La réplication de base de données est la technologie permettant de distribuer les données du serveur principal aux serveurs secondaires. La réplication fonctionne sur le concept maître-esclave où la base de données maître distribue les données à un ou plusieurs serveurs esclaves. La réplication peut être configurée entre plusieurs instances SQL Server sur le même serveur, OU elle peut être configurée entre plusieurs serveurs de base de données au sein du même centre de données ou de centres de données géographiquement séparés.
L'utilisation de la réplication SQL Server présente deux principaux avantages :
- Grâce à la réplication, nous pouvons obtenir des données quasiment en temps réel qui peuvent être utilisées à des fins de création de rapports. Par exemple, lorsque vous souhaitez séparer la charge OLTP intensive en écriture sur un serveur et la charge intensive en lecture sur un autre serveur, vous pouvez configurer la réplication pour maintenir la synchronisation des données sur les deux serveurs.
- Le deuxième avantage est que vous pouvez programmer la réplication pour qu'elle s'exécute à une heure précise. Par exemple, si vous souhaitez que le serveur de rapports contienne les données de la journée terminée, vous pouvez planifier l'instantané de réplication en conséquence. Nous n'avons pas besoin d'écrire de logique supplémentaire pour traiter les données actuelles.
La réplication offre une grande flexibilité. En utilisant la réplication, nous pouvons filtrer les lignes et également répliquer le sous-ensemble de données de n'importe quelle table. Nous pouvons modifier les données répliquées ou répliquer uniquement la mise à jour et l'insertion et ignorer les suppressions. Nous pouvons également répliquer les données d'un autre système de base de données comme Oracle.
Composants de la réplication
Il existe sept composants principaux de la réplication SQL Server. Voici la liste :
- Éditeur.
- Distributeur.
- Abonné.
- Articles.
- Publication.
- Poussez l'abonnement.
- Abonnement pull.
Voici les détails :
Articles
Un article est un objet de base de données, tel qu'une table SQL ou une procédure stockée. Comme je l'ai mentionné ci-dessus, en utilisant la réplication, nous pouvons filtrer les données ou répliquer la colonne de table sélectionnée. Par conséquent, les colonnes ou les lignes de table sont considérées comme des articles.
Publications
Les articles ne peuvent pas être reproduits tant qu'ils ne font pas partie de la publication. Publication est le groupe des objets Articles/Base de données. Il représente également le jeu de données qui sera répliqué par SQL Server.
Éditeur
Publisher contient une base de données principale contenant les données à publier. Il détermine quelles données doivent être distribuées sur tous les abonnés.
Distributeur
Le distributeur est le pont entre l'éditeur et l'abonné. Le distributeur rassemble toutes les données publiées et les conserve jusqu'à leur envoi à tous les abonnés. C'est un pont entre l'éditeur et l'abonné. Il prend en charge plusieurs éditeurs et concept d'abonné. Il n'est pas obligatoire de configurer le distributeur sur une instance SQL distincte ou sur un serveur distinct. Si nous ne le configurons pas, l'éditeur peut agir en tant que distributeur. Les organisations qui ont une réplication à grande échelle peuvent configurer le distributeur sur un système distinct.
Abonnés
L'abonné est la fin de la source ou la destination vers laquelle les données ou la publication répliquée seront transmises. En réplication, il y a un éditeur, il peut avoir plusieurs abonnés.
Poussez l'abonnement
Dans un abonnement push, l'éditeur met à jour les données de l'abonné. Dans un abonnement Push, l'abonné est passif. L'éditeur envoie des articles ou des publications à tous ses abonnés. En fonction des besoins de l'organisation, lors de la création de l'assistant de réplication, sur l'écran, vous pouvez sélectionner l'abonnement à utiliser. La réplication des transactions et la réplication peer-to-peer utilisent l'abonnement Push pour maintenir la disponibilité des données en temps réel.
Abonnement pull
Dans un abonnement Pull, tous les abonnés demandent les nouvelles données ou les données mises à jour à son éditeur. Dans un abonnement pull, nous pouvons contrôler quelles données ou modifications de données sont nécessaires aux abonnés. C'est utile lorsque nous n'avons pas besoin des données modifiées immédiatement.
Types de réplication
SQL Server prend en charge trois types de réplication :
- Réplication transactionnelle.
- Réplication d'instantané.
- Fusionner la réplication.
Réplication transactionnelle
La réplication transactionnelle, toute modification de schéma, les modifications de données se produisant sur la base de données de l'éditeur seront répliquées sur la base de données de l'abonné. Chaque fois que des opérations de mise à jour, de suppression ou d'insertion se produisent sur la base de données de l'éditeur, les modifications sont suivies et ces modifications sont envoyées aux bases de données des abonnés. La réplication transactionnelle n'envoie qu'une quantité limitée de données sur un réseau. De plus, les modifications sont presque en temps réel, elles peuvent donc être utilisées pour configurer le site DR ou pour étendre les opérations de création de rapports. La réplication transactionnelle est idéale dans les situations suivantes :
- Lorsque vous souhaitez configurer un système dans lequel les modifications apportées à l'éditeur doivent être appliquées immédiatement aux abonnés.
- L'éditeur a des INSERTS, des MISES À JOUR et des SUPPRESSIONS élevés.
- Lorsque vous souhaitez configurer une signification de réplication hétérogène, un éditeur ou des abonnés pour des bases de données non SQL Server, telles qu'Oracle.
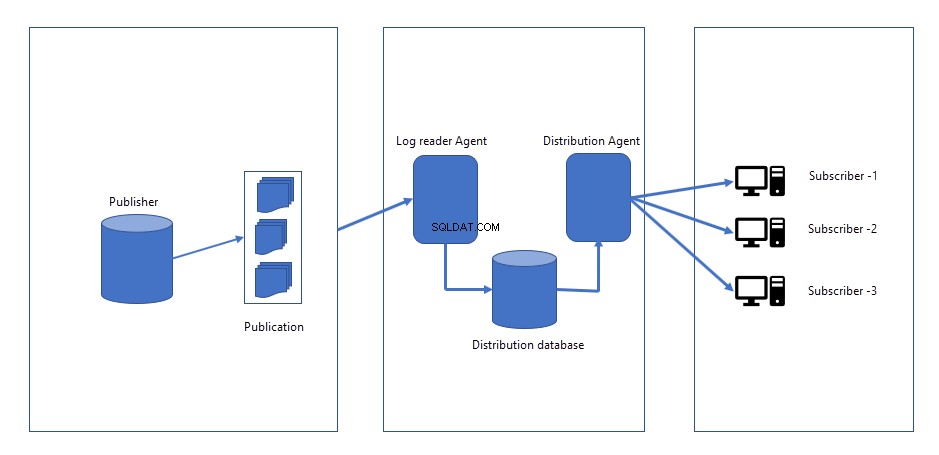
Lorsque des modifications sont apportées à la base de données de l'éditeur, les modifications sont consignées dans un fichier journal sur la base de données de l'éditeur. Site distributeur/éditeur, deux emplois seront créés.
- Agent d'instantané :Le travail de l'agent d'instantané génère l'instantané du schéma, les données des objets que nous voulons répliquer ou publier. Les fichiers de l'instantané peuvent être enregistrés sur le serveur Publisher ou sur un emplacement réseau. Lorsque nous lançons la réplication pour la première fois, elle crée un instantané et l'applique à tous les abonnés. L'agent d'instantané reste inactif jusqu'à ce qu'il soit déclenché manuellement ou programmé pour s'exécuter à une heure précise.
- Agent de lecture du journal :Le travail de l'agent de lecture du journal s'exécute en continu. Il lit les modifications (INSERT, UPDATES et DELETES) survenues dans le journal des transactions de la base de données de l'éditeur et les envoie à un agent de distribution.
- Agent de distribution :Une fois les modifications extraites de l'agent de lecture du journal, l'agent de distribution envoie toutes les modifications aux abonnés.
Lorsque nous configurons la réplication transactionnelle, elle effectue les activités suivantes
- Il démarre en prenant le premier instantané des données de publication et des objets de base de données et l'instantané appliqué aux abonnés.
- L'agent lecteur de journal surveille en permanence le T-Log de l'éditeur et si des modifications surviennent, il les envoie au distributeur ou directement aux abonnés.
L'image suivante représente le fonctionnement de la réplication transactionnelle :
Avantages :
- La réplication des transactions peut être utilisée comme serveur SQL de secours, ou elle peut être utilisée pour l'équilibrage de charge ou la séparation du système de création de rapports et du système OLTP.
- Le serveur de l'éditeur réplique les données sur le serveur de l'abonné avec une faible latence.
- À l'aide de la réplication transactionnelle, la réplication au niveau de l'objet peut être mise en œuvre.
- La réplication transactionnelle peut être appliquée lorsque vous avez moins de données à protéger et que vous devez disposer d'un plan de récupération rapide des données.
Inconvénients :
- Une fois la réplication établie, les modifications de schéma sur l'éditeur ne s'appliquent pas sur le serveur de l'abonné. Nous devons apporter ces modifications manuellement en générant un nouvel instantané et en l'appliquant aux abonnés.
- Si nous changeons les serveurs, nous devons reconfigurer la réplication.
- Si la réplication transactionnelle est utilisée comme configuration DR, nous devons basculer manuellement.
Réplication d'instantané
La réplication d'instantané génère une image/un instantané complet de la publication selon un calendrier défini et envoie les fichiers d'instantané aux abonnés. Lorsque la réplication d'instantané se produit, les données de destination sont remplacées par un nouvel instantané. La réplication de snapshot est la meilleure option lorsque les données sont moins volatiles. Par exemple, les tables maîtres comme City, Zipcode, Pincode sont les meilleurs candidats pour la réplication d'instantané.
Lors de la configuration de la réplication d'instantané, les composants importants suivants sont définis :
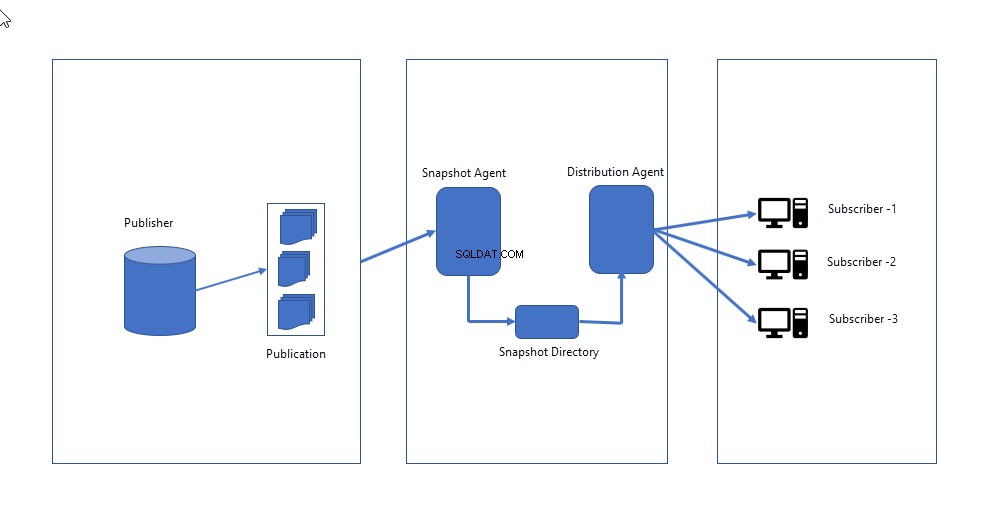
- Agent d'instantané :Il crée une image complète du schéma et des données définies dans la publication et l'envoie au distributeur. L'agent d'instantané reste inactif jusqu'à ce qu'il soit déclenché manuellement OU programmé pour s'exécuter à une heure précise.
- Agent distributeur :Il envoie les fichiers d'instantané aux abonnés et applique le schéma et les données en remplaçant celui existant.
La réplication de snapshot effectue les activités suivantes :
- Selon le calendrier défini, l'agent d'instantané place un verrou partagé sur le schéma et les données à publier.
- Instantané complet des données publiées copié du côté distributeur. L'agent d'instantané crée trois fichiers
- Fichier vers le schéma de base de données créé des données publiées.
- Fichier BCP pour exporter des données dans des tables SQL
- Fichiers d'index pour exporter les données d'index.
- Une fois les fichiers créés, l'agent d'instantané libère les verrous partagés sur les données publiées et les données.
- Les agents de distribution démarrent et remplacent le schéma et les données de l'abonné à l'aide de fichiers créés par l'agent d'instantané.
L'image suivante illustre le fonctionnement de la réplication d'instantané.
Avantages
- La réplication d'instantanés est très simple à configurer. Si les données ne sont pas modifiées fréquemment, la réplication d'instantané est une option très appropriée.
- Vous pouvez contrôler quand envoyer des données. Par exemple, une table principale qui contient un volume élevé de données, mais qui change moins fréquemment que vous ne pouvez répliquer les données lorsque le trafic est faible.
Inconvénients
- L'instantané généré par l'agent d'instantané contient des données publiées modifiées et inchangées. Par conséquent, l'instantané transmis sur le réseau peut produire une latence et avoir un impact sur d'autres opérations.
- À mesure que les données augmentent, la taille de l'instantané augmente et la création et la distribution de l'instantané aux abonnés prennent plus de temps.
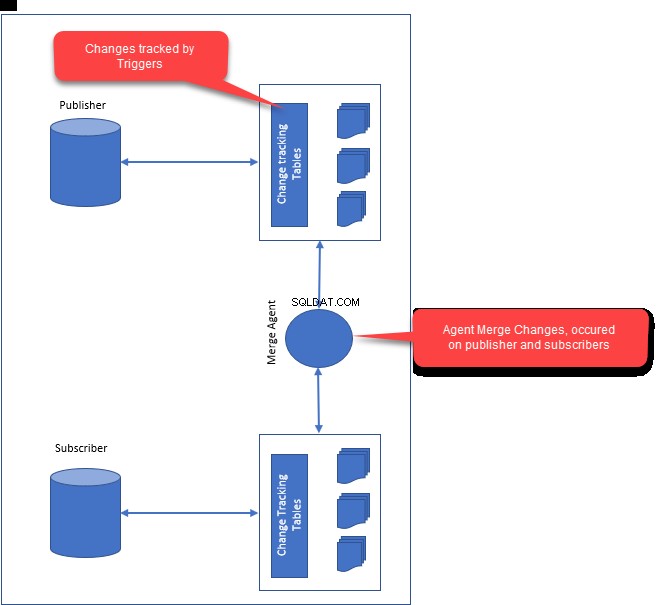
Fusionner la réplication
La réplication de fusion peut être utilisée lorsque nous devons gérer des modifications sur plusieurs serveurs et que ces modifications doivent être consolidées.
Lorsque nous configurons la réplication de fusion, les composants suivants seront créés :
- Agent d'instantané :L'agent d'instantané génère le premier instantané des données de publication et des objets de base de données. Une fois l'instantané créé, il sera distribué à tous les abonnés.
- Agent de fusion :L'agent de fusion est chargé de résoudre les conflits entre l'éditeur et les abonnés. Tous les conflits sont résolus via l'agent de fusion qui utilise la résolution des conflits. Selon la façon dont vous avez configuré la résolution des conflits, les conflits sont résolus par l'agent de fusion.
Lorsque nous configurons la réplication de fusion, il effectue les activités suivantes :
- Il démarre en prenant un instantané des données de publication et des objets de base de données et un instantané appliqué aux abonnés.
- Lors de la configuration de la réplication de fusion, il crée des déclencheurs sur l'éditeur et l'abonné. Les déclencheurs sont responsables du suivi des modifications ultérieures et des modifications de table sur l'éditeur et les abonnés.
- Lorsque l'éditeur et les abonnés se connectent au réseau, les modifications des lignes de données et la modification du schéma sont synchronisées. Lors de la fusion des modifications de l'éditeur et des abonnés, l'agent de fusion résout les conflits en fonction des conditions définies dans l'agent de fusion.
La réplication de fusion est utilisée dans les environnements serveur à client, et elle est idéale pour les situations où les abonnés doivent récupérer des données auprès de l'éditeur, apporter des modifications hors ligne, puis synchroniser les modifications avec l'éditeur et les autres abonnés.
Il peut y avoir des situations pratiques où la même ligne est modifiée par différents éditeurs et abonnés. À ce moment-là, l'agent de fusion examinera quelle résolution de conflit est définie et apportera les modifications en conséquence.
SQL Server identifie de manière unique une colonne à l'aide d'un identificateur global unique pour chaque ligne d'une table publiée. Si la table a déjà une colonne d'identifiant unique, SQL Server utilise automatiquement cette colonne. Sinon, il ajoutera une colonne rowguid dans la table et créera un index basé sur la colonne.
Des déclencheurs seront créés sur les tableaux publiés sur les éditeurs et les abonnés. Ils sont utilisés pour suivre les modifications en fonction des modifications de ligne ou de colonne.
L'image suivante illustre le fonctionnement de la réplication de fusion :
Avantages :
- C'est le seul moyen de parvenir à consolider les modifications sur plusieurs données de serveur.
Inconvénients :
- La réplication et la synchronisation des deux extrémités prennent beaucoup de temps.
- La cohérence est faible car de nombreuses parties doivent être synchronisées.
- Il peut y avoir des conflits lors de la fusion de la réplication si les mêmes lignes sont affectées dans plusieurs abonnés et éditeurs. Il peut être résolu à l'aide de la résolution des conflits, mais cela complique la configuration de la réplication.
Code T-SQL pour revoir la configuration de la réplication
J'ai configuré la réplication de snapshot et la réplication transactionnelle sur deux instances de ma machine. À l'aide de la gestion dynamique SQL (DMV), nous pouvons vérifier la configuration de la réplication. Pour revoir la configuration de la réplication, nous pouvons utiliser le code T-SQL. Le code de script remplit les éléments suivants :
- Nom de la base de données des abonnés.
- Nom de l'éditeur.
- Type d'abonnement.
- Base de données de l'éditeur.
- Nom de l'agent de réplication.
Ci-dessous le script :
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Voici le résultat :

Résumé
Dans cet article, j'ai expliqué :
- Les fondements et les avantages de la réplication et de ses composants.
- Réplication transactionnelle.
- Réplication d'instantané.
- Fusionner la réplication.