Eh bien, pour répondre à votre question pourquoi SQL Server fait cela, la réponse est que la requête n'est pas compilée dans un ordre logique, chaque instruction est compilée sur son propre mérite, donc lorsque le plan de requête pour votre instruction select est généré, l'optimiseur ne sait pas que @val1 et @Val2 deviendront respectivement 'val1' et 'val2'.
Lorsque SQL Server ne connaît pas la valeur, il doit faire une estimation du nombre de fois que cette variable apparaîtra dans la table, ce qui peut parfois conduire à des plans sous-optimaux. Mon point principal est que la même requête avec des valeurs différentes peut générer des plans différents. Imaginez cet exemple simple :
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Tout ce que j'ai fait ici est de créer une table simple et d'ajouter 1000 lignes avec des valeurs de 1 à 10 pour la colonne val , cependant 1 apparaît 991 fois et les 9 autres n'apparaissent qu'une seule fois. La prémisse étant cette requête :
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Il serait plus efficace de simplement scanner la table entière, que d'utiliser l'index pour une recherche, puis de faire 991 recherches de signets pour obtenir la valeur de Filler , cependant avec seulement 1 ligne la requête suivante :
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
sera plus efficace de faire une recherche d'index, et une seule recherche de signet pour obtenir la valeur de Filler (et l'exécution de ces deux requêtes le ratifiera)
Je suis à peu près certain que la coupure pour une recherche et une recherche de signet varie en fait en fonction de la situation, mais elle est assez faible. En utilisant le tableau d'exemple, avec un peu d'essais et d'erreurs, j'ai trouvé que j'avais besoin du Val colonne pour avoir 38 lignes avec la valeur 2 avant que l'optimiseur n'effectue une analyse complète de la table via une recherche d'index et une recherche de signet :
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Ainsi, pour cet exemple, la limite est de 3,7 % des lignes correspondantes.
Étant donné que la requête ne sait pas combien de lignes correspondront lorsque vous utilisez une variable, elle doit deviner, et le moyen le plus simple consiste à trouver le nombre total de lignes et à le diviser par le nombre total de valeurs distinctes dans la colonne, donc dans cet exemple le nombre estimé de lignes pour WHERE val = @Val est 1000/10 =100, l'algorithme réel est plus complexe que cela, mais par exemple, cela suffira. Ainsi, lorsque nous examinons le plan d'exécution pour :
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
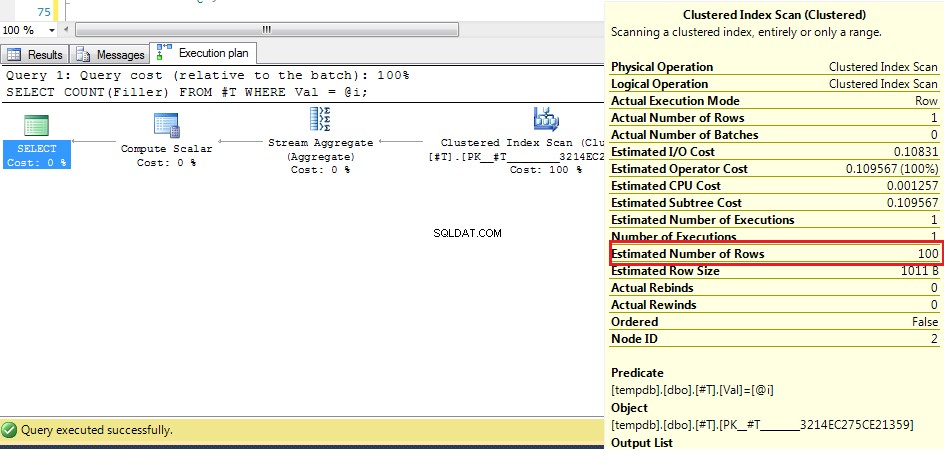
Nous pouvons voir ici (avec les données d'origine) que le nombre estimé de lignes est de 100, mais que les lignes réelles sont de 1. D'après les étapes précédentes, nous savons qu'avec plus de 38 lignes, l'optimiseur optera pour un balayage d'index clusterisé sur un index seek, donc puisque la meilleure estimation du nombre de lignes est supérieure à cela, le plan pour une variable inconnue est un parcours d'index clusterisé.
Juste pour prouver davantage la théorie, si nous créons le tableau avec 1000 lignes de nombres 1-27 uniformément réparties (donc le nombre de lignes estimé sera d'environ 1000/27 =37.037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Ensuite, relancez la requête, nous obtenons un plan avec une recherche d'index :
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
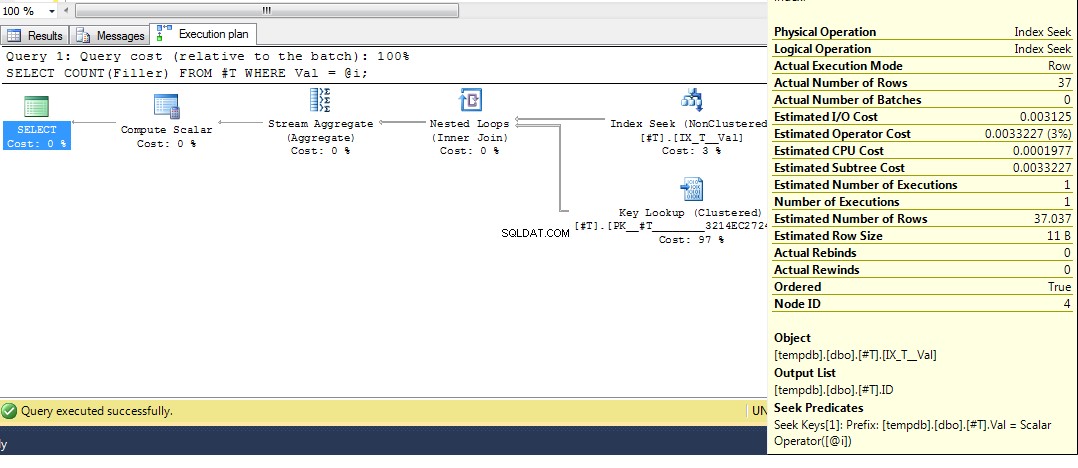
J'espère donc que cela couvre de manière assez complète pourquoi vous obtenez ce plan. Maintenant, je suppose que la question suivante est de savoir comment forcer un plan différent, et la réponse est d'utiliser l'indicateur de requête OPTION (RECOMPILE) , pour forcer la requête à se compiler au moment de l'exécution lorsque la valeur du paramètre est connue. Revenir aux données d'origine, où le meilleur plan pour Val = 2 est une recherche, mais l'utilisation d'une variable produit un plan avec un parcours d'index, nous pouvons exécuter :
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
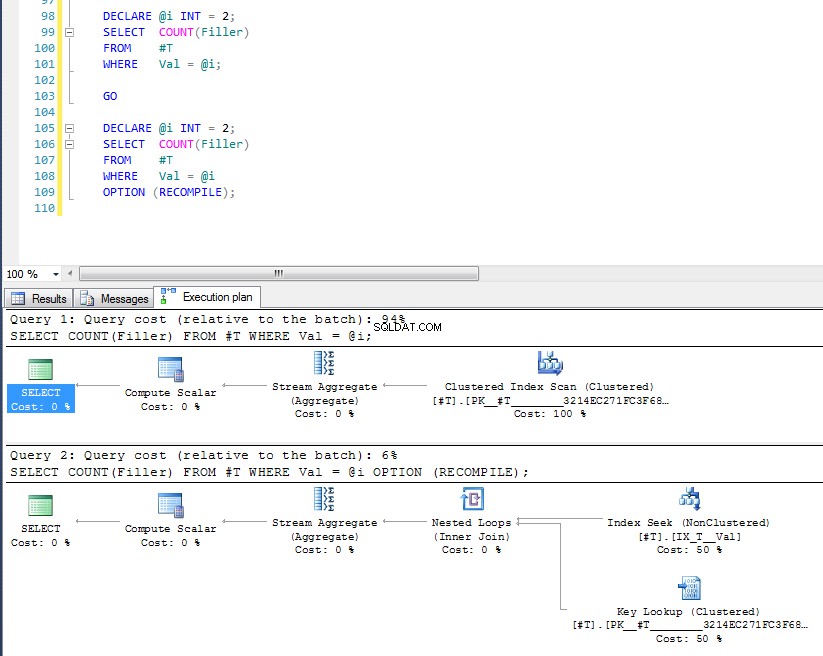
Nous pouvons voir que ce dernier utilise la recherche d'index et la recherche de clé car il a vérifié la valeur de la variable au moment de l'exécution, et le plan le plus approprié pour cette valeur spécifique est choisi. Le problème avec OPTION (RECOMPILE) cela signifie que vous ne pouvez pas tirer parti des plans de requête mis en cache, il y a donc un coût supplémentaire pour compiler la requête à chaque fois.