Présentation
Peu importe à quel point nous essayons de concevoir et de développer des applications, des erreurs se produiront toujours. Il existe deux catégories générales - les erreurs de syntaxe ou de logique peuvent être soit des erreurs de programmation, soit les conséquences d'une conception incorrecte de la base de données. Sinon, vous risquez d'obtenir une erreur en raison d'une entrée utilisateur erronée.
T-SQL (le langage de programmation SQL Server) permet de gérer les deux types d'erreurs. Vous pouvez déboguer l'application et décider ce que vous devez faire pour éviter les bogues à l'avenir.
La plupart des applications nécessitent que vous consigniez les erreurs, que vous mettiez en œuvre un rapport d'erreurs convivial et, si possible, que vous traitiez les erreurs et que vous poursuiviez l'exécution de l'application.
Les utilisateurs gèrent les erreurs au niveau de l'instruction. Cela signifie que lorsque vous exécutez un lot de commandes SQL et que le problème se produit dans la dernière instruction, tout ce qui précède ce problème sera validé dans la base de données en tant que transactions implicites. Ce n'est peut-être pas ce que vous désirez.
Les bases de données relationnelles sont optimisées pour l'exécution d'instructions par lots. Ainsi, vous devez exécuter un lot d'instructions comme une seule unité et faire échouer toutes les instructions si une instruction échoue. Vous pouvez accomplir cela en utilisant des transactions. Cet article se concentrera à la fois sur la gestion des erreurs et sur les transactions, car ces sujets sont étroitement liés.
Gestion des erreurs SQL
Pour simuler des exceptions, nous devons les produire de manière reproductible. Commençons par l'exemple le plus simple - la division par zéro :
SELECT 1/0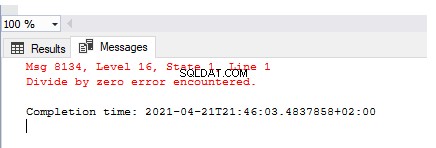
La sortie décrit l'erreur générée - Diviser par zéro l'erreur rencontrée . Mais cette erreur n'a pas été gérée, enregistrée ou personnalisée pour produire un message convivial.
La gestion des exceptions commence par placer les instructions que vous souhaitez exécuter dans le bloc BEGIN TRY…END TRY.
SQL Server gère (intercepte) les erreurs dans le bloc BEGIN CATCH…END CATCH, où vous pouvez entrer une logique personnalisée pour la journalisation ou le traitement des erreurs.
L'instruction BEGIN CATCH doit suivre immédiatement l'instruction END TRY. L'exécution est ensuite transmise du bloc TRY au bloc CATCH à la première occurrence d'erreur.
Ici, vous pouvez décider comment gérer les erreurs, si vous souhaitez enregistrer les données sur les exceptions déclenchées ou créer un message convivial.
SQL Server possède des fonctions intégrées qui peuvent vous aider à extraire les détails de l'erreur :
- ERROR_NUMBER() :renvoie le nombre d'erreurs SQL.
- ERROR_SEVERITY() :renvoie le niveau de gravité qui indique le type de problème rencontré et son niveau. Les niveaux 11 à 16 peuvent être gérés par l'utilisateur.
- ERROR_STATE() :renvoie le numéro d'état de l'erreur et donne plus de détails sur l'exception levée. Vous utilisez le numéro d'erreur pour rechercher dans la base de connaissances Microsoft des détails d'erreur spécifiques.
- ERROR_PROCEDURE() :renvoie le nom de la procédure ou du déclencheur dans lequel l'erreur a été déclenchée, ou NULL si l'erreur ne s'est pas produite dans la procédure ou le déclencheur.
- ERROR_LINE() :renvoie le numéro de la ligne à laquelle l'erreur s'est produite. Il peut s'agir du numéro de ligne des procédures ou des déclencheurs ou du numéro de ligne du lot.
- ERROR_MESSAGE() :renvoie le texte du message d'erreur.
L'exemple suivant montre comment gérer les erreurs. Le premier exemple contient la Division par zéro erreur, alors que la deuxième déclaration est correcte.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Si la deuxième instruction est exécutée sans gestion des erreurs (SELECT 'Corriger le texte'), elle réussira.
Puisque nous implémentons la gestion personnalisée des erreurs dans le bloc TRY-CATCH, l'exécution du programme est passée au bloc CATCH après l'erreur dans la première instruction, et la seconde instruction n'a jamais été exécutée.
De cette façon, vous pouvez modifier le texte donné à l'utilisateur et mieux contrôler ce qui se passe si une erreur se produit. Par exemple, nous enregistrons les erreurs dans une table de journal pour une analyse plus approfondie.
Utilisation des transactions
La logique métier peut déterminer que l'insertion de la première instruction échoue lorsque la deuxième instruction échoue, ou que vous devrez peut-être répéter les modifications de la première instruction en cas d'échec de la deuxième instruction. L'utilisation de transactions vous permet d'exécuter un lot d'instructions comme une seule unité qui échoue ou réussit.
L'exemple suivant illustre l'utilisation des transactions.
Tout d'abord, nous créons une table pour tester les données stockées. Ensuite, nous utilisons deux transactions à l'intérieur du bloc TRY-CATCH pour simuler ce qui se passe si une partie de la transaction échoue.
Nous utiliserons l'instruction CATCH avec l'instruction XACT_STATE(). La fonction XACT_STATE() est utilisée pour vérifier si la transaction existe toujours. Dans le cas où la transaction serait annulée automatiquement, la ROLLBACK TRANSACTION produirait une nouvelle exception.
Ayez un butin au code ci-dessous :
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
L'image montre les valeurs de la table TEST_TRAN et les messages d'erreur :
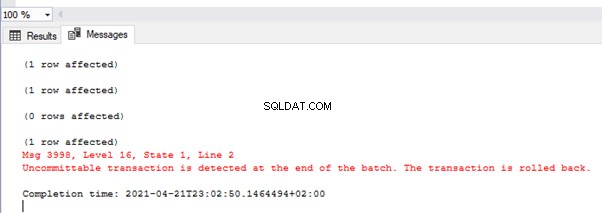
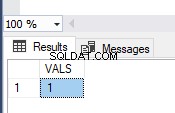
Comme vous le voyez, seule la première valeur a été validée. Dans la deuxième transaction, nous avons eu une erreur de conversion de type dans la deuxième ligne. Ainsi, tout le lot a été annulé.
De cette façon, vous pouvez contrôler quelles données entrent dans la base de données et comment les lots sont traités.
Génération d'un message d'erreur personnalisé en SQL
Parfois, nous voulons créer des messages d'erreur personnalisés. Habituellement, ils sont destinés à des scénarios lorsque nous savons qu'un problème peut survenir. Nous pouvons produire nos propres messages personnalisés indiquant qu'un problème s'est produit sans montrer de détails techniques. Pour cela, nous utilisons le mot clé THROW.
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
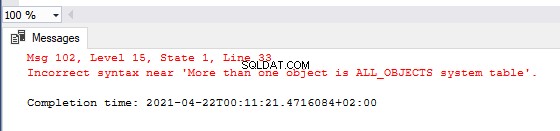
Ou, nous aimerions disposer d'un catalogue de messages d'erreur personnalisés pour la catégorisation et la cohérence de la surveillance et des rapports d'erreurs. SQL Server nous permet de prédéfinir le code, la gravité et l'état du message d'erreur.
Une procédure stockée appelée "sys.sp_addmessage" est utilisée pour ajouter des messages d'erreur personnalisés. Nous pouvons l'utiliser pour appeler le message d'erreur à plusieurs endroits.
Nous pouvons appeler RAISERROR et envoyer le numéro de message en tant que paramètre au lieu de coder en dur les mêmes détails d'erreur à plusieurs endroits dans le code.
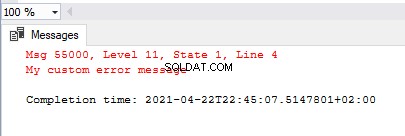
En exécutant le code sélectionné ci-dessous, nous ajoutons l'erreur personnalisée dans SQL Server, l'augmentons, puis utilisons sys.sp_dropmessage pour supprimer le message d'erreur défini par l'utilisateur :
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
En outre, nous pouvons afficher tous les messages dans SQL Server en exécutant le formulaire de requête ci-dessous. Notre message d'erreur personnalisé est visible en tant que premier élément du jeu de résultats :
SELECT * FROM master.dbo.sysmessages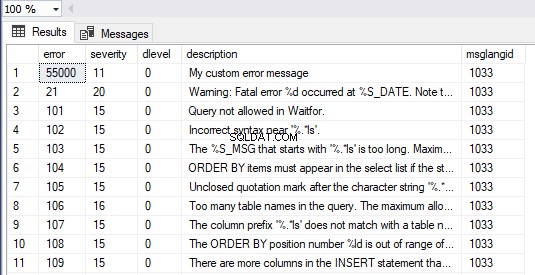
Créer un système pour consigner les erreurs
Il est toujours utile de consigner les erreurs pour un débogage et un traitement ultérieurs. Vous pouvez également placer des déclencheurs sur ces tables enregistrées et même configurer un compte de messagerie et faire preuve d'un peu de créativité pour avertir les gens lorsqu'une erreur se produit.
Pour consigner les erreurs, nous créons une table appelée DBError_Log , qui peut être utilisé pour stocker les données détaillées du journal :
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Pour simuler le mécanisme de journalisation, nous créons le GenError procédure stockée qui génère la Division par zéro erreur et enregistre l'erreur dans le DBError_Log tableau :
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
Le DBError_Log table contient toutes les informations dont nous avons besoin pour déboguer l'erreur. Il fournit également des informations supplémentaires sur la procédure à l'origine de l'erreur. Bien que cela puisse sembler être un exemple trivial, vous pouvez étendre ce tableau avec des champs supplémentaires ou l'utiliser pour le remplir avec des exceptions créées sur mesure.
Conclusion
Si nous voulons maintenir et déboguer des applications, nous voulons au moins signaler que quelque chose s'est mal passé et également le consigner sous le capot. Lorsque nous avons une application de niveau production utilisée par des millions d'utilisateurs, une gestion des erreurs cohérente et rapportable est la clé pour déboguer les problèmes d'exécution.
Bien que nous puissions enregistrer l'erreur d'origine dans le journal des erreurs de la base de données, les utilisateurs devraient voir un message plus convivial. Ainsi, ce serait une bonne idée d'implémenter des messages d'erreur personnalisés qui sont envoyés aux applications appelantes.
Quelle que soit la conception que vous implémentez, vous devez consigner et gérer les exceptions utilisateur et système. Cette tâche n'est pas difficile avec SQL Server, mais vous devez la planifier dès le début.
L'ajout d'opérations de gestion des erreurs sur des bases de données déjà en cours d'exécution en production peut impliquer une refactorisation sérieuse du code et des problèmes de performances difficiles à trouver.