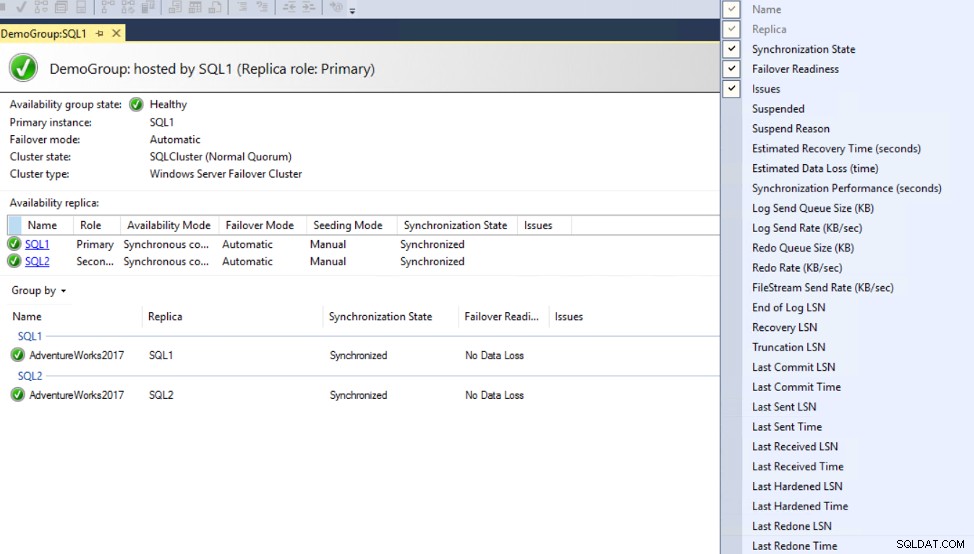
Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below: