Parfois, il est difficile de gérer une grande quantité de données dans une entreprise, en particulier avec l'augmentation exponentielle de l'utilisation de Data Analytics et de l'IoT. Selon la taille, cette quantité de données peut affecter les performances de vos systèmes et vous devrez probablement mettre à l'échelle vos bases de données ou trouver un moyen de résoudre ce problème. Il existe différentes façons de mettre à l'échelle vos bases de données PostgreSQL et l'une d'elles est le partage. Dans ce blog, nous verrons ce qu'est le Sharding et comment le configurer dans PostgreSQL en utilisant ClusterControl pour simplifier la tâche.
Qu'est-ce que le partage ?
Le partitionnement est l'action d'optimiser une base de données en séparant les données d'une grande table en plusieurs petites. Les tables plus petites sont des fragments (ou partitions). Le partitionnement et le sharding sont des concepts similaires. La principale différence est que le partitionnement implique que les données sont réparties sur plusieurs ordinateurs, tandis que le partitionnement consiste à regrouper des sous-ensembles de données dans une seule instance de base de données.
Il existe deux types de partition :
-
Partage horizontal :chaque nouvelle table a le même schéma que la grande table mais des lignes uniques. Il est utile lorsque les requêtes ont tendance à renvoyer un sous-ensemble de lignes souvent regroupées.
-
Partage vertical :chaque nouvelle table a un schéma qui est un sous-ensemble du schéma de la table d'origine. Il est utile lorsque les requêtes ont tendance à ne renvoyer qu'un sous-ensemble de colonnes de données.
Voyons un exemple :
Tableau d'origine
| ID | Nom | Âge | Pays |
|---|---|---|---|
| 1 | James Smith | 26 | États-Unis |
| 2 | Mary Johnson | 31 | Allemagne |
| 3 | Robert Williams | 54 | Canada |
| 4 | Jennifer Brown | 47 | France |
Partage vertical
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Nom | Âge | ID | Pays |
| 1 | James Smith | 26 | 1 | États-Unis |
| 2 | Mary Johnson | 31 | 2 | Allemagne |
| 3 | Robert Williams | 54 | 3 | Canada |
| 4 | Jennifer Brown | 47 | 4 | France |
Partage horizontal
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Nom | Âge | Pays | ID | Nom | Âge | Pays |
| 1 | James Smith | 26 | États-Unis | 3 | Robert Williams | 54 | Canada |
| 2 | Mary Johnson | 31 | Allemagne | 4 | Jennifer Brown | 47 | France |
Maintenant que nous avons passé en revue certains concepts de partitionnement, passons à l'étape suivante.
Comment déployer un cluster PostgreSQL ?
Nous utiliserons ClusterControl pour cette tâche. Si vous n'utilisez pas encore ClusterControl, vous pouvez l'installer et déployer ou importer votre base de données PostgreSQL actuelle en sélectionnant l'option "Importer" et suivre les étapes pour profiter de toutes les fonctionnalités de ClusterControl telles que les sauvegardes, le basculement automatique, les alertes, la surveillance, etc. .
Pour effectuer un déploiement à partir de ClusterControl, sélectionnez simplement l'option "Déployer" et suivez les instructions qui s'affichent.
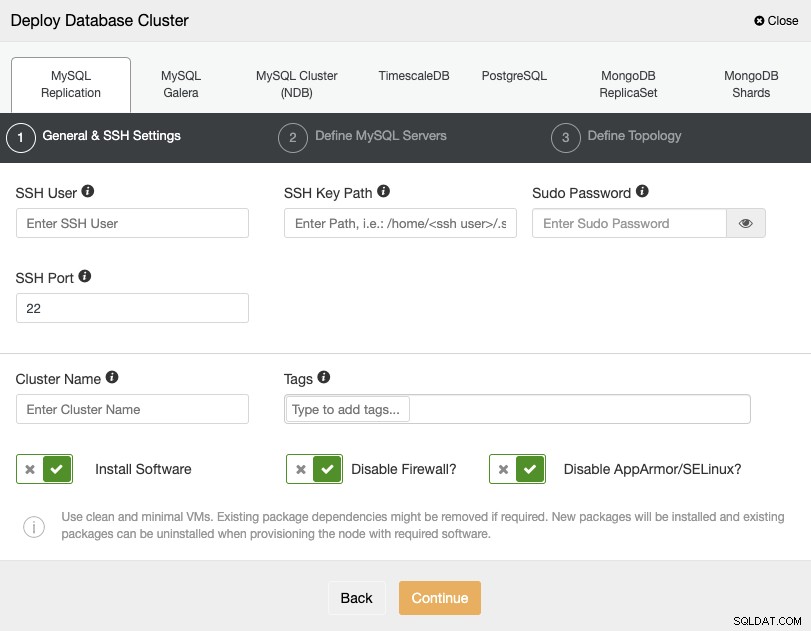
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier votre utilisateur, clé ou mot de passe, et Port pour se connecter en SSH à vos serveurs. Vous pouvez également ajouter un nom pour votre nouveau cluster et si vous le souhaitez, vous pouvez également utiliser ClusterControl pour installer le logiciel et les configurations correspondants pour vous.
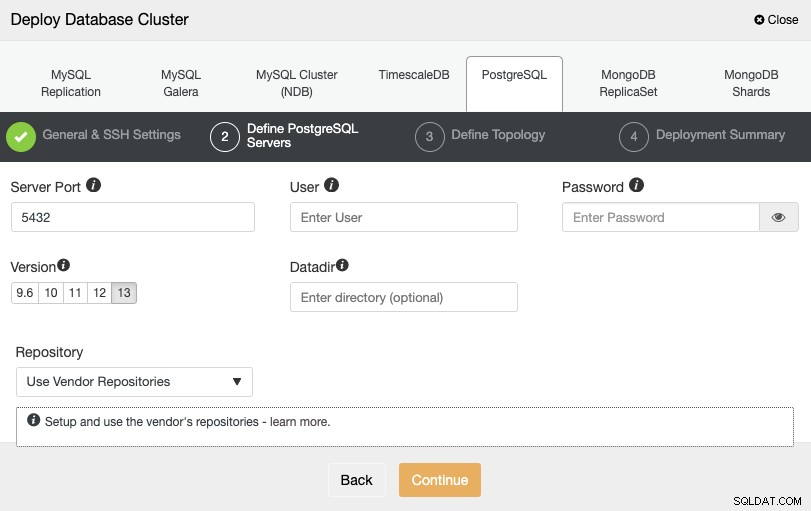
Après avoir configuré les informations d'accès SSH, vous devez définir les informations d'identification de la base de données , version et datadir (facultatif). Vous pouvez également spécifier le référentiel à utiliser.
Pour l'étape suivante, vous devez ajouter vos serveurs au cluster que vous allez créer en utilisant l'adresse IP ou le nom d'hôte.
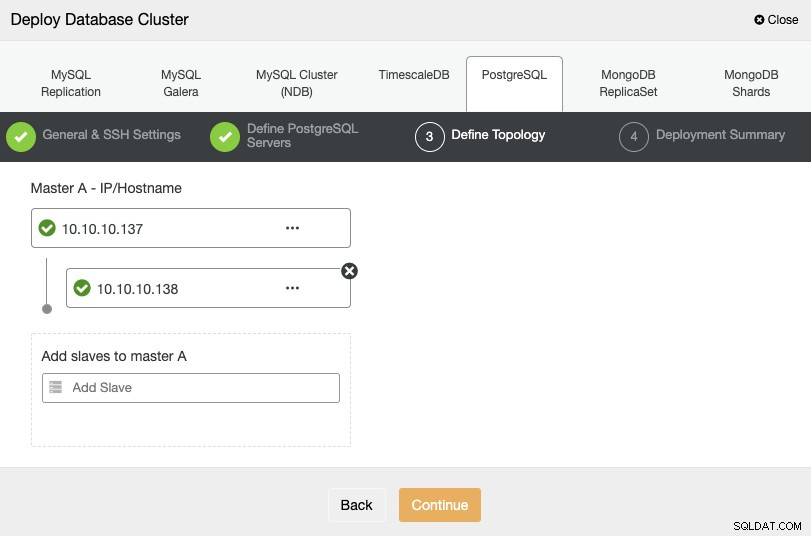
Dans la dernière étape, vous pouvez choisir si votre réplication sera synchrone ou Asynchrone, puis appuyez simplement sur "Déployer".
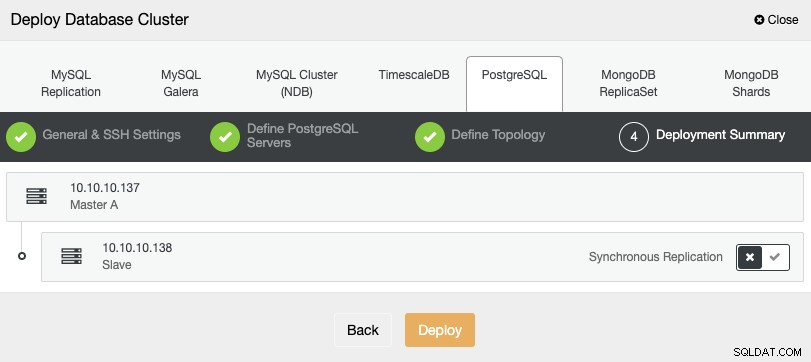
Une fois la tâche terminée, vous verrez votre nouveau cluster PostgreSQL dans le l'écran principal de ClusterControl.

Maintenant que vous avez créé votre cluster, vous pouvez effectuer plusieurs tâches dessus comme l'ajout d'un équilibreur de charge (HAProxy), d'un pool de connexions (pgBouncer) ou d'un nouveau réplica.
Répétez le processus pour avoir au moins deux clusters PostgreSQL distincts pour configurer Sharding, qui est l'étape suivante.
Comment configurer le partage PostgreSQL ?
Nous allons maintenant configurer le sharding à l'aide des partitions PostgreSQL et du Foreign Data Wrapper (FDW). Cette fonctionnalité permet à PostgreSQL d'accéder aux données stockées sur d'autres serveurs. Il s'agit d'une extension disponible par défaut dans l'installation commune de PostgreSQL.
Nous utiliserons l'environnement suivant :
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersPour activer l'extension FDW, il vous suffit d'exécuter la commande suivante sur votre serveur principal, dans ce cas, Shard1 :
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONCréons maintenant la table des clients partitionnés par date d'enregistrement :
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Et les partitions suivantes :
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Ces partitions sont locales. Insérons maintenant quelques valeurs de test et vérifions-les :
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Ici, vous pouvez interroger la partition principale pour voir toutes les données :
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Ou même interroger la partition correspondante :
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Comme vous pouvez le voir, les données ont été insérées dans différentes partitions, selon la date d'enregistrement. Maintenant, dans le nœud distant, dans ce cas Shard2, créons une autre table :
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Vous devez créer ce serveur Shard2 dans Shard1 de cette manière :
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Et l'utilisateur pour y accéder :
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Maintenant, créez la FOREIGN TABLE dans Shard1 :
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;Et insérons des données dans cette nouvelle table distante à partir de Shard1 :
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Si tout s'est bien passé, vous devriez pouvoir accéder aux données de Shard1 et Shard2 :
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2 :
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)C'est tout. Vous utilisez maintenant Sharding dans votre cluster PostgreSQL.
Conclusion
Le partitionnement et le partage dans PostgreSQL sont de bonnes fonctionnalités. Il vous aide au cas où vous auriez besoin de séparer les données dans une grande table pour améliorer les performances, ou même de purger les données de manière simple, entre autres situations. Un point important lorsque vous utilisez Sharding est de choisir une bonne clé de partition qui distribue au mieux les données entre les nœuds. En outre, vous pouvez utiliser ClusterControl pour simplifier le déploiement de PostgreSQL et tirer parti de certaines fonctionnalités telles que la surveillance, les alertes, le basculement automatique, la sauvegarde, la récupération à un moment précis, etc.



