N'est-il pas formidable d'avoir une nouvelle version de SQL Server disponible ? C'est quelque chose qui n'arrive que tous les deux ans, et ce mois-ci, nous en avons vu un atteindre la disponibilité générale. (Ok, je sais que nous obtenons une nouvelle version de SQL Database dans Azure presque continuellement, mais je considère cela comme différent.) Reconnaissant cette nouvelle version, le mardi T-SQL de ce mois-ci (organisé par Michael Swart - @mjswart) traite de tout ce qui concerne SQL Server 2016 !
N'est-il pas formidable d'avoir une nouvelle version de SQL Server disponible ? C'est quelque chose qui n'arrive que tous les deux ans, et ce mois-ci, nous en avons vu un atteindre la disponibilité générale. (Ok, je sais que nous obtenons une nouvelle version de SQL Database dans Azure presque continuellement, mais je considère cela comme différent.) Reconnaissant cette nouvelle version, le mardi T-SQL de ce mois-ci (organisé par Michael Swart - @mjswart) traite de tout ce qui concerne SQL Server 2016 !
Donc, aujourd'hui, je veux regarder la fonctionnalité Tables temporelles de SQL 2016, et jeter un œil à certaines situations de plan de requête que vous pourriez finir par voir. J'adore les tables temporelles, mais je suis tombé sur un petit piège dont vous voudrez peut-être être conscient.
Maintenant, malgré le fait que SQL Server 2016 est maintenant en RTM, j'utilise AdventureWorks2016CTP3, que vous pouvez télécharger ici - mais ne vous contentez pas de télécharger AdventureWorks2016CTP3.bak , saisissez également SQLServer2016CTP3Samples.zip du même site.
Vous voyez, dans l'archive des exemples, il existe des scripts utiles pour essayer de nouvelles fonctionnalités, y compris certains pour les tables temporelles. C'est gagnant-gagnant - vous pouvez essayer un tas de nouvelles fonctionnalités, et je n'ai pas à répéter autant de scripts dans ce post. Quoi qu'il en soit, allez chercher les deux scripts sur les tables temporelles, en exécutant AW 2016 CTP3 Temporal Setup.sql , suivi de Temporal System-Versioning Sample.sql .
Ces scripts configurent des versions temporelles de quelques tables, dont HumanResources.Employee . Il crée HumanResources.Employee_Temporal (bien que, techniquement, cela aurait pu s'appeler n'importe quoi). A la fin de la CREATE TABLE , ce bit apparaît, ajoutant deux colonnes masquées à utiliser pour indiquer quand la ligne est valide et indiquant qu'une table doit être créée appelée HumanResources.Employee_Temporal_History pour stocker les anciennes versions.
... ValidFrom datetime2(7) GÉNÉRÉ TOUJOURS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GÉNÉRÉ TOUJOURS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)) WITH (SYSTEM_VERSIONING =ON (HISTORY_TABLE) =[HumanResources].[Employee_Temporal_History]));
Ce que je veux explorer dans cet article, c'est ce qui se passe avec les plans de requête lorsque l'historique est utilisé.
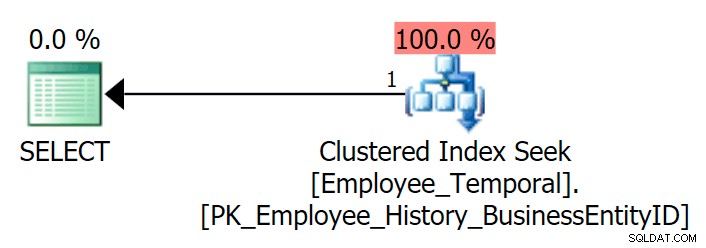
Si j'interroge la table pour voir la dernière ligne d'un BusinessEntityID particulier , j'obtiens une recherche d'index clusterisé, comme prévu.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4 ;
Je suis sûr que je pourrais interroger cette table en utilisant d'autres index, s'il y en avait. Mais dans ce cas, ce n'est pas le cas. Créons-en un.
CRÉER UN INDEX UNIQUE rf_ix_Login sur HumanResources.Employee_Temporal(LoginID);
Maintenant, je peux interroger la table par LoginID , et verra une recherche de clé si je demande des colonnes autres que Loginid ou BusinessEntityID . Rien de tout cela n'est surprenant.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
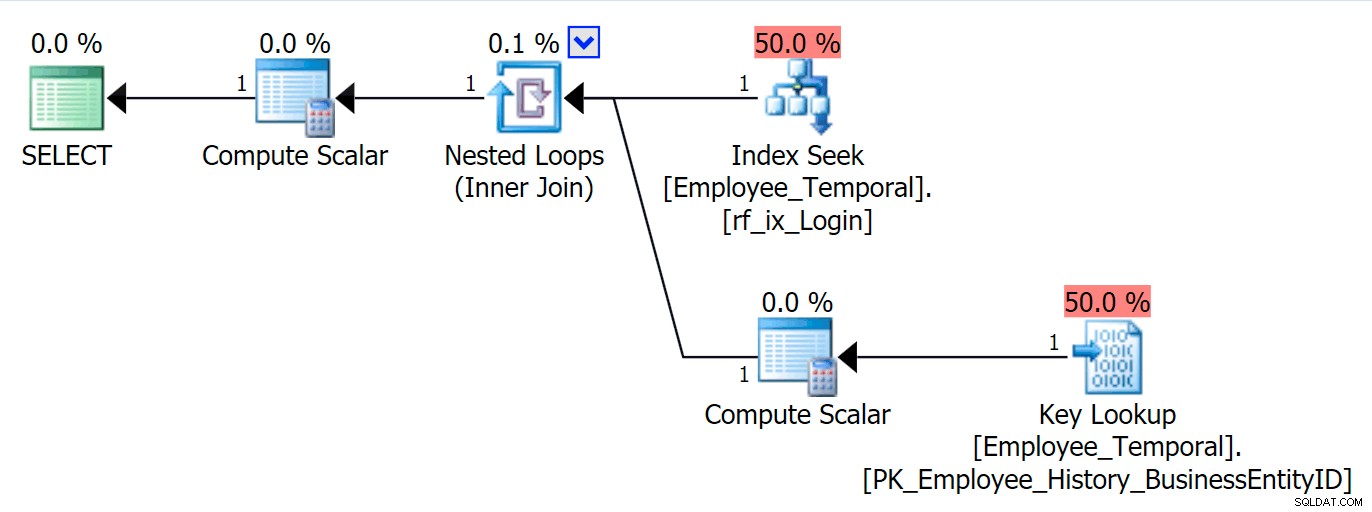
Utilisons SQL Server Management Studio pendant une minute et regardons à quoi ressemble ce tableau dans l'Explorateur d'objets.

Nous pouvons voir la table d'historique mentionnée sous HumanResources.Employee_Temporal , ainsi que les colonnes et les index de la table elle-même et de la table d'historique. Mais alors que les index sur la table appropriée sont la clé primaire (sur BusinessEntityID ) et l'index que je venais de créer, la table Historique n'a pas d'index correspondants.
L'index sur la table d'historique est sur ValidTo et ValidFrom . Nous pouvons cliquer avec le bouton droit sur l'index et sélectionner Propriétés, et nous voyons cette boîte de dialogue :
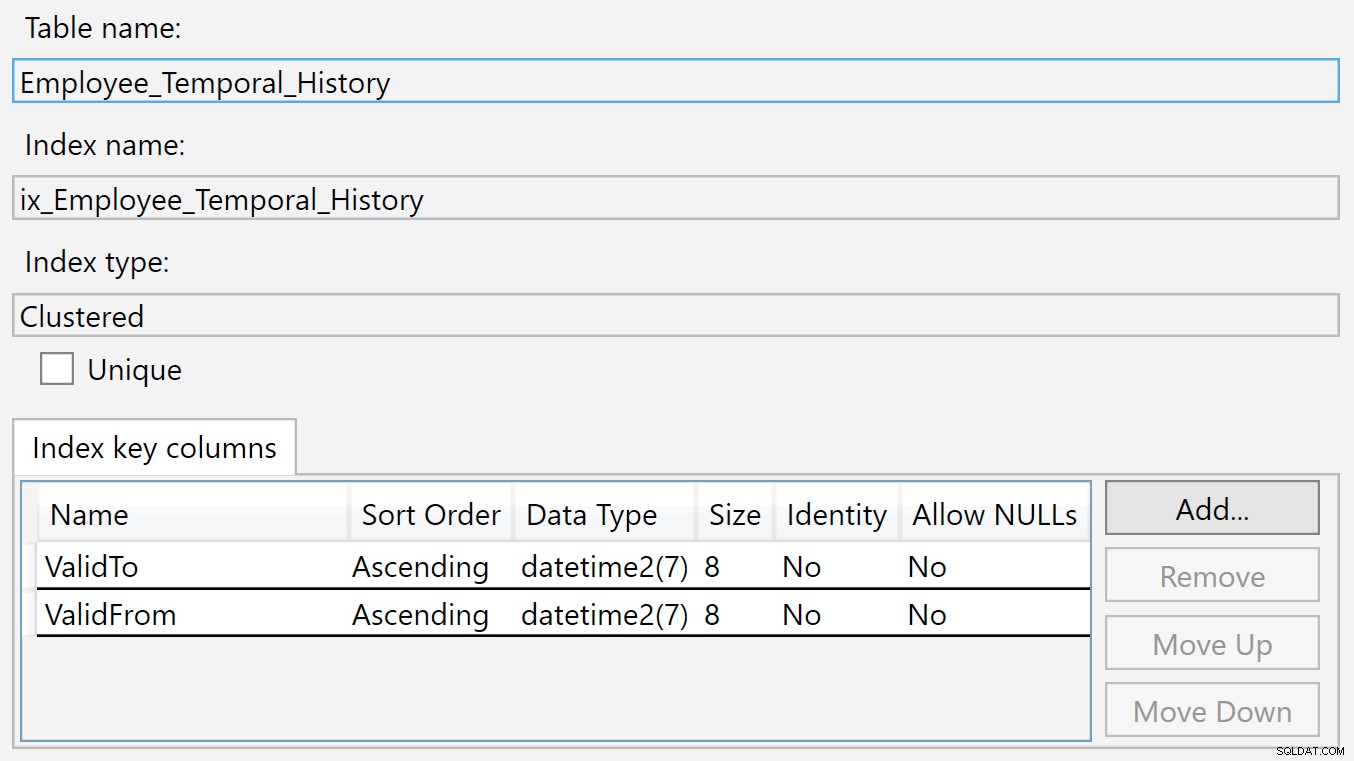
Une nouvelle ligne est insérée dans cette table Historique lorsqu'elle n'est plus valide dans la table principale, car elle vient d'être supprimée ou modifiée. Les valeurs dans le ValidTo colonne sont naturellement remplies avec l'heure actuelle, donc ValidTo agit comme une clé ascendante, comme une colonne d'identité, de sorte que les nouveaux inserts apparaissent à la fin de la structure b-tree.
Mais comment cela fonctionne-t-il lorsque vous souhaitez interroger la table ?
Si nous voulons interroger notre table sur ce qui était actuel à un moment donné, nous devons utiliser une structure de requête telle que :
SELECT * FROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22' ;
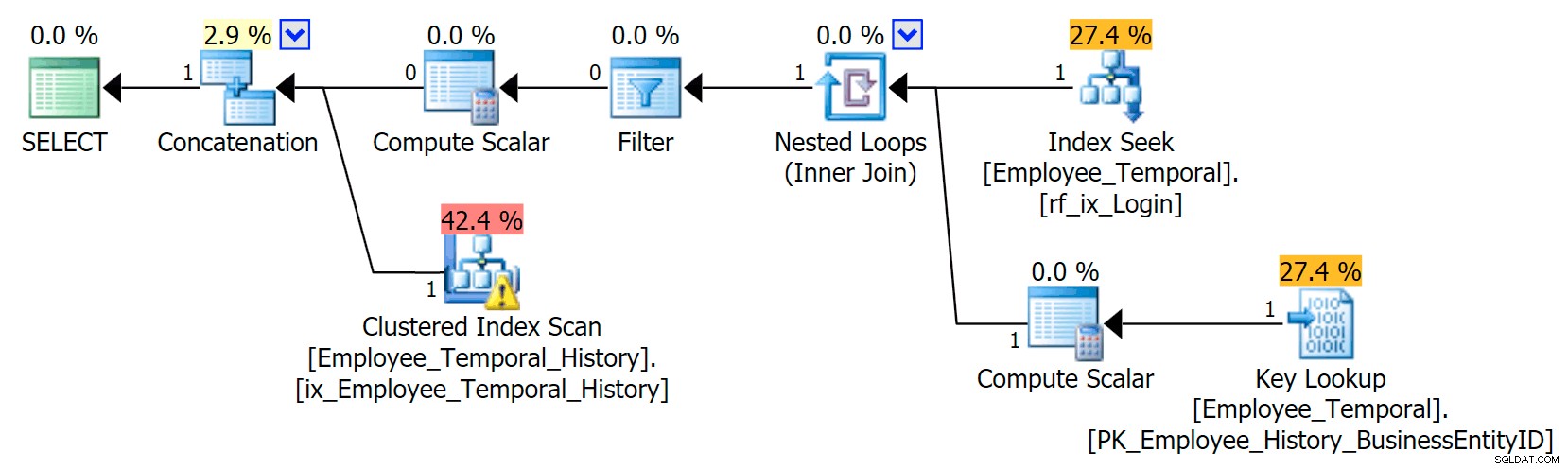
Cette requête doit concaténer les lignes appropriées de la table principale avec les lignes appropriées de la table d'historique.
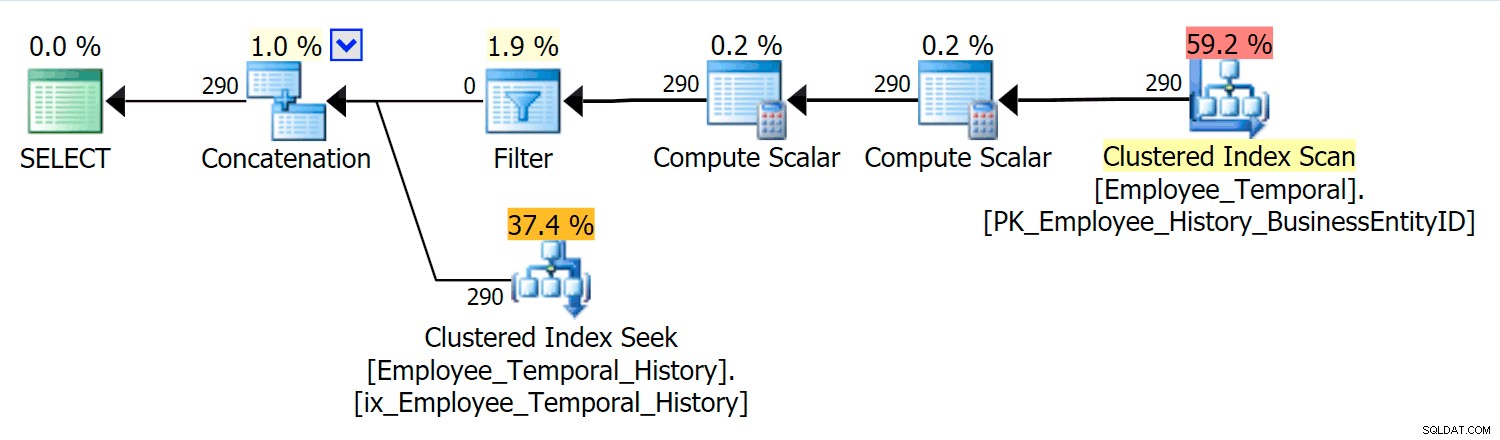
Dans ce scénario, les lignes valides pour le moment que j'ai sélectionnées provenaient toutes de la table d'historique, mais néanmoins, nous voyons un balayage d'index clusterisé par rapport à la table principale, qui a été filtrée par un opérateur de filtre. Le prédicat de ce filtre est :
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo]> '2016-06-12 11:22 :00.0000000'
Revoyons cela dans un instant.
La recherche d'index clusterisé sur la table d'historique doit clairement tirer parti d'un prédicat de recherche sur ValidTo. Le début de l'analyse de la plage de Seek est HumanResources.Employee_Temporal_History.ValidTo > Opérateur scalaire('2016-06-12 11:22:00') , mais il n'y a pas de fin, car chaque ligne qui a un ValidTo après l'heure qui nous intéresse est une ligne candidate et doit être testée pour un ValidFrom approprié valeur par le prédicat résiduel, qui est HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Maintenant, les intervalles sont difficiles à indexer ; c'est une chose connue qui a été discutée sur de nombreux blogs. Les solutions les plus efficaces envisagent des moyens créatifs d'écrire des requêtes, mais aucune intelligence de ce type n'a été intégrée aux tables temporelles. Cependant, vous pouvez également placer des index sur d'autres colonnes, comme sur ValidFrom, ou même avoir des index qui correspondent aux types de requêtes que vous pourriez avoir sur la table principale. Avec un index clusterisé étant une clé composite sur ValidTo et ValidFrom , ces deux colonnes sont incluses dans toutes les autres colonnes, ce qui offre une bonne opportunité pour certains tests de prédicat résiduel.
Si je sais quel ID de connexion m'intéresse, mon plan prend une forme différente.
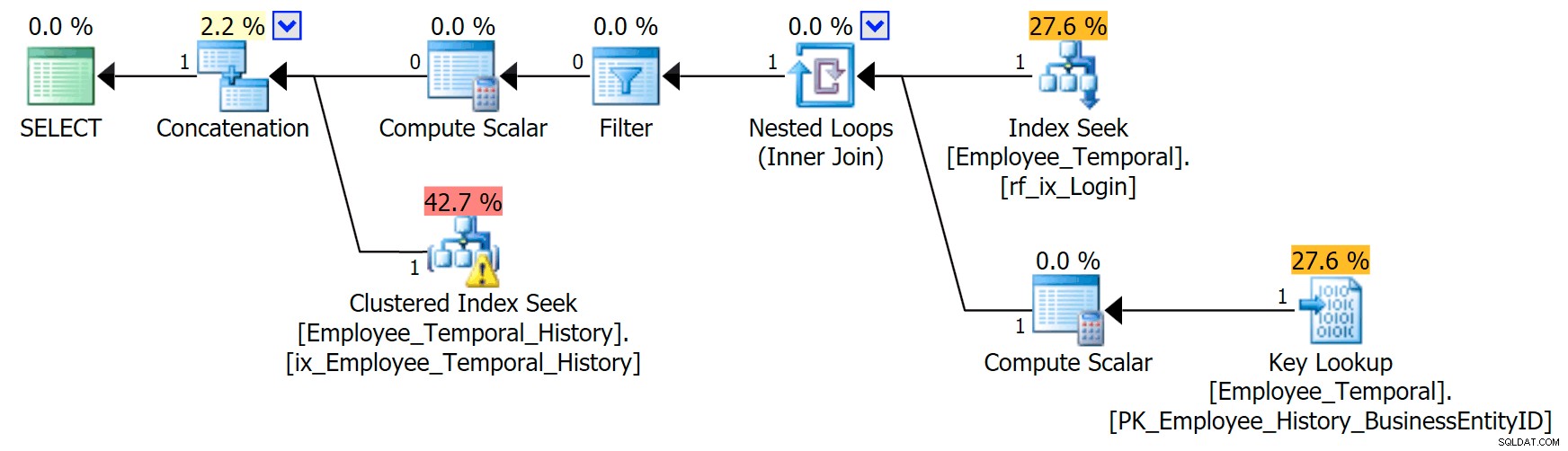
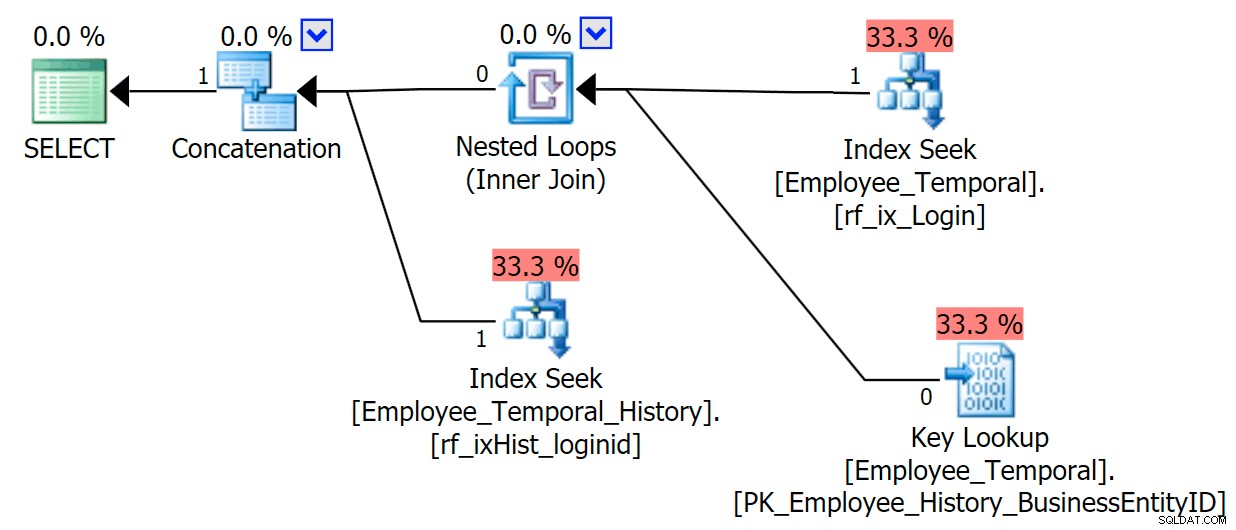
La branche supérieure de l'opérateur de concaténation ressemble à avant, bien que cet opérateur de filtre soit entré dans la mêlée pour supprimer toutes les lignes non valides, mais la recherche d'index clusterisé sur la branche inférieure a un avertissement. Il s'agit d'un avertissement de prédicat résiduel, comme les exemples d'un de mes précédents articles. Il est capable de filtrer les entrées qui sont valides jusqu'à un certain point après le moment qui nous intéresse, mais le prédicat résiduel filtre maintenant sur le LoginID ainsi que ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] =N'adventure-works\rob0'Les modifications apportées aux lignes de rob0 ne représenteront qu'une infime proportion des lignes de l'historique. Cette colonne ne sera pas unique comme dans la table principale, car la ligne peut avoir été modifiée plusieurs fois, mais il y a toujours un bon candidat pour l'indexation.
CREATE INDEX rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Ce nouvel index a un effet notable sur notre plan.
Cela a maintenant changé notre recherche d'index clusterisé en un balayage d'index clusterisé !!
Vous voyez, l'optimiseur de requête établit maintenant que la meilleure chose à faire serait d'utiliser le nouvel index. Mais il décide également que l'effort d'avoir à faire des recherches pour obtenir toutes les autres colonnes (parce que je demandais toutes les colonnes) serait tout simplement trop de travail. Le point de basculement a été atteint (malheureusement une hypothèse incorrecte dans ce cas), et un index clusterisé SCAN a été choisi à la place. Même si sans l'index non clusterisé, la meilleure option aurait été d'utiliser une recherche d'index clusterisé, lorsque l'index non clusterisé a été pris en compte et rejeté pour des raisons de point de basculement, il choisit d'analyser.
Frustrant, je viens juste de créer cet index et ses statistiques devraient être bonnes. Il devrait savoir qu'un Seek qui nécessite exactement une recherche devrait être meilleur qu'un Clustered Index Scan (uniquement par les statistiques - si vous pensiez qu'il devrait le savoir car
LoginIDest unique dans le tableau principal, n'oubliez pas qu'il ne l'a peut-être pas toujours été). Je soupçonne donc que les recherches devraient être évitées dans les tables d'historique, même si je n'ai pas encore fait assez de recherches à ce sujet.Maintenant, si nous devions interroger uniquement les colonnes qui apparaissent dans notre index non clusterisé, nous obtiendrions un bien meilleur comportement. Maintenant qu'aucune recherche n'est requise, notre nouvel index sur la table d'historique est utilisé avec plaisir. Il doit encore appliquer un prédicat résiduel basé uniquement sur la possibilité de filtrer sur
LoginIDetValidTo, mais il se comporte bien mieux que de tomber dans un balayage d'index clusterisé.SELECT LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Indexez donc vos tables d'historique de manière supplémentaire, en tenant compte de la manière dont vous les interrogerez. Incluez les colonnes nécessaires pour éviter les recherches, car vous évitez vraiment les analyses.
Ces tables d'historique peuvent devenir volumineuses si les données changent fréquemment. Soyez donc conscient de la façon dont ils sont traités. Cette même situation se produit lors de l'utilisation de l'autre
FOR SYSTEM_TIMEvous devez donc (comme toujours) examiner les plans produits par vos requêtes et les indexer pour vous assurer que vous êtes bien placé pour tirer parti de cette fonctionnalité très puissante de SQL Server 2016.