SQL Server nous propose différentes solutions pour répliquer ou archiver une table ou des tables de base de données vers une autre base de données, ou la même base de données avec des noms différents. En tant que développeur SQL Server ou administrateur de base de données, vous pouvez être confronté à des situations où vous devez vérifier que les données de ces deux tables sont identiques, et si, par erreur, les données ne sont pas répliquées entre ces deux tables, vous devez synchroniser les données entre les tables. De plus, si vous recevez un message d'erreur, qui interrompt le processus de synchronisation ou de réplication des données, en raison de différences de schéma entre les tables source et cible, vous devez trouver un moyen simple et rapide d'identifier les différences de schéma, ALTER les tables pour faire le schéma identique des deux côtés et reprendre le processus de synchronisation des données.
Dans d'autres situations, vous avez besoin d'un moyen simple d'obtenir la réponse OUI ou NON, si les données et le schéma de deux tables sont identiques ou non. Dans cet article, nous allons passer en revue les différentes manières de comparer les données et le schéma entre deux tables. Les méthodes fournies dans cet article compareront les tables hébergées dans différentes bases de données, ce qui est le scénario le plus compliqué, et peuvent également être facilement utilisées pour comparer les tables situées dans la même base de données avec des noms différents.
Avant de décrire les différentes méthodes et outils qui peuvent être utilisés pour comparer les données des tables et les schémas, nous allons préparer notre environnement de démonstration en créant deux nouvelles bases de données et créer une table dans chaque base de données, avec une petite différence de type de données entre ces deux tables, comme indiqué dans les instructions CREATE DATABASE et CREATE TABLE T-SQL ci-dessous :
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Après avoir créé les bases de données et les tables, nous allons remplir les deux tables avec cinq lignes identiques, puis insérer un autre nouvel enregistrement dans la première table uniquement, comme indiqué dans les instructions INSERT INTO T-SQL ci-dessous :
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO L'environnement de test est maintenant prêt à commencer à décrire les méthodes de comparaison des données et des schémas.
Comparer les données de tables à l'aide d'une jointure gauche
Le mot clé LEFT JOIN T-SQL est utilisé pour récupérer les données de deux tables, en renvoyant tous les enregistrements de la table de gauche et uniquement les enregistrements correspondants de la table de droite et les valeurs NULL de la table de droite lorsqu'il n'y a pas de correspondance entre les deux tables.
À des fins de comparaison de données, le mot-clé LEFT JOIN peut être utilisé pour comparer deux tables, sur la base de la colonne unique commune telle que la colonne ID dans notre cas, comme dans l'instruction SELECT ci-dessous :
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
La requête précédente renverra les cinq lignes communes existant dans les deux tables, en plus de la ligne qui existe dans la première table et qui manque dans la seconde, en affichant les valeurs NULL à droite du résultat, comme indiqué ci-dessous :
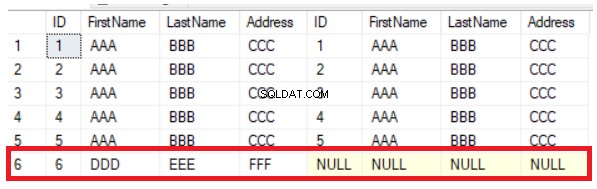
Vous pouvez facilement déduire du résultat précédent que la sixième colonne qui existe dans la première table est manquante dans la deuxième table. Pour synchroniser les lignes entre les tables, vous devez insérer manuellement le nouvel enregistrement dans la deuxième table. La méthode LEFT JOIN est utile pour vérifier les nouvelles lignes mais n'aidera pas dans le cas de la mise à jour des valeurs des colonnes. Si vous modifiez la valeur de la colonne Adresse de la 5ème ligne, la méthode LEFT JOIN ne détectera pas ce changement, comme indiqué clairement ci-dessous :
Comparer les données des tables à l'aide de la clause EXCEPT
L'instruction EXCEPT renvoie les lignes de la première requête (requête de gauche) qui ne sont pas renvoyées de la deuxième requête (requête de droite). En d'autres termes, l'instruction EXCEPT renverra la différence entre deux instructions ou tables SELECT, ce qui nous aide à comparer facilement les données de ces tables.
L'instruction EXCEPT peut être utilisée pour comparer les données des tables précédemment créées, en prenant la différence entre la requête SELECT * de la première table et la requête SELECT * de la seconde table, en utilisant les instructions T-SQL ci-dessous :
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Le résultat de la requête précédente sera la ligne disponible dans la première table et non disponible dans la seconde, comme indiqué ci-dessous :
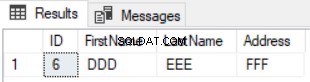
L'utilisation de l'instruction EXCEPT pour comparer deux tables est préférable à l'instruction LEFT JOIN dans la mesure où les enregistrements mis à jour seront capturés dans le résultat des différences de données. Supposons que nous ayons mis à jour l'adresse de la ligne numéro 5 dans la deuxième table et vérifié la différence à l'aide de l'instruction EXCEPT à nouveau, vous verrez que la ligne numéro 5 sera renvoyée avec le résultat des différences comme indiqué ci-dessous :
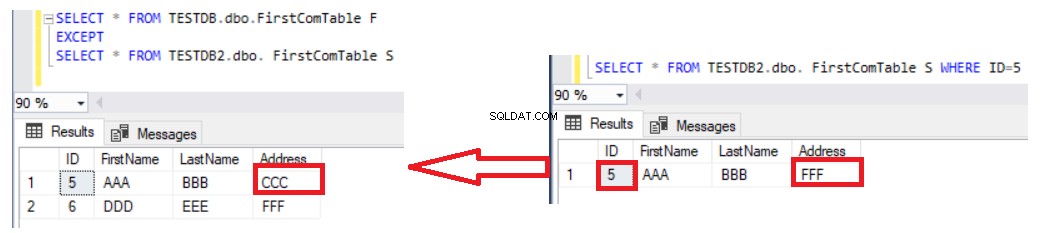
Le seul inconvénient de l'utilisation de l'instruction EXCEPT pour comparer les données de deux tables est que vous devez synchroniser les données manuellement en écrivant une instruction INSERT pour les enregistrements manquants dans la deuxième table. Tenez compte du fait que les deux tables comparées sont des tables à clé pour obtenir le résultat correct, avec une clé unique utilisée pour la comparaison. Si nous supprimons la colonne ID unique de l'instruction SELECT dans les deux côtés de l'instruction EXCEPT et répertorions le reste des colonnes non clés, comme dans l'instruction ci-dessous :
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
Le résultat indiquera que seuls les nouveaux enregistrements sont renvoyés et que ceux mis à jour ne seront pas répertoriés, comme indiqué dans le résultat ci-dessous :
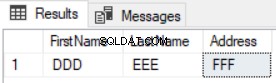
Comparer les données des tableaux à l'aide d'un UNION ALL … GROUP BY
L'instruction UNION ALL peut également être utilisée pour comparer les données de deux tables, sur la base d'une colonne de clé unique. Pour utiliser l'instruction UNION ALL afin de renvoyer la différence entre deux tables, vous devez répertorier les colonnes à comparer dans l'instruction SELECT et utiliser ces colonnes dans la clause GROUP BY, comme indiqué dans la requête T-SQL ci-dessous :
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
GROUP BY ID,FirstName, LastName, Address
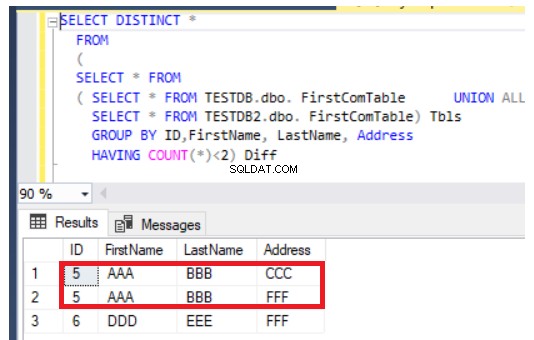
HAVING COUNT(*)<2) Diff Et seule la ligne qui existe dans la première table et qui manque dans la deuxième table sera renvoyée comme indiqué ci-dessous :
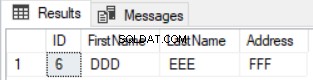
La requête précédente fonctionnera également correctement dans le cas de la mise à jour d'enregistrements, mais d'une manière différente. Il renverra les enregistrements nouvellement insérés en plus des colonnes mises à jour des deux tables, comme dans le cas de la ligne numéro 5, illustrée ci-dessous :
Comparer les données des tableaux à l'aide des outils de données SQL Server
Les outils de données SQL Server, également connus sous le nom de SSDT, construits sur Microsoft Visual Studio peuvent être facilement utilisés pour comparer les données de deux tables portant le même nom, sur la base d'une colonne de clé unique, hébergées dans deux bases de données différentes et synchroniser les données de ces tables. , ou générer un script de synchronisation à utiliser ultérieurement.
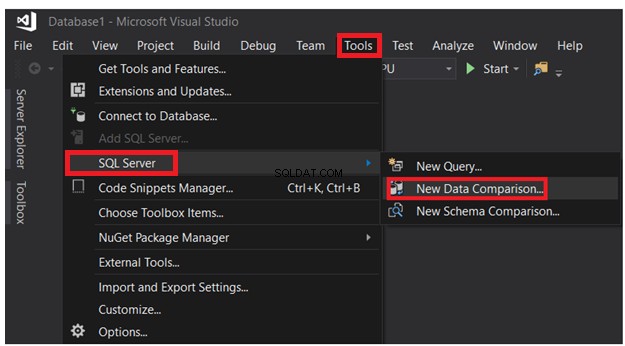
Dans la fenêtre SSDT ouverte, cliquez sur le menu Outils -> liste SQL Server et choisissez Nouvelle comparaison de données option, comme indiqué ci-dessous :
Dans la fenêtre de connexion affichée, vous pouvez choisir parmi les sessions précédemment connectées, ou remplir la fenêtre Propriétés de connexion avec le nom du serveur SQL, les informations d'identification et le nom de la base de données, puis cliquer sur Se connecter , comme indiqué ci-dessous :

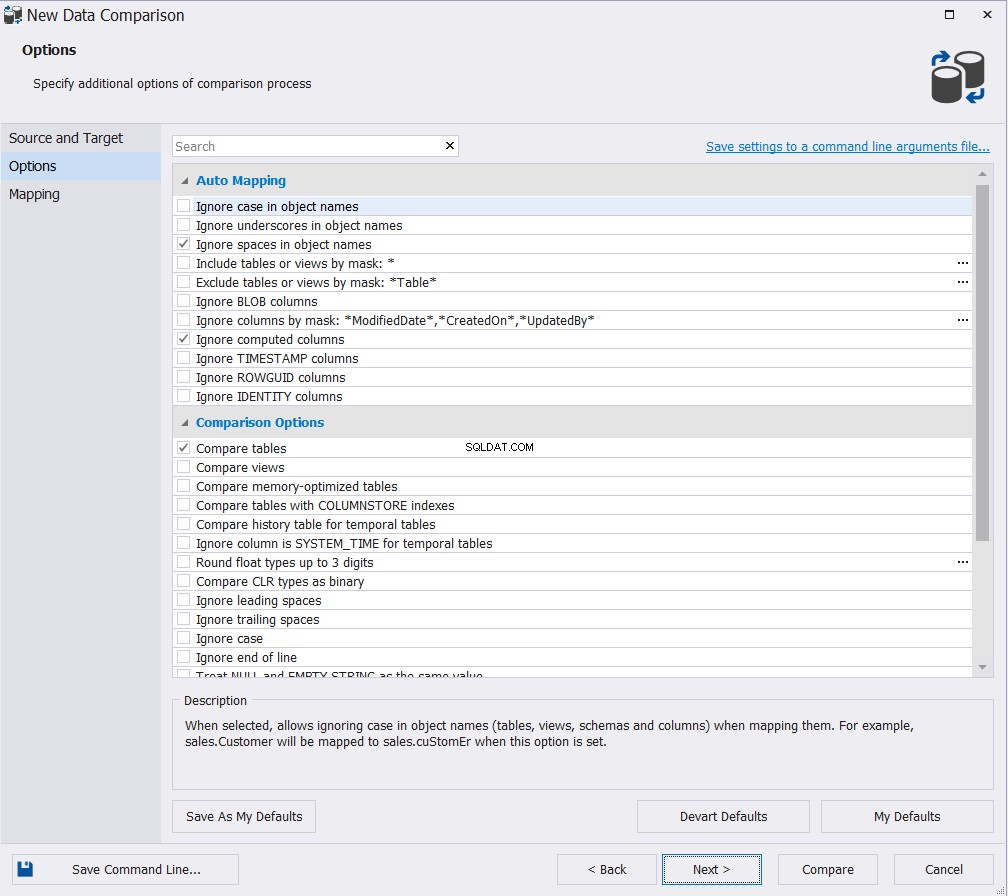
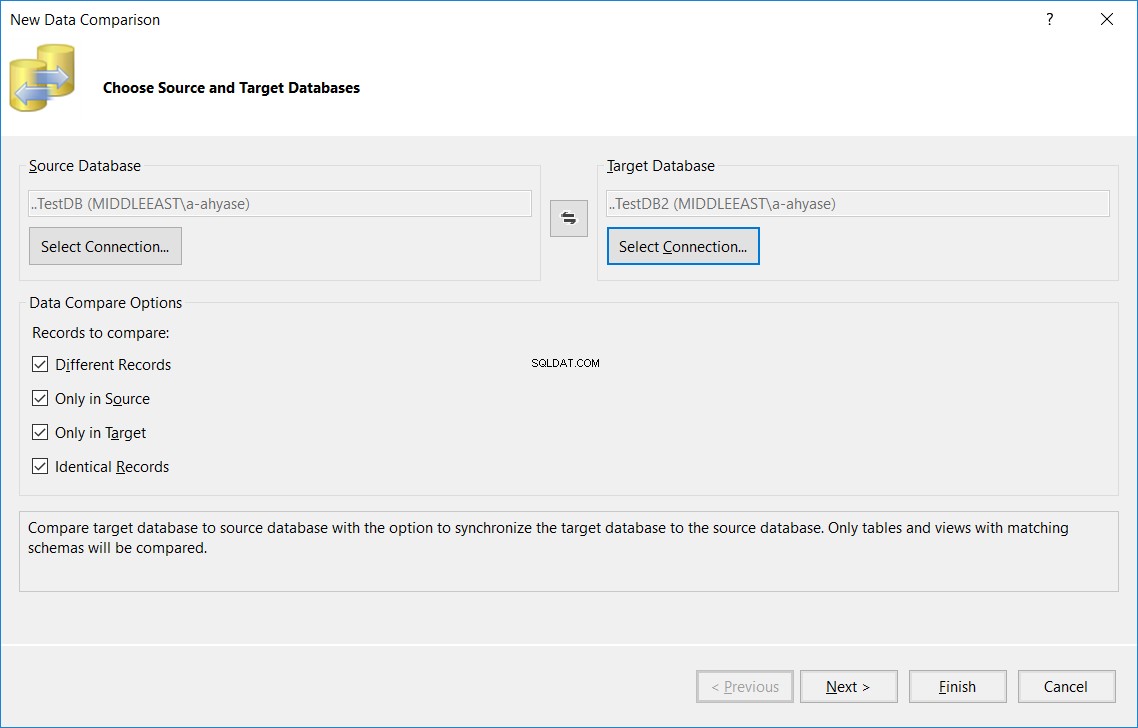
Dans l'assistant Nouvelle comparaison de données affiché, spécifiez les noms des bases de données source et cible et les options de comparaison utilisées dans le processus de comparaison des tables, puis cliquez sur Suivant , comme indiqué ci-dessous :
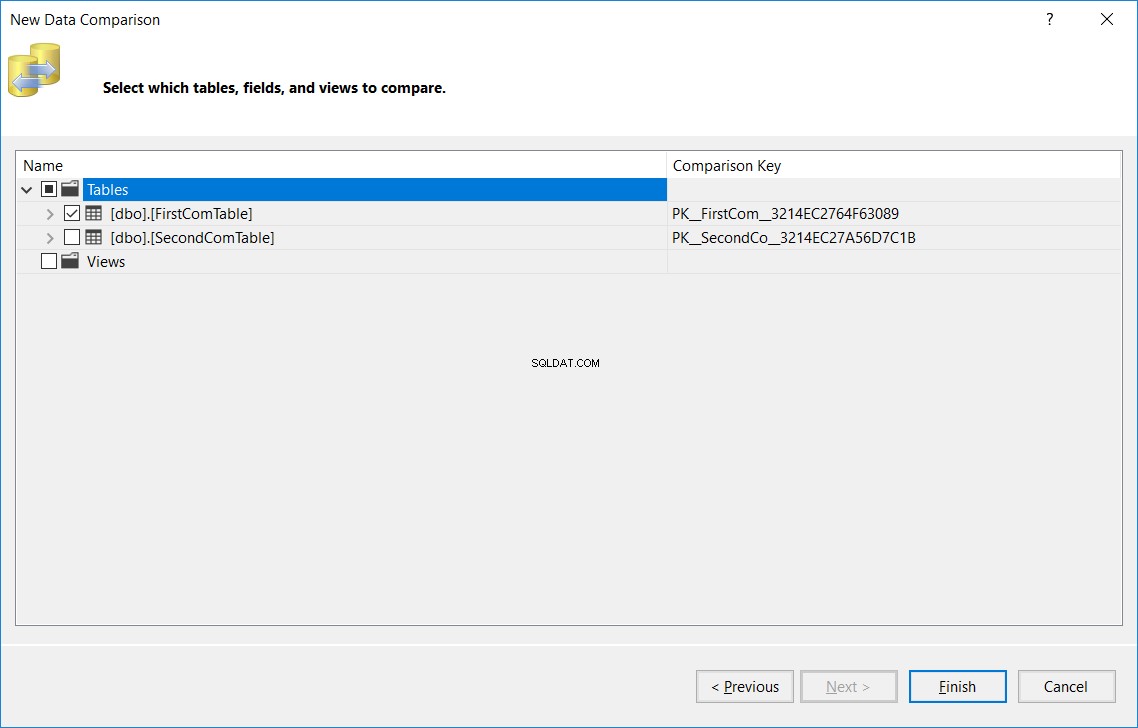
Dans la fenêtre suivante, spécifiez le nom de la table, qui devrait être le même nom dans les bases de données source et cible, qui sera comparée dans les deux bases de données et cliquez sur Terminer , comme ci-dessous :
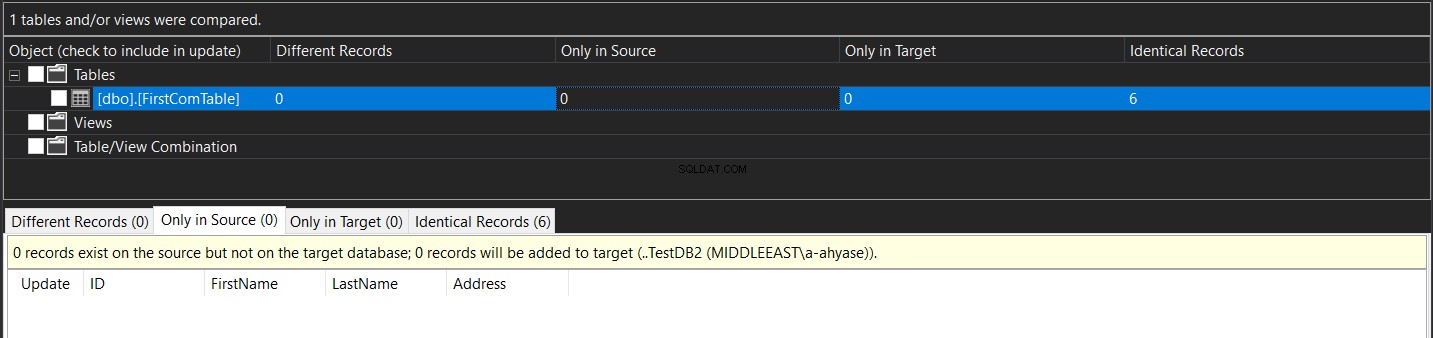
Le résultat affiché vous montrera le nombre d'enregistrements trouvés dans la source et manqués dans la cible, trouvés dans la cible et manqués dans la source, le nombre d'enregistrements mis à jour avec la même clé et différentes valeurs de colonnes (Enregistrements différents) et enfin le nombre d'enregistrements identiques trouvés dans les deux tables, comme indiqué ci-dessous :
Cliquez sur le nom du tableau dans le résultat précédent, vous trouverez une vue détaillée de ces résultats, comme indiqué ci-dessous :

Vous pouvez utiliser le même outil pour générer un script afin de synchroniser les tables source et cible ou mettre à jour la table cible directement avec les modifications manquantes ou différentes, comme ci-dessous :
Si vous cliquez sur l'option Générer un script, une instruction INSERT avec la colonne manquante dans la table cible s'affichera, comme indiqué ci-dessous :
BEGIN TRANSACTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
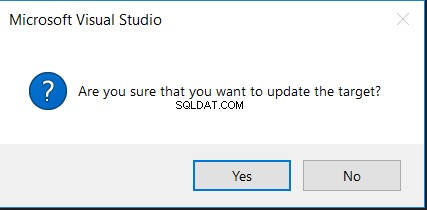
Choisir l'option Mettre à jour la cible vous demandera d'abord votre confirmation pour effectuer le changement, comme dans le message ci-dessous :
Après la synchronisation, vous verrez que les données des deux tables seront identiques, comme indiqué ci-dessous :
Comparer les données des tables à l'aide de l'outil tiers "dbForge Studio for SQL Server"
Dans le monde SQL Server, vous pouvez trouver un grand nombre d'outils tiers qui facilitent la vie des administrateurs et des développeurs de bases de données. L'un de ces outils, qui fait des tâches d'administration de la base de données un jeu d'enfant, est le dbForge Studio pour SQL Server, qui nous fournit des moyens simples d'effectuer les tâches d'administration et de développement de la base de données. Cet outil peut également nous aider à comparer les données dans les tables de la base de données et à synchroniser ces tables.
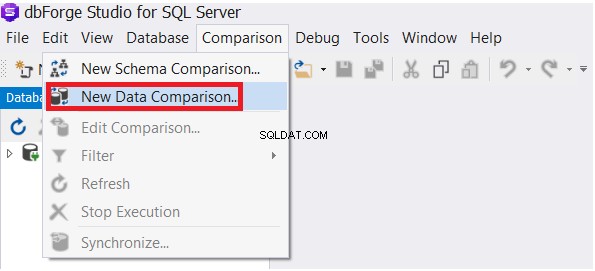
Dans le menu Comparaison, choisissez Nouvelle comparaison de données option, comme indiqué ci-dessous :
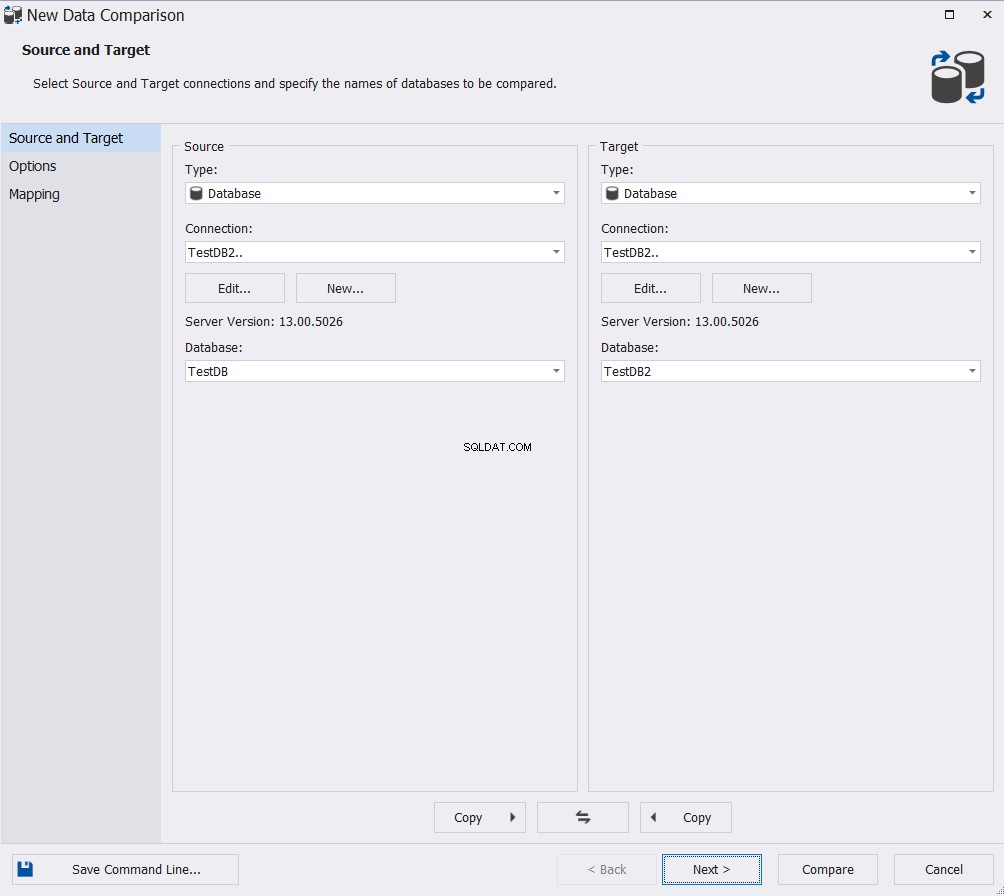
Dans l'assistant Nouvelle comparaison de données, spécifiez la base de données source et cible, puis cliquez sur Suivant :
Choisissez les options appropriées parmi la vaste gamme d'options de cartographie et de comparaison disponibles et cliquez sur Suivant :
Spécifiez le nom de la table ou des tables qui participeront au processus de comparaison de données. L'assistant affichera un message d'avertissement en cas de différences de schéma entre les tables des bases de données source et cible. Cliquez sur Comparer pour continuer :
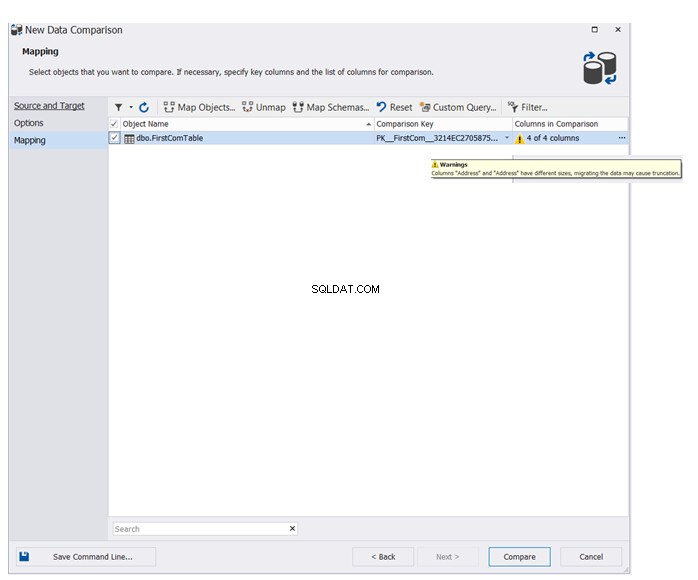
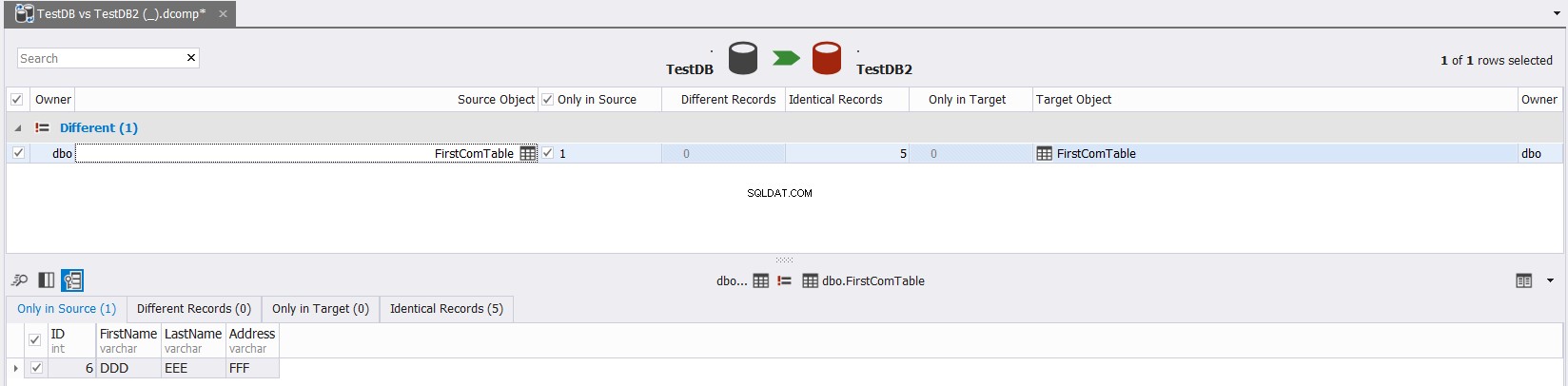
Le résultat final vous montrera en détail, les différences de données entre les tables source et cible, avec la possibilité de cliquer sur  pour synchroniser les tables source et destination, comme indiqué ci-dessous :
pour synchroniser les tables source et destination, comme indiqué ci-dessous :
Comparer le schéma des tables à l'aide de sys.columns
Comme mentionné au début de cet article, pour répliquer ou archiver une table, vous devez vous assurer que le schéma des tables source et cible est identique. SQL Server nous offre différentes façons de comparer le schéma des tables dans la même base de données ou dans différentes bases de données. La première méthode consiste à interroger la vue du catalogue système sys.columns, qui renvoie une ligne pour chaque colonne d'un objet qui a une colonne, avec les propriétés de chaque colonne.
Pour comparer le schéma de tables situées dans différentes bases de données, il faut fournir au sys.columns le nom de la table sous la base de données courante, sans pouvoir fournir une table hébergée dans une autre base de données. Pour ce faire, nous allons interroger les sys.columns deux fois, enregistrer le résultat de chaque requête dans une table temporaire et enfin comparer le résultat de ces deux requêtes à l'aide de la commande EXCEPT T-SQL, comme indiqué clairement ci-dessous :
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Le résultat nous montrera que la définition de la colonne Adresse est différente dans ces deux tables, sans informations spécifiques sur la différence exacte, comme indiqué ci-dessous :

Comparer le schéma des tables à l'aide de INFORMATION_SCHEMA.COLUMNS
La vue système INFORMATION_SCHEMA.COLUMNS peut également être utilisée pour comparer le schéma de différentes tables, en fournissant le nom de la table. Encore une fois, pour comparer deux tables hébergées dans des bases de données différentes, nous allons interroger le INFORMATION_SCHEMA.COLUMNS deux fois, conserver le résultat de chaque requête dans une table temporaire et enfin comparer le résultat de ces deux requêtes à l'aide de la commande EXCEPT T-SQL, comme indiqué clairement ci-dessous :
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Et le résultat sera quelque peu similaire au précédent, montrant que la définition de la colonne Adresse est différente dans ces deux tables, sans aucune information spécifique sur la différence exacte, comme indiqué ci-dessous :

Comparer le schéma des tables à l'aide de dm_exec_describe_first_result_set
Les schémas des tables peuvent également être comparés en interrogeant la fonction de gestion dynamique dm_exec_describe_first_result_set, qui prend une instruction Transact-SQL comme paramètre et décrit les métadonnées du premier jeu de résultats pour l'instruction.
Pour comparer le schéma de deux tables, vous devez joindre le DMF dm_exec_describe_first_result_set avec lui-même, en fournissant l'instruction SELECT de chaque table en tant que paramètre, comme dans la requête T-SQL ci-dessous :
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Le résultat sera plus clair cette fois, car vous pouvez comparer à l'œil nu la différence entre les deux tables, c'est-à-dire la taille et le type de la colonne Adresse, comme indiqué ci-dessous :

Comparer le schéma des tables à l'aide des outils de données SQL Server
SQL Server Data Tools peut également être utilisé pour comparer le schéma de tables situées dans différentes bases de données. Dans le menu Outils, choisissez Nouvelle comparaison de schémas option dans la liste des options SQL Server, comme indiqué ci-dessous :
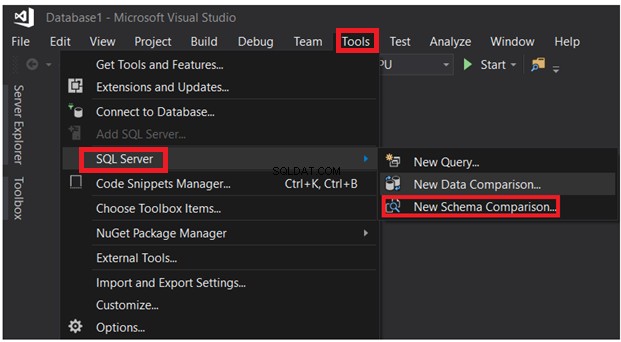
Après avoir fourni les paramètres de connexion, cliquez sur le bouton Comparer :

Le résultat de la comparaison vous montrera, en particulier, la différence de schéma entre les deux tables sous la forme de commandes CREATE TABLE T-SQL, ombrées comme dans l'instantané ci-dessous :
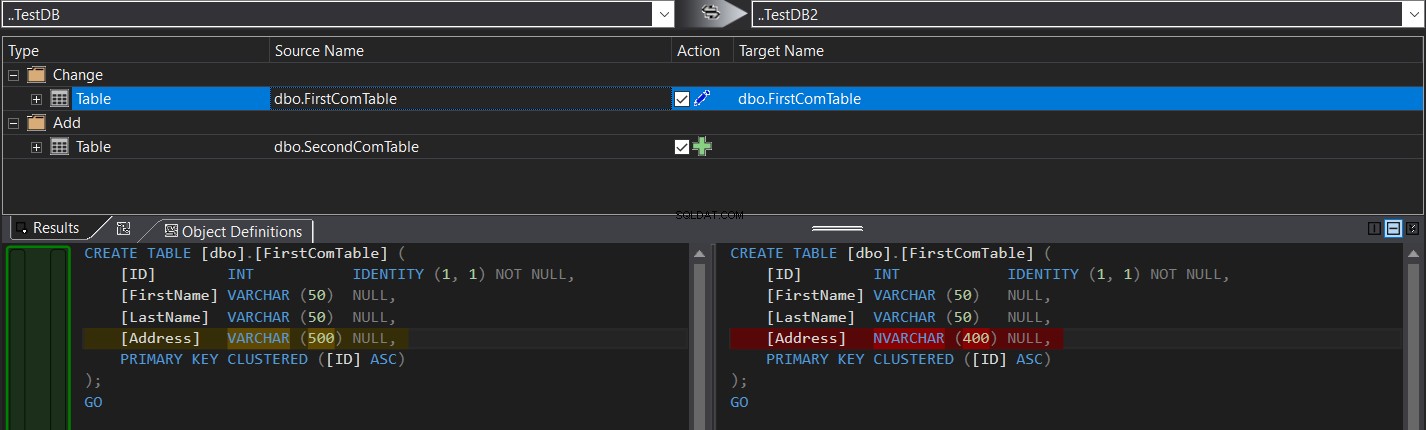
Vous pouvez facilement cliquer  pour synchroniser le schéma de la table ou cliquez sur
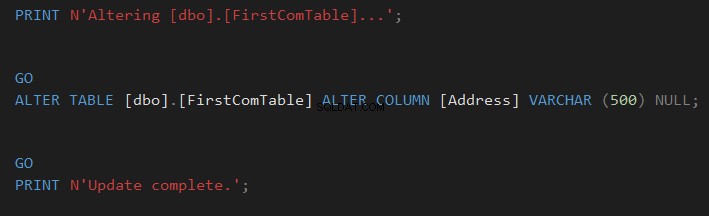
pour synchroniser le schéma de la table ou cliquez sur  pour scripter la modification et l'exécuter ultérieurement, comme indiqué ci-dessous :
pour scripter la modification et l'exécuter ultérieurement, comme indiqué ci-dessous :
Comparer le schéma de tables à l'aide de dbForge Studio pour l'outil tiers SQL Server
L'outil dbForge Studio for SQL Server nous permet de comparer le schéma des différentes tables de la base de données. Dans le menu Comparaison, choisissez Nouvelle comparaison de schémas option, comme ci-dessous :
Après avoir spécifié les propriétés de connexion des bases de données source et cible, choisissez l'option de mappage appropriée parmi les choix disponibles et cliquez sur Suivant :
Choisissez les schémas que vous comparerez à son objet et cliquez sur Suivant :
Spécifiez la table ou les tables qui participeront au processus de comparaison de schéma et cliquez sur Comparer , si vous souhaitez ignorer la modification des paramètres par défaut dans la fenêtre Filtre d'objet, comme ci-dessous :
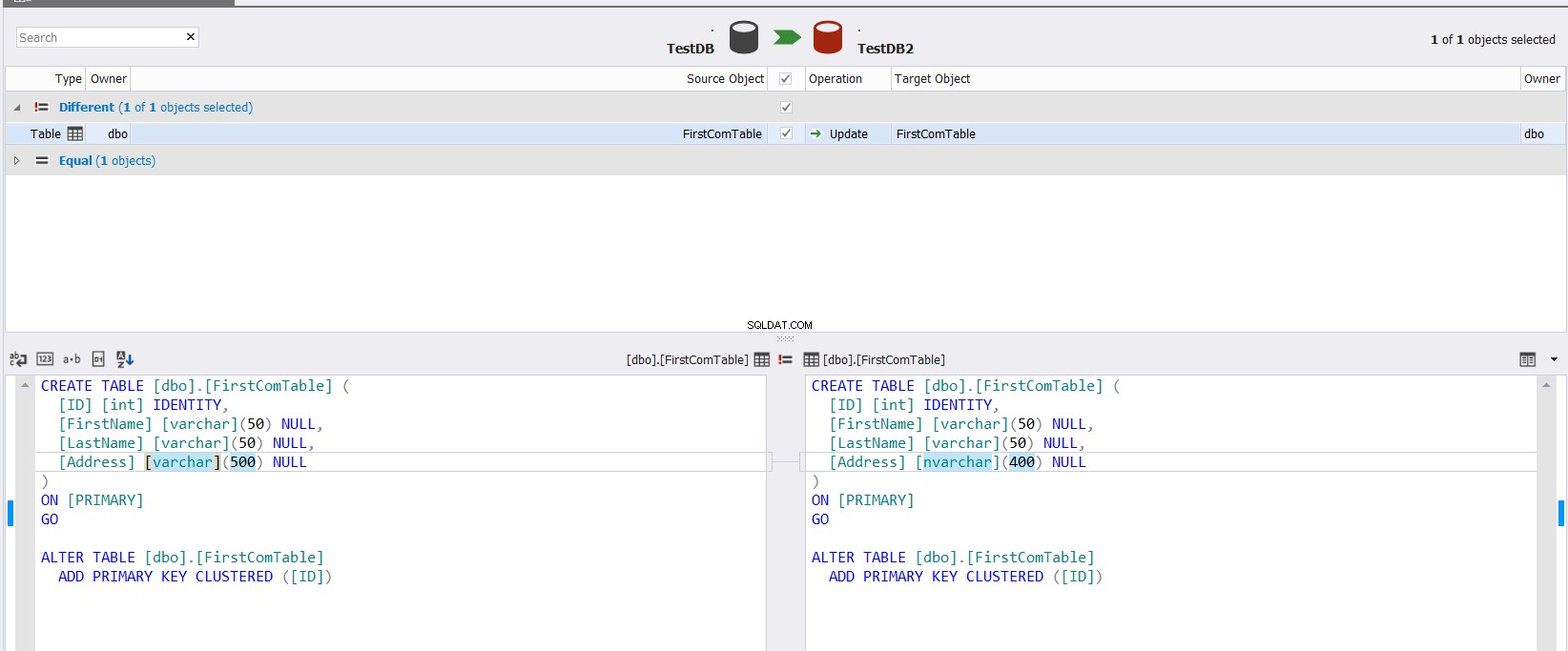
Le résultat de la comparaison affiché vous montrera la différence entre le schéma des deux tables, en mettant exactement en évidence la partie du type de données qui diffère entre les deux colonnes, avec la possibilité de spécifier quelle action doit être effectuée pour synchroniser les deux tables, comme indiqué ci-dessous :
Si vous vous arrangez pour synchroniser le schéma des deux tables, cliquez sur le bouton et précisez dans l'assistant Schema Synchronization wizard si vous parvenez à exécuter le changement directement sur la table cible, ou juste le scripter pour l'utiliser dans le futur, comme ci-dessous :
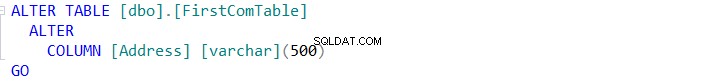
Liens utiles :
- Opérateurs d'ensemble :EXCEPT et INTERSECT (Transact-SQL)
- Opérateurs d'ensemble – UNION (Transact-SQL)
- Télécharger les outils de données SQL Server (SSDT)
- Comparer et synchroniser les données d'une ou plusieurs tables avec les données d'une base de données de référence
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Vues du schéma d'informations système (Transact-SQL)
Outils utiles :
dbForge Schema Compare for SQL Server – outil fiable qui vous fait gagner du temps et des efforts lors de la comparaison et de la synchronisation des bases de données sur SQL Server.
dbForge Data Compare for SQL Server – puissant outil de comparaison SQL capable de travailler avec le Big Data.