Quels problèmes allons-nous prendre en compte ?
Si le serveur notifie "il n'y a plus d'espace sur le lecteur E" - aucune analyse approfondie n'est nécessaire. Nous ne prendrons pas en compte les erreurs dont la solution ressort clairement du texte du message et pour lesquelles Google lance immédiatement un lien vers MSDN avec la solution.
Examinons les problèmes qui ne sont pas évidents pour Google, comme par exemple une baisse brutale des performances ou l'absence de connexion. Considérez les principaux outils de personnalisation et d'analyse. Voyons où se trouvent les journaux et autres informations utiles. En fait, je vais essayer de rassembler dans un seul article toutes les informations nécessaires pour un démarrage rapide.
Tout d'abord
Nous allons commencer par les questions les plus fréquentes et les examiner séparément.
Si votre base de données a soudainement, sans raison apparente, commencé à fonctionner lentement, mais que vous n'avez rien changé - tout d'abord, mettez à jour les statistiques et reconstruisez les index.
Sur Internet, il existe de nombreuses méthodes comme celle-ci, des exemples de scripts sont fournis. Je suppose que toutes ces méthodes sont destinées aux professionnels. Eh bien, je vais décrire la manière la plus simple :vous n'avez besoin que d'une souris pour l'implémenter.
Abréviations
- SSMS est une application de Microsoft SQL Server Management Studio. À partir de la version 2016, il est disponible gratuitement sur le site Web de MS en tant qu'application autonome. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler est une application de "SQL Server Profiler" installée avec SSMS.
- Performance Monitor est un composant logiciel enfichable du panneau de configuration qui vous permet de surveiller les compteurs de performances, de consigner et d'afficher l'historique des mesures.
Mise à jour des statistiques à l'aide d'un "plan de service":
- exécuter SSMS ;
- se connecter à un serveur requis ;
- développer l'arborescence dans l'inspecteur d'objets :gestion\plans de maintenance (plans de service) ;
- cliquez avec le bouton droit sur le nœud et sélectionnez "Assistant de plan de maintenance" ;
- dans l'assistant, marquez les tâches requises :reconstruire l'index et mettre à jour les statistiques
- vous pouvez marquer les deux tâches à la fois ou créer deux plans de maintenance avec une tâche dans chacun (voir les « remarques importantes » ci-dessous);
- en outre, nous vérifions une base de données requise (ou plusieurs bases de données). Nous faisons cela pour chaque tâche (si deux tâches sont choisies, il y aura deux dialogues avec le choix d'une base de données);
- Suivant, Suivant, Terminer.
Après ces actions, un "plan de maintenance" sera créé (non exécuté). Vous pouvez l'exécuter manuellement en cliquant dessus avec le bouton droit de la souris et en sélectionnant "Exécuter". Alternativement, vous configurez le lancement via SQL Agent.
Remarques importantes :
- La mise à jour des statistiques est une opération non bloquante. Vous pouvez l'exécuter en mode de travail.
- La reconstruction de l'index est une opération bloquante. Vous ne pouvez l'exécuter qu'en dehors des heures de travail. Il existe une exception — l'édition Entreprise du serveur permet l'exécution d'une « reconstruction en ligne ». Cette option peut être activée dans les paramètres de la tâche. Veuillez noter qu'il y a une coche dans toutes les éditions, mais cela ne fonctionne que dans Enterprise.
- Bien sûr, ces tâches doivent être effectuées régulièrement. Je vous propose un moyen simple de déterminer la fréquence à laquelle vous le faites :
– Dès les premiers problèmes, exécuter le plan de maintenance ;
– Si cela a aidé, attendez que les problèmes se reproduisent (généralement jusqu'à la prochaine clôture mensuelle/calcul de salaire/etc. des transactions en masse) ;
– La période résultante d'un fonctionnement normal sera votre point de référence ;
– Par exemple, configurez l'exécution du plan de maintenance deux fois plus souvent.
Le serveur est lent :que devez-vous faire ?
Les ressources utilisées par le serveur
Comme tout autre programme, le serveur a besoin de temps processeur, de données sur le disque, de quantité de RAM et de bande passante réseau.
Le gestionnaire de tâches vous aidera à évaluer le manque d'une ressource donnée en première approximation, aussi terrible que cela puisse paraître.
Processeur Charger
Même un écolier peut vérifier l'utilisation dans le gestionnaire. Nous devons juste nous assurer que si le processeur est chargé, il s'agit du processus sqlserver.exe.
Si tel est votre cas, vous devez vous rendre dans l'analyse de l'activité des utilisateurs pour comprendre exactement ce qui a causé la charge (voir ci-dessous).
Disque Loa d
Beaucoup de gens ne regardent que la charge CPU mais oublient que le SGBD est un magasin de données. Les volumes de données augmentent, les performances du processeur augmentent tandis que la vitesse du disque dur est à peu près la même. Avec les SSD, la situation est meilleure, mais y stocker des téraoctets coûte cher.
Il s'avère que je rencontre souvent des situations où le système de disque devient le goulot d'étranglement, plutôt que le processeur.
Pour les disques, les métriques suivantes sont importantes :
- longueur moyenne de la file d'attente (opérations d'E/S en attente, nombre) ;
- Vitesse de lecture-écriture (en Mb/s).
La version serveur du Gestionnaire des tâches, en règle générale (selon la version du système), affiche les deux. Si ce n'est pas le cas, exécutez le composant logiciel enfichable Performance Monitor (moniteur système). Nous sommes intéressés par les compteurs suivants :
- Disque physique (logique)/Temps moyen de lecture (écriture)
- Disque physique (logique)/Longueur moyenne de la file d'attente du disque
- Disque physique (logique)/Vitesse du disque
Pour plus de détails, vous pouvez lire les manuels du fabricant, par exemple ici :social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
En bref :
- La file d'attente ne doit pas dépasser 1. De courtes rafales sont autorisées si elles diminuent rapidement. Les rafales peuvent être différentes selon votre système. Pour un simple miroir RAID de deux disques durs, la file d'attente de plus de 10-20 est un problème. Pour une bibliothèque cool avec une super mise en cache, j'ai vu des rafales allant jusqu'à 600-800 qui ont été résolues instantanément sans causer de retards.
- Le taux de change normal dépend également du type de système de disque. Le disque dur habituel (de bureau) transmet à 50-100 Mo/s. Une bonne bibliothèque de disques – à 500 Mo/s et plus. Pour les petites opérations aléatoires, la vitesse est moindre. Cela peut être votre point de référence.
- Ces paramètres doivent être considérés comme un tout. Si votre bibliothèque transmet 50 Mo/s et qu'une file d'attente de 50 opérations s'aligne, il est évident que quelque chose ne va pas avec le matériel. Si la file d'attente s'aligne lorsque la transmission est proche d'un maximum - très probablement, les disques ne sont pas à blâmer - ils ne peuvent tout simplement pas faire plus - nous devons chercher un moyen de réduire la charge.
- La charge doit être vérifiée séparément sur les disques (s'il y en a plusieurs) et comparée à l'emplacement des fichiers du serveur. Le gestionnaire de tâches peut afficher les fichiers les plus utilisés. Cela peut être utilisé pour s'assurer que la charge est causée par le SGBD.
Qu'est-ce qui peut causer des problèmes de système de disque :
- problèmes avec le matériel
- cache épuisé, les performances ont chuté de façon spectaculaire ;
- le système de disque est utilisé par autre chose ;
- Manque de RAM. Échange. Le cache s'est détérioré, les performances ont chuté (voir la section sur la RAM ci-dessous).
- La charge des utilisateurs a augmenté. Il est nécessaire d'évaluer le travail des utilisateurs (requête problématique/nouvelle fonctionnalité/augmentation du nombre d'utilisateurs/augmentation de la quantité de données/etc).
- Fragmentation des données de la base de données (voir la reconstruction de l'index ci-dessus), fragmentation des fichiers système.
- Le système de disque a atteint ses capacités maximales.
Dans le cas de la dernière option, ne jetez pas le matériel immédiatement. Parfois, vous pouvez tirer un peu plus du système si vous abordez le problème avec sagesse. Vérifiez l'emplacement des fichiers système pour vous assurer qu'ils sont conformes aux exigences recommandées :
- Ne mélangez pas les fichiers du système d'exploitation avec les fichiers de données de la base de données. Stockez-les sur différents supports physiques afin que le système n'entre pas en concurrence avec le SGBD pour les E/S.
- La base de données se compose de deux types de fichiers :les données (*.mdf, *.ndf) et les journaux (*.ldf).
Les fichiers de données, en règle générale, sont principalement utilisés pour la lecture. Les logs servent à l'écriture (où l'écriture est consécutive). Il est donc recommandé de stocker les logs et les données sur des supports physiques différents afin que la journalisation n'interrompe pas la lecture des données (en règle générale, l'opération d'écriture prime sur la lecture). - MS SQL peut utiliser des "tables temporaires" pour le traitement des requêtes. Ils sont stockés dans la base de données système tempdb. Si vous avez une charge élevée sur les fichiers de cette base de données, vous pouvez essayer de la rendre sur un support physiquement séparé.
Pour résumer le problème de l'emplacement des fichiers, utilisez le principe de « diviser pour mieux régner ». Évaluez les fichiers auxquels vous accédez et essayez de les distribuer sur différents supports. Utilisez également les fonctionnalités des systèmes RAID. Par exemple, les lectures RAID-5 sont plus rapides que les écritures, ce qui est bon pour les fichiers de données.
Explorons comment récupérer des informations sur les performances des utilisateurs :qui fabrique quoi et combien de ressources sont consommées
J'ai réparti les tâches d'audit de l'activité des utilisateurs dans les groupes suivants :
- Tâches d'analyse d'une demande particulière.
- Tâches d'analyse de la charge de l'application dans des conditions spécifiques (par exemple, lorsqu'un utilisateur clique sur un bouton dans une application tierce compatible avec la base de données).
- Tâches d'analyse de la situation actuelle.
Examinons chacun d'eux en détail.
Avertissement
L'analyse des performances nécessite une compréhension approfondie de la structure et des principes de fonctionnement du serveur de base de données et du système d'exploitation. C'est pourquoi la lecture de ces seuls articles ne fera pas de vous un professionnel.
Les critères et les compteurs considérés dans les systèmes réels dépendent grandement les uns des autres. Par exemple, une charge élevée du disque dur est souvent causée par un manque de RAM. Même si vous effectuez quelques mesures, cela ne suffit pas pour évaluer raisonnablement les problèmes.
Le but des articles est d'introduire l'essentiel sur des exemples simples. Vous ne devriez pas considérer mes recommandations comme un guide. Je vous recommande de les utiliser comme tâches d'entraînement qui peuvent expliquer le flux des pensées.
J'espère que vous apprendrez à rationaliser vos conclusions sur les performances du serveur en chiffres.
Au lieu de dire "le serveur ralentit", vous fournirez des valeurs spécifiques d'indicateurs spécifiques.
Analyser un P articulaire R demande
Le premier point est assez simple, attardons-nous dessus brièvement. Nous examinerons certains problèmes moins évidents.
En plus des résultats de la requête, SSMS permet de récupérer des informations supplémentaires sur l'exécution de la requête :
- Vous pouvez obtenir le plan de requête en cliquant sur les boutons "Afficher le plan d'exécution estimé" et "Inclure le plan d'exécution réel". La différence entre eux est que le plan d'estimation est construit sans exécution de requête. Ainsi, les informations sur le nombre de lignes traitées seront estimées. Dans le plan réel, il y aura à la fois des données estimées et réelles. De fortes divergences de ces valeurs indiquent que les statistiques ne sont pas pertinentes. Cependant, l'analyse du plan fait l'objet d'un autre article - jusqu'à présent, nous n'irons pas plus loin.
- Nous pouvons obtenir des mesures des coûts de processeur et des opérations de disque du serveur. Pour ce faire, il est nécessaire d'activer l'option SET. Vous pouvez le faire soit dans la boîte de dialogue "Options de la requête", comme ceci :
Soit avec les commandes directes SET dans la requête :
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDEn conséquence, nous obtiendrons des données sur le temps passé à la compilation et à l'exécution, ainsi que sur le nombre d'opérations sur le disque.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.J'aimerais attirer votre attention sur le temps de compilation, les lectures logiques 96 et les lectures physiques 5. Lors de l'exécution de la même requête pour la deuxième fois et plus tard, les lectures physiques peuvent diminuer et la recompilation peut ne pas être nécessaire. De ce fait, il arrive souvent que la requête soit exécutée plus rapidement la deuxième fois et les suivantes que la première fois. La raison, comme vous le comprenez, est de mettre en cache les données et les plans de requête compilés.
- Le bouton « Inclure les statistiques du client » affiche les informations sur l'échange réseau, le nombre d'opérations exécutées et le temps d'exécution total, y compris les coûts d'échange réseau et de traitement par un client. L'exemple montre qu'il faut plus de temps pour exécuter la requête la première fois :
- Dans SSMS 2016, il y a le bouton « Inclure les statistiques de requête en direct ». Il affiche l'image comme dans le cas du plan de requête mais contient les chiffres non aléatoires des lignes traitées, qui changent à l'écran lors de l'exécution de la requête. L'image est très claire - des flèches clignotantes et des chiffres défilants, vous pouvez immédiatement voir où le temps est perdu. Le bouton fonctionne également pour SQL Server 2014 et versions ultérieures.
Pour résumer :
- Vérifiez les coûts du processeur à l'aide de SET STATISTICS TIME ON.
- Opérations sur le disque :SET STATISTICS IO ON. N'oubliez pas que la lecture logique est une opération de lecture effectuée dans le cache disque sans accéder physiquement au système de disque. La "lecture physique" prend beaucoup plus de temps.
- Évaluez le volume de trafic réseau à l'aide de "Inclure les statistiques client".
- Analysez l'algorithme d'exécution de la requête par le plan d'exécution à l'aide de « Inclure le plan d'exécution réel » et « Inclure les statistiques de requête en direct ».
Analyser la charge de l'application
Ici, nous allons utiliser SQL Server Profiler. Après le lancement et la connexion au serveur, il est nécessaire de sélectionner les événements du journal. Pour ce faire, exécutez le profilage avec un modèle de suivi standard. Sur le Général dans l'onglet Utiliser le modèle champ, sélectionnez Standard (par défaut) et cliquez sur Exécuter .
La méthode la plus compliquée consiste à ajouter/supprimer des filtres ou des événements vers/depuis le modèle sélectionné. Ces options se trouvent dans le deuxième onglet du menu de la boîte de dialogue. Pour voir la gamme complète d'événements et de colonnes possibles à sélectionner, sélectionnez Afficher tous les événements et Afficher toutes les colonnes cases à cocher.

Nous aurons besoin des événements suivants :
- Procédures stockées \ RPC :terminées
- TSQL\SQL:BatchCompleted
Ces événements surveillent tous les appels SQL externes au serveur. Ils apparaissent après l'achèvement du traitement de la requête. Il existe des événements similaires qui gardent une trace du démarrage de SQL Server :
- Procédures stockées \ RPC :Démarrage
- TSQL \ SQL:BatchStarting
Cependant, nous n'avons pas besoin de ces procédures car elles ne contiennent pas d'informations sur les ressources du serveur consacrées à l'exécution de la requête. Il est évident que ces informations ne sont disponibles qu'après l'achèvement du processus d'exécution. Ainsi, les colonnes avec des données sur le CPU, les lectures, les écritures dans les *Événements de démarrage seront vides.
Les événements suivants peuvent également nous intéresser, mais nous ne les activerons pas pour l'instant :
- Stored Procedures \ SP:Starting (*Completed) surveille l'appel interne à la procédure stockée non pas depuis le client, mais dans la requête en cours ou une autre procédure.
- Procédures stockées \ SP:StmtStarting (*Completed) suit le début de chaque instruction dans la procédure stockée. S'il y a un cycle dans la procédure, le nombre d'événements pour les commandes dans le cycle sera égal au nombre d'itérations dans le cycle.
- TSQL \ SQL:StmtStarting (*Completed) surveille le début de chaque instruction dans le SQL-batch. S'il y a plusieurs commandes dans votre requête, chacune d'elles contiendra un événement. Ainsi, cela fonctionne pour les commandes situées dans la requête.
Ces événements sont pratiques pour surveiller le processus d'exécution.
Par C colonnes
Les colonnes à sélectionner sont clairement indiquées dans le nom du bouton. Nous aurons besoin des éléments suivants :
- TextData, BinaryData contiennent le texte de la requête.
- Le processeur, les lectures, les écritures et la durée affichent les données de consommation des ressources.
- StartTime, EndTime est l'heure de début et de fin du processus d'exécution. Ils sont pratiques pour le tri.
Ajoutez d'autres colonnes en fonction de vos préférences.
Les filtres de colonne… ouvre la boîte de dialogue de configuration des filtres d'événements. Si vous êtes intéressé par l'activité d'un utilisateur particulier, vous pouvez définir le filtre par le numéro SID ou le nom d'utilisateur. Malheureusement, dans le cas de la connexion de l'application via le serveur d'applications avec l'extraction des connexions, la surveillance de l'utilisateur particulier devient plus compliquée.
Vous pouvez utiliser des filtres pour sélectionner uniquement les requêtes compliquées (Durée> X), les requêtes qui provoquent une écriture intensive (Écritures> Y), ainsi que les sélections de contenu de requête, etc.
De quoi d'autre avons-nous besoin de la part du profileur ? Bien sûr, le plan d'exécution !
Il est nécessaire d'ajouter l'événement « Performance \ Showplan XML Statistics Profile » au traçage. Lors de l'exécution de notre requête, nous obtiendrons l'image suivante :
Le texte de la requête :
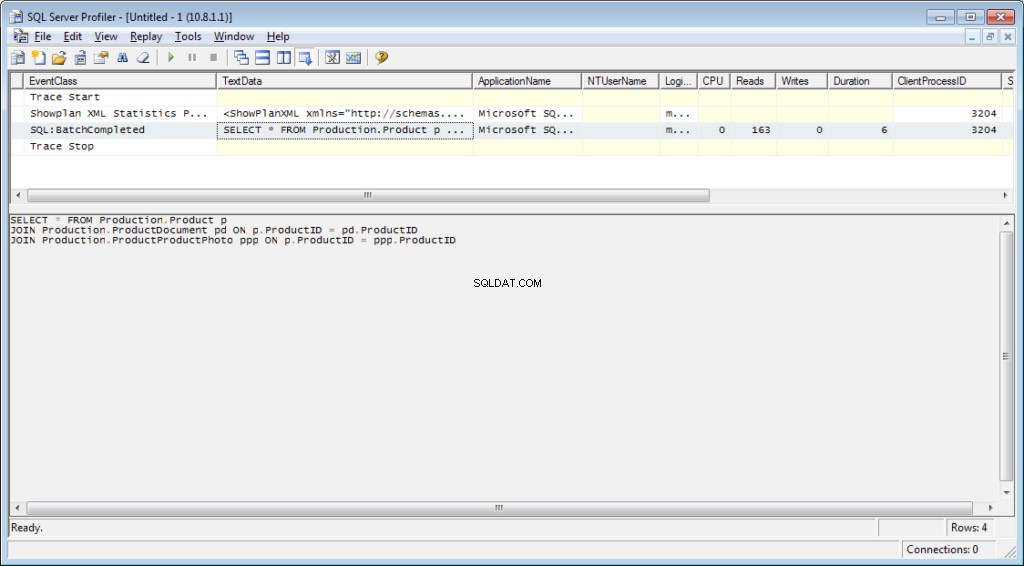
Le plan d'exécution :
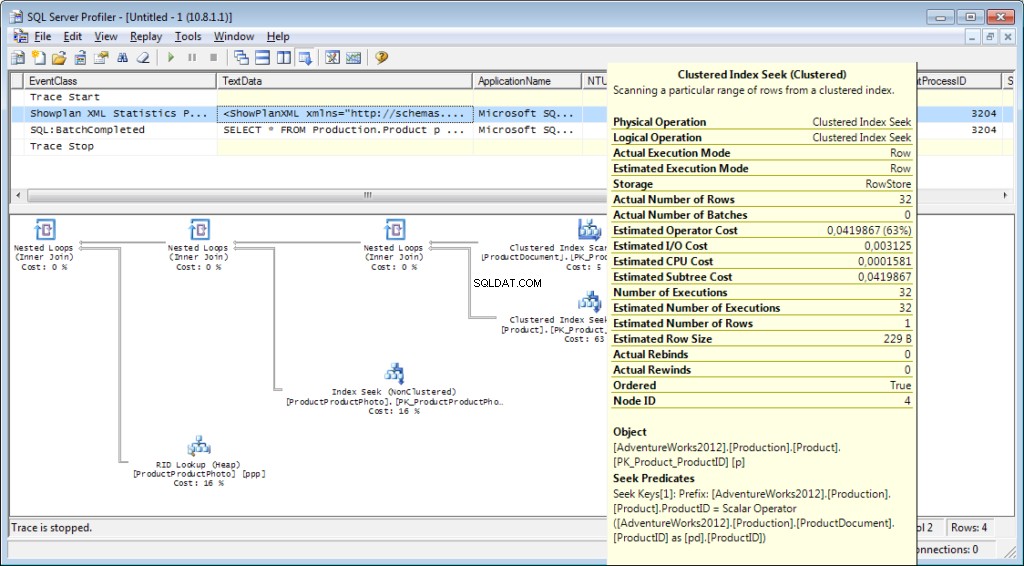
Et ce n'est pas tout
Il est possible d'enregistrer une trace dans un fichier ou une table de base de données. Les paramètres de traçage peuvent être stockés en tant que modèle personnel pour une exécution rapide. Vous pouvez exécuter la trace sans profileur, en utilisant simplement un code T-SQL et les procédures sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Vous pouvez trouver un exemple ici. Cette approche peut être utile, par exemple, pour démarrer automatiquement le stockage d'une trace dans un fichier selon un calendrier. Vous pouvez avoir un aperçu sournois du profileur pour voir comment utiliser ces commandes. Vous pouvez exécuter deux traces et, dans l'une d'elles, suivre ce qui se passe lorsque la seconde démarre. Vérifiez qu'il n'y a pas de filtre par la colonne "ApplicationName" sur le profileur lui-même.
La liste des événements surveillés par le profileur est très longue et ne se limite pas à la réception de textes de requête. Il existe des événements qui suivent l'analyse complète, la recompilation, la croissance automatique, le blocage et bien plus encore.
Analyser l'activité des utilisateurs sur le serveur
Il existe différentes situations. Une requête peut rester en « exécution » pendant une longue période et il n'est pas clair si elle sera terminée ou non. Je voudrais analyser la requête problématique séparément ; cependant, nous devons d'abord déterminer quelle est la requête. Il est inutile de l'attraper avec un profileur - nous avons déjà raté l'événement de départ, et on ne sait pas combien de temps attendre pour que le processus soit terminé.
Déterminons-le
Vous avez peut-être entendu parler de "Moniteur d'activité". Ses éditions supérieures ont des fonctionnalités vraiment riches. Comment peut-il nous aider ? Activity Monitor comprend de nombreuses fonctionnalités utiles et intéressantes. Nous obtiendrons tout ce dont nous avons besoin des vues et des fonctions du système. Le moniteur lui-même est utile car vous pouvez définir le profileur dessus et voir les requêtes qu'il effectue.
Nous aurons besoin :
- dm_exec_sessions fournit des informations sur les sessions des utilisateurs connectés. Dans notre article, les champs utiles sont ceux qui identifient un utilisateur (login_name, login_time, host_name, program_name, …) et les champs avec les informations sur les ressources dépensées (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests fournit des informations sur les requêtes exécutées en ce moment.
- session_id est un identifiant de la session à lier à la vue précédente.
- start_time est l'heure d'exécution de la vue.
- command est un champ qui contient un type de la commande exécutée. Pour les requêtes des utilisateurs, c'est select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset fournissent des informations pour récupérer le texte de la requête :handle, ainsi que la position de début et de fin dans le texte de la requête, c'est-à-dire la partie en cours d'exécution (pour le cas où votre requête contient plusieurs commandes).
- plan_handle est un handle du plan généré.
- blocking_session_id indique le numéro de la session qui a causé le blocage s'il y a des blocs qui empêchent l'exécution de la requête
- wait_type, wait_time, wait_resource sont des champs contenant des informations sur la raison et la durée de l'attente. Pour certains types d'attentes, par exemple, le verrouillage des données, il est nécessaire d'indiquer en plus un code pour la ressource bloquée.
- percent_complete est le pourcentage d'achèvement. Malheureusement, il n'est disponible que pour les commandes dont la progression est clairement prévisible (par exemple, sauvegarde ou restauration).
- cpu_time, lectures, écritures, logical_reads, grant_query_memory sont des coûts de ressources.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) sont des fonctions d'obtention du texte et du plan d'exécution. Ci-dessous, nous examinerons un exemple de son utilisation.
- dm_exec_query_stats est un résumé des statistiques sur l'exécution des requêtes. Il affiche la requête, le nombre de ses exécutions et le volume de ressources dépensées.
Remarques importantes
La liste ci-dessus n'est qu'une petite partie. Une liste complète de toutes les vues et fonctions du système est décrite dans la documentation. De plus, il y a une belle image montrant un schéma des liens entre les principaux objets.
Le texte de la requête, son plan et les statistiques d'exécution sont des données stockées dans le cache de procédure. Ils sont disponibles pendant l'exécution. Ensuite, la disponibilité n'est pas garantie et dépend de la charge du cache. Oui, le cache peut être nettoyé manuellement. Parfois, il est recommandé lorsque les plans d'exécution "se retournent". Pourtant, il y a beaucoup de nuances.
Le champ "commande" n'a pas de sens pour les demandes des utilisateurs, car nous pouvons obtenir le texte intégral. Cependant, il est très important d'obtenir des informations sur les processus du système. En règle générale, ils effectuent certaines tâches internes et ne disposent pas du texte SQL. Pour de tels processus, les informations sur la commande sont le seul indice du type d'activité.
Dans les commentaires de l'article précédent, il y avait une question sur ce dans quoi le serveur est impliqué quand il ne devrait pas fonctionner. La réponse sera probablement dans le sens de ce champ. Dans ma pratique, le champ "commande" a toujours fourni quelque chose d'assez compréhensible pour les processus système actifs :autoshrink / autogrow / checkpoint / logwriter / etc.
Comment l'utiliser
Nous allons passer à la partie pratique. Je donnerai plusieurs exemples de son utilisation. Les possibilités de serveur ne sont pas limitées - vous pouvez penser à vos propres exemples.
Exemple 1. Quel processus consomme CPU/lectures/écritures/mémoire
Examinez d'abord les sessions qui consomment le plus de ressources, par exemple, le processeur. Vous pouvez trouver ces informations dans sys.dm_exec_sessions. Cependant, les données sur le processeur, y compris les lectures et les écritures, sont cumulatives. Cela signifie que le nombre contient le total pour tout le temps de connexion. Il est clair que l'utilisateur qui s'est connecté il y a un mois et qui n'a pas été déconnecté aura une valeur plus élevée. Cela ne signifie pas qu'ils surchargent le système.
Un code avec l'algorithme suivant peut résoudre ce problème :
- Faites une sélection et stockez-la dans une table temporaire
- Attendez un peu de temps
- Effectuer une sélection pour la deuxième fois
- Comparez ces résultats. Leur différence indiquera les coûts dépensés à l'étape 2.
- Pour plus de commodité, la différence peut être divisée par la durée de l'étape 2 afin d'obtenir les "coûts par seconde" moyens.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 J'utilise deux tables dans le code :#tmp – pour la première sélection, et #tmp1 – pour la seconde. Lors de la première exécution, le script crée et remplit #tmp et #tmp1 à un intervalle d'une seconde, puis effectue d'autres tâches. Lors des exécutions suivantes, le script utilise les résultats de l'exécution précédente comme base de comparaison. Ainsi, la durée de l'étape 2 sera égale à la durée de votre attente entre les exécutions du script.
Essayez de l'exécuter, même sur le serveur de production. Le script créera uniquement des "tables temporaires" (disponibles dans la session en cours et supprimées lorsqu'elles sont désactivées) et n'a pas de fil.
Ceux qui n'aiment pas exécuter une requête dans MS SSMS peuvent l'encapsuler dans une application écrite dans leur langage de programmation préféré. Je vais vous montrer comment faire cela dans MS Excel sans une seule ligne de code.
Dans le menu Données, connectez-vous au serveur. Si vous êtes invité à sélectionner une table, sélectionnez-en une au hasard. Cliquez sur Suivant et sur Terminer jusqu'à ce que la boîte de dialogue Importation de données s'affiche. Dans cette fenêtre, vous devez cliquer sur Propriétés. Dans Propriétés, il est nécessaire de remplacer un type de commande par la valeur SQL et d'insérer notre requête modifiée dans le champ de texte Commande.
Vous devrez modifier un peu la requête :
- Ajouter « SET NOCOUNT ON »
- Remplacer les tables temporaires par des tables variables
- Le délai durera moins de 1 seconde. Les champs avec des valeurs moyennes ne sont pas obligatoires
La requête modifiée pour Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Résultat :
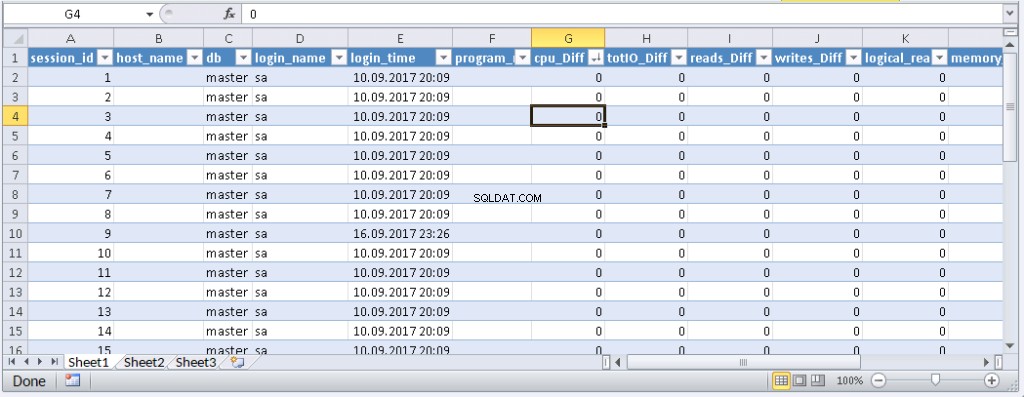
Lorsque des données apparaissent dans Excel, vous pouvez les trier selon vos besoins. Pour mettre à jour les informations, cliquez sur "Actualiser". Dans les paramètres du classeur, vous pouvez mettre "mise à jour automatique" dans une période de temps spécifiée et "mise à jour au début". Vous pouvez enregistrer le fichier et le transmettre à vos collègues. Ainsi, nous avons créé un outil pratique et simple.
Exemple 2. À quoi une session dépense-t-elle des ressources ?
Maintenant, nous allons déterminer ce que font réellement les sessions de problèmes. Pour ce faire, utilisez sys.dm_exec_requests et les fonctions pour recevoir le texte de la requête et le plan de requête.
La requête et le plan d'exécution par numéro de session
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Insérez le numéro de session dans la requête et exécutez-la. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
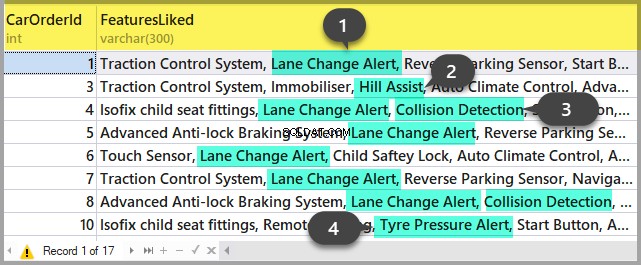
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.