Il existe un bogue de régression dans SQL Server 2012 et SQL Server 2014 où, si vous reconstruisez un index en ligne en parallèle et que vous rencontrez également une erreur fatale telle qu'un délai de verrouillage, vous pouvez rencontrer perte ou corruption de données . Cela devrait être un scénario relativement rare (Phil Brammer a une reproduction simple dans Connect #795134), mais la perte de données est une perte de données, et je ne suis pas prêt à jouer. Le correctif est décrit dans KB #2969896 :CORRECTIF :La perte de données dans l'index clusterisé se produit lorsque vous exécutez l'index de construction en ligne dans SQL Server 2012.
Tout le monde n'a pas à se préoccuper de ce problème. Si vous n'exécutez pas Enterprise (ou une édition équivalente), vous ne pouvez pas effectuer de reconstructions parallèles ou en ligne en premier lieu (et il y a probablement des personnes sur Enterprise qui ne reconstruisent pas ou ne reconstruisent pas en ligne). Si vous avez MAXDOP à l'échelle de l'instance défini sur 1, ils ne peuvent pas être parallèles, sauf si vous le remplacez au niveau de l'instruction. Mais, si vous êtes sur 2012 ou 2014, exécutant une édition adéquate, et que vos reconstructions en ligne pourraient se dérouler en parallèle, vous êtes vulnérable à ce problème.
Comme je l'ai mentionné ci-dessus, ce problème peut se manifester dans SQL Server 2012 RTM, Service Pack 1 et même Service Pack 2, qui a été publié le 10 juin. Le bogue n'a été corrigé que longtemps après le gel du code SP2, donc SP2 ne n'incluez pas ce correctif ni aucun des correctifs de SP1 CU #10 ou #11. J'ai blogué à ce sujet ici. La branche RTM n'est officiellement plus prise en charge, vous n'y verrez donc pas de correctif. Le problème peut également se produire dans SQL Server 2014.
Des mises à jour cumulatives sont désormais disponibles pour SQL Server 2012 Service Pack 1 &2 ainsi que SQL Server 2014. Un bref résumé des options que je recommande :
Si votre succursale / @@VERSION est…
| …vous devriez… | ||||
|---|---|---|---|---|---|
| Ne rien faire ; vous avez déjà le correctif. | |||||
| Ne rien faire ; vous avez déjà le correctif. | |||||
| SQL Server 2014 RTM | |||||
| Ne rien faire ; vous avez déjà le correctif. | |||||
| * Si vous installez le correctif SP1 ou la mise à jour cumulative n° 11, puis installez SP2, vous annulerez ces modifications, y compris ce correctif. | |||||
Solutions pour le hotfix/CU averse
Étant donné que toutes les branches concernées (enfin, à l'exception de 2012 RTM) disposent d'un correctif à la demande et/ou d'une mise à jour cumulative qui résout le problème, la réponse simple consiste simplement à installer la mise à jour appropriée. Cependant, vous pouvez vous trouver dans un scénario où la politique de votre entreprise ou les cycles de test vous empêchent de déployer ces mises à jour rapidement, voire jamais. Alors, quelles autres options avez-vous ?
- Vous pouvez arrêter d'effectuer des reconstructions jusqu'à ce qu'un nouveau service pack soit disponible pour votre succursale (peut-être pouvez-vous simplement vous en tenir à
REORGANIZEpour le moment). Malheureusement, si vous êtes dans une entreprise "service pack uniquement", vos options sont très limitées :vous pouvez vous battre plus fort pour changer cette politique, ou vous pouvez attendre SQL Server 2012 Service Pack 3 (ce qui peut prendre beaucoup de temps, ou peut ne viendra tout simplement jamais - voir FAQ # 21 ici) ou SQL Server 2014 Service Pack 1 (que nous ne verrons probablement pas avant 2015). - Vous pouvez définir le
max degree of parallelismà l'échelle de l'instance à 1, mais cela peut avoir un effet négatif sur le reste de votre charge de travail - pensez à des choses comme DBCC multithread, des requêtes parallèles sur ou entre des tables partitionnées, et d'autres opérations où vous voudrez peut-être réduire le parallélisme mais pas l'éliminer complètement. De plus, ce paramètre n'affectera pas une reconstruction en ligne avec, par exemple, unMAXDOP = 8explicite codé en dur dans la commande, car cela remplacera lesp_configureréglage.
- Vous pouvez ajouter le
WITH (MAXDOP = 1)option manuellement à toutes vos commandes de reconstruction. (Remarque :vous n'avez pas à le faire pour les index XML, car ils s'exécutent intrinsèquement sur un seul thread, mais je l'appliquerais simplement à toutes les reconstructions pour des raisons de cohérence et pour éviter toute logique conditionnelle inutile.)
- Vous pouvez configurer vos tâches de maintenance d'index pour qu'elles s'exécutent en tant que connexion spécifique, puis utiliser le gouverneur de ressources pour créer un groupe de charge de travail qui limite le
MAX_DOPde cette connexion. à 1, peu importe ce qu'ils font. J'en ai un exemple dans le livre blanc de 2008 que j'ai écrit avec Boris Baryshnikov, Utilisation du gouverneur de ressources, dans la section intitulée "Limiter le parallélisme pour les travaux d'arrière-plan intensifs".
- Si vous utilisez la solution de maintenance d'index d'Ola Hallengren, vous pouvez ajouter le
@MaxDopparamètre à vos appels àdbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Si vous utilisez SQL Sentry Fragmentation Manager, vous pouvez dicter le niveau de
MAXDOPà utiliser sous Paramètres - et vous pouvez le faire à l'échelle de l'entreprise, par instance, par base de données ou même par index individuel (dans ce cas, vous voudrez probablement définir cela par instance, pour toutes les instances sans correctif disponible):
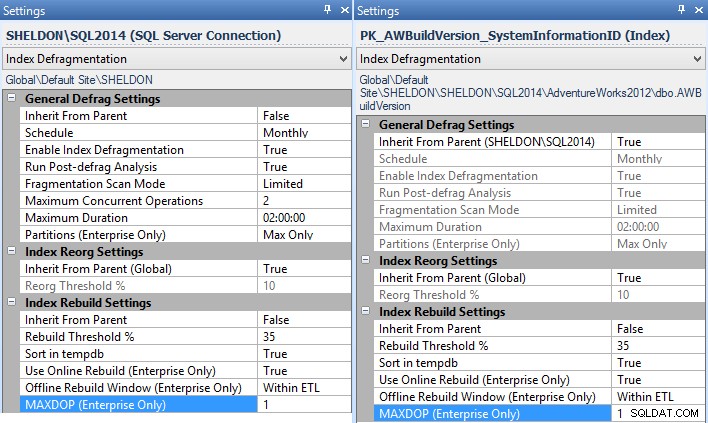
Paramètres de Fragmentation Manager pour l'instance (à gauche) et un index individuel (à droite). - Si vous utilisez des plans de maintenance pour vos reconstructions d'index, vous devrez les modifier pour utiliser les tâches d'exécution d'instructions T-SQL et écrire votre
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);commandes manuellement (il peut donc aussi bien passer à une solution automatisée). Voir, la tâche de reconstruction d'index n'a pas de propriété exposée pourMAXDOP, même s'il a été demandé à plusieurs reprises (plus récemment en 2012, par Alberto Morillo, et dès 2006, par Linchi Shea). Et regardez simplement toutes ces autres propriétés utiles qu'elles exposent, commeAdvSortInTempdb,ObjectTypeSelection, etTaskAllowesDatbaseSelection[sic !] :
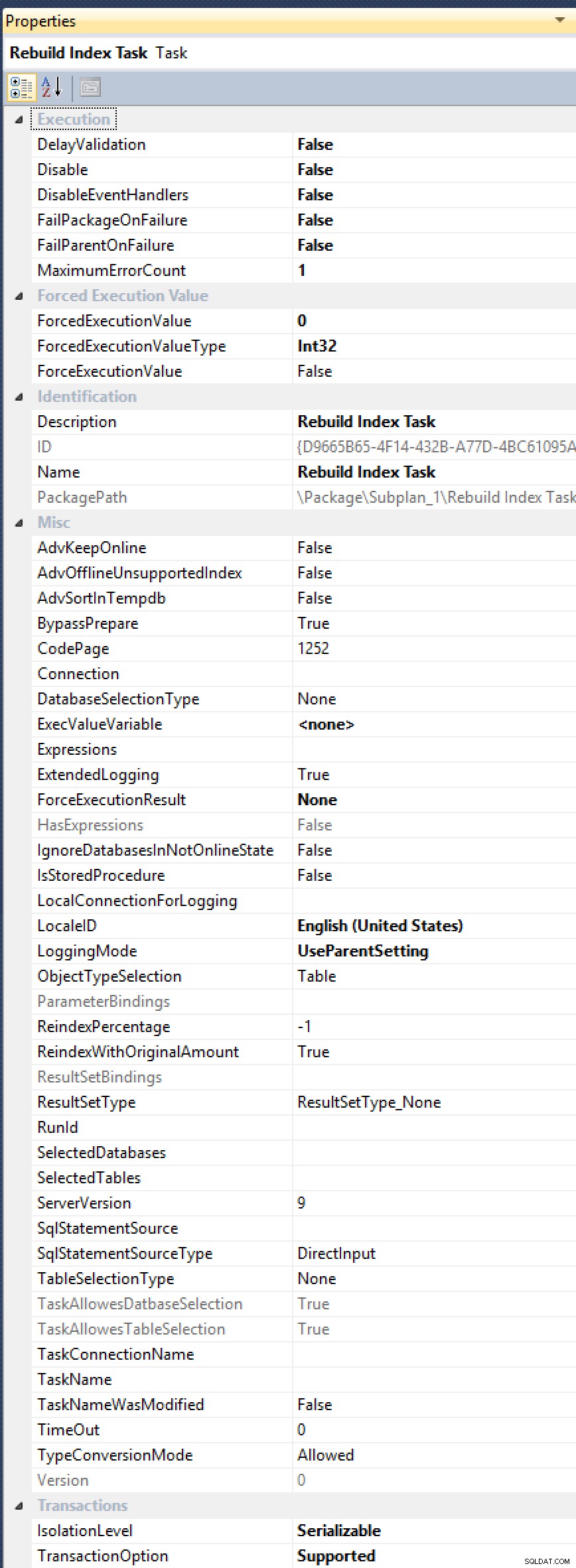
Toutes ces options, mais toujours pas de remède contre MAXDOP.



