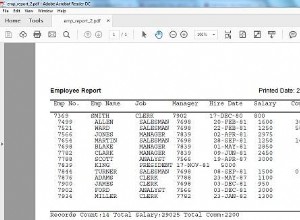
Essayez ceci :
;with cte as
(select *, rank() over(partition by ID_Emp order by [Date]) rn
from attendance)
select src.ID_Emp, src.Name, convert(date, src.[Date]) as [Date],
concat(datepart(hour,src.[Date]),':',datepart(minute,src.[Date])) as [TimeIn],
concat(datepart(hour,tgt.[Date]),':',datepart(minute,tgt.[Date])) as [TimeOut],
concat(datediff(minute,src.[Date],tgt.[Date])/60,':',datediff(minute,src.[Date],tgt. [Date])%60) as [Hours]
from cte src
inner join cte tgt on src.ID_Emp = tgt.ID_Emp and src.rn + 1 = tgt.rn and src.rn % 2 = 1
Mise en garde :J'ai testé cela uniquement sur SQL Server 2008 R2, mais je suppose que cela devrait également fonctionner sur Oracle avec les modifications appropriées.
Explication :Nous utilisons le RANK fonction pour trier par date et heure pour chaque ID_Emp . Ensuite, nous nous joignons sur ID et obtenir des paires de lignes. Enfin, afin de nous assurer que nous ne sélectionnons pas toutes les paires de lignes consécutives, nous imposons que le rang de la ligne source soit impair.