Benjamin Nevarez est un consultant indépendant basé à Los Angeles, en Californie, spécialisé dans le réglage et l'optimisation des requêtes SQL Server. Il est l'auteur de "SQL Server 2014 Query Tuning &Optimization" et "Inside the SQL Server Query Optimizer" et co-auteur de "SQL Server 2012 Internals". Avec plus de 20 ans d'expérience dans les bases de données relationnelles, Benjamin a également été conférencier lors de nombreuses conférences SQL Server, notamment le PASS Summit, SQL Server Connections et SQLBits. Le blog de Benjamin se trouve à l'adresse https://www.benjaminnevarez.com et il est également joignable par e-mail à l'adresse admin de benjaminnevarez dot com et sur twitter à @BenjaminNevarez.
Alors que la plupart des informations, des blogs et de la documentation sur SQL Server 2014 se sont concentrés sur Hekaton et d'autres nouvelles fonctionnalités, peu de détails ont été fournis sur le nouvel estimateur de cardinalité. Actuellement, BOL n'en parle qu'indirectement dans la section Quoi de neuf (moteur de base de données), affirmant que SQL Server 2014 "inclut des améliorations substantielles du composant qui crée et optimise les plans de requête", et le ALTER DATABASE indique comment activer ou désactiver son comportement. Heureusement, nous pouvons obtenir des informations supplémentaires en lisant le document de recherche Testing Cardinality Estimation Models in SQL Server par Campbell Fraser et al. Bien que l'article se concentre sur le processus d'assurance qualité du nouveau modèle d'estimation, il offre également une introduction de base au nouvel estimateur de cardinalité et la motivation de sa refonte.
Alors, qu'est-ce qu'un estimateur de cardinalité ? Un estimateur de cardinalité est le composant du processeur de requête dont le travail consiste à estimer le nombre de lignes renvoyées par les opérations relationnelles dans une requête. Ces informations, ainsi que d'autres données, sont utilisées par l'optimiseur de requête pour sélectionner un plan d'exécution efficace. L'estimation de la cardinalité est intrinsèquement inexacte, car il s'agit d'un modèle mathématique qui repose sur des informations statistiques. Il est également basé sur plusieurs hypothèses qui, bien que non documentées, sont connues depuis des années - certaines d'entre elles incluent les hypothèses d'uniformité, d'indépendance, de confinement et d'inclusion. Une brève description de ces hypothèses suit.
- Uniformité . Utilisé lorsque la distribution d'un attribut est inconnue, par exemple, à l'intérieur des lignes de plage dans une étape d'histogramme ou lorsqu'un histogramme n'est pas disponible.
- Indépendance . Utilisé lorsque les attributs d'une relation sont indépendants, sauf si une corrélation entre eux est connue.
- Confinement . Utilisé lorsque deux attributs peuvent être identiques, ils sont supposés être identiques.
- Inclusion . Utilisé lors de la comparaison d'un attribut avec une constante, on suppose qu'il y a toujours une correspondance.
Il est intéressant de noter que j'ai récemment parlé de certaines des limites de ces hypothèses lors de ma dernière conférence au PASS Summit, intitulée Defeating the Limitations of the Query Optimizer. Pourtant, j'ai été surpris de lire dans l'article que les auteurs admettent que, selon leur expérience pratique, ces hypothèses sont "souvent incorrectes".
L'estimateur de cardinalité actuel a été écrit avec l'ensemble du processeur de requêtes pour SQL Server 7.0, qui a été publié en décembre 1998. Évidemment, ce composant a fait face à de multiples changements au cours de plusieurs années et de plusieurs versions de SQL Server, y compris des correctifs, des ajustements et des extensions pour prendre en charge l'estimation de cardinalité pour les nouvelles fonctionnalités T-SQL. Alors vous vous demandez peut-être pourquoi remplacer un composant utilisé avec succès depuis environ 15 ans ?
Pourquoi un nouvel estimateur de cardinalité
Le document explique certaines des raisons de la refonte, notamment :
- Adapter l'estimateur de cardinalité aux nouveaux modèles de charge de travail
- Les modifications apportées à l'estimateur de cardinalité au fil des ans ont rendu le composant difficile à "déboguer, prédire et comprendre".
- Il était difficile d'essayer d'améliorer le modèle actuel avec l'architecture actuelle. Une nouvelle conception a donc été créée, axée sur la séparation des tâches consistant à (a) décider comment calculer une estimation particulière et (b) effectuer réellement le calcul. .
Je ne sais pas si plus de détails sur le nouvel estimateur de cardinalité seront publiés par Microsoft. Après tout, peu de détails ont été publiés sur l'ancien estimateur de cardinalité en 15 ans ; par exemple, comment une estimation de cardinalité spécifique est calculée. D'autre part, il existe de nouveaux événements étendus que nous pouvons utiliser pour résoudre les problèmes d'estimation de cardinalité, ou simplement pour explorer son fonctionnement. Ces événements incluent query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors et query_rpc_set_cardinality .
Planifier les régressions
Une préoccupation majeure qui vient à l'esprit avec un changement aussi important à l'intérieur de l'optimiseur de requête est les régressions de plan. La peur des régressions de plan a été considérée comme le plus grand obstacle aux améliorations de l'optimiseur de requêtes. Les régressions sont des problèmes introduits après l'application d'un correctif à l'optimiseur de requête et parfois appelées le classique "deux torts font un droit". Cela peut arriver lorsque deux mauvaises estimations, par exemple l'une surestimant une valeur et l'autre la sous-estimant, s'annulent, donnant heureusement une bonne estimation. Corriger une seule de ces valeurs peut maintenant conduire à une mauvaise estimation qui peut avoir un impact négatif sur le choix de la sélection du plan, provoquant une régression.
Pour aider à éviter les régressions liées au nouvel estimateur de cardinalité, SQL Server fournit un moyen de l'activer ou de le désactiver, car cela dépend du niveau de compatibilité de la base de données. Cela peut être modifié à l'aide de ALTER DATABASE déclaration, comme indiqué précédemment. La définition d'une base de données au niveau de compatibilité 120 utilisera le nouvel estimateur de cardinalité, tandis qu'un niveau de compatibilité inférieur à 120 utilisera l'ancien estimateur de cardinalité. De plus, une fois que vous utilisez un estimateur de cardinalité spécifique, vous pouvez utiliser deux indicateurs de trace pour passer à l'autre. Bien que pour le moment je ne vois pas les indicateurs de trace documentés nulle part, ils sont mentionnés dans le cadre de la description de la query_optimizer_force_both_cardinality_estimation_behaviors événement prolongé. L'indicateur de trace 2312 peut être utilisé pour activer le nouvel estimateur de cardinalité, tandis que l'indicateur de trace 9481 peut être utilisé pour le désactiver. Vous pouvez même utiliser les indicateurs de trace pour une requête spécifique en utilisant le QUERYTRACEON indice (bien qu'il ne soit pas encore documenté si cela sera pris en charge non plus).
Exemples
Enfin, le document mentionne également certains scénarios testés comme la clé primaire surpeuplée, la jointure simple ou le problème de clé ascendante. Il montre également comment les auteurs ont expérimenté plusieurs scénarios (ou variations de modèles) et, dans certains cas, « relâché » certaines des hypothèses formulées par l'estimateur de cardinalité, par exemple, dans le cas de l'hypothèse d'indépendance, en passant d'une indépendance complète à une corrélation complète. et quelque chose entre les deux jusqu'à ce que de bons résultats soient trouvés.
Bien qu'aucun détail ne soit fourni sur l'article, je décide de commencer à tester certains de ces scénarios pour essayer de comprendre comment fonctionne le nouvel estimateur de cardinalité. Pour l'instant, je vais vous montrer un exemple utilisant l'hypothèse d'indépendance et les touches ascendantes. J'ai également testé l'hypothèse d'uniformité, mais jusqu'à présent, je n'ai trouvé aucune différence d'estimation.
Commençons par l'exemple de l'hypothèse d'indépendance. Voyons d'abord le comportement actuel. Pour cela, assurez-vous d'utiliser l'ancien estimateur de cardinalité en exécutant l'instruction suivante sur la base de données AdventureWorks2012 :
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Exécutez ensuite :
SELECT * FROM Person.Address WHERE City = 'Burbank';
Nous obtenons une estimation de 196 enregistrements, comme indiqué ci-dessous :

De la même manière, la déclaration suivante obtiendra une estimation de 194 :
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Si nous utilisons les deux prédicats, nous avons la requête suivante, qui aura un nombre estimé de lignes de 1,93862 (arrondi à 2 lignes si vous utilisez SQL Sentry Plan Explorer) :
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Cette valeur est calculée en supposant une indépendance totale des deux prédicats, qui utilise la formule (196 * 194) / 19614.0 (où 19614 est le nombre total de lignes dans la table). L'utilisation d'une corrélation totale devrait nous donner une estimation de 194, car tous les enregistrements avec le code postal 91502 appartiennent à Burbank. Le nouvel estimateur de cardinalité estime une valeur qui ne suppose pas une indépendance totale ou une corrélation totale. Passez au nouvel estimateur de cardinalité à l'aide de l'instruction suivante :
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Exécuter à nouveau la même instruction donnera une estimation de 19,3931 lignes, ce que vous pouvez voir comme une valeur entre l'hypothèse d'indépendance totale et la corrélation totale (arrondie à 19 lignes dans Plan Explorer). La formule utilisée est sélectivité du filtre le plus sélectif * SQRT(sélectivité du filtre suivant le plus sélectif) ou (194/19614.0) * SQRT(196/19614.0) * 19614 ce qui donne 19.393 :

Si vous avez activé le nouvel estimateur de cardinalité au niveau de la base de données et souhaitez le désactiver pour une requête spécifique afin d'éviter une régression de plan, vous pouvez utiliser l'indicateur de trace 9481 comme expliqué précédemment :
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Remarque :L'indicateur de requête QUERYTRACEON est utilisé pour appliquer un indicateur de trace au niveau de la requête et n'est actuellement pris en charge que dans un nombre limité de scénarios. Pour plus d'informations sur l'indicateur de requête QUERYTRACEON, vous pouvez consulter https://support.microsoft.com/kb/2801413.
Examinons maintenant le problème de la clé ascendante, un sujet que j'ai expliqué plus en détail dans cet article. La recommandation traditionnelle de Microsoft pour résoudre ce problème est de mettre à jour manuellement les statistiques après le chargement des données, comme expliqué ici - qui décrit le problème de la manière suivante :
Les statistiques sur les colonnes clés croissantes ou décroissantes, telles que les colonnes IDENTITY ou d'horodatage en temps réel, peuvent nécessiter des mises à jour de statistiques plus fréquentes que celles effectuées par l'optimiseur de requête. Les opérations d'insertion ajoutent de nouvelles valeurs aux colonnes croissantes ou décroissantes. Le nombre de lignes ajoutées peut être trop petit pour déclencher une mise à jour des statistiques. Si les statistiques ne sont pas à jour et que les requêtes sélectionnent à partir des dernières lignes ajoutées, les statistiques actuelles n'auront pas d'estimations de cardinalité pour ces nouvelles valeurs. Cela peut entraîner des estimations de cardinalité inexactes et ralentir les performances des requêtes. Par exemple, une requête qui sélectionne à partir des dates de commande client les plus récentes aura des estimations de cardinalité inexactes si les statistiques ne sont pas mises à jour pour inclure les estimations de cardinalité pour les dates de commande client les plus récentes.
La recommandation dans mon article était d'utiliser les indicateurs de trace 2389 et 2390, qui ont été publiés pour la première fois par Ian Jose dans son article Ascending Keys and Auto Quick Corrected Statistics. Vous pouvez lire mon article pour une explication et un exemple sur la façon d'utiliser ces indicateurs de trace pour éviter ce problème. Ces indicateurs de trace fonctionnent toujours sur SQL Server 2014 CTP2. Mais mieux encore, ils ne sont plus nécessaires si vous utilisez le nouvel estimateur de cardinalité.
En utilisant le même exemple dans mon post :
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Insérez quelques données :
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Depuis que nous avons créé un index, nous avons juste de nouvelles statistiques. L'exécution de la requête suivante créera une bonne estimation de 35 lignes :
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Si nous insérons de nouvelles données :
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Vous pouvez voir l'estimation avec l'ancien estimateur de cardinalité comme indiqué ci-dessous :
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Étant donné que le petit nombre d'enregistrements insérés n'était pas suffisant pour déclencher une mise à jour automatique de l'objet de statistiques, l'histogramme actuel n'a pas connaissance des nouveaux enregistrements ajoutés et l'optimiseur de requête utilise une estimation de 1 ligne. En option, vous pouvez utiliser les indicateurs de trace 2389 et 2390 pour vous aider à obtenir une meilleure estimation. Mais si vous essayez la même requête avec le nouvel estimateur de cardinalité, vous obtenez l'estimation suivante :
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
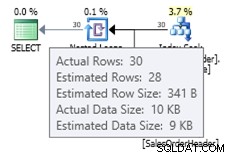
Dans ce cas, nous obtenons une meilleure estimation que l'ancien estimateur de cardinalité (ou nous obtenons la même estimation qu'en utilisant les indicateurs de trace 2389 ou 2390). La valeur estimée de 27,9631 (là encore, arrondie à 28 par Plan Explorer) est calculée à l'aide des informations de densité de l'objet de statistiques multipliées par le nombre de lignes du tableau ; c'est-à-dire 0,0008992806 * 31095. La valeur de densité peut être obtenue en utilisant :
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Enfin, gardez à l'esprit que rien de mentionné dans cet article n'est documenté, et c'est le comportement que j'ai observé jusqu'à présent dans SQL Server 2014 CTP2. Tout cela pourrait changer dans une version CTP ou RTM ultérieure du produit.