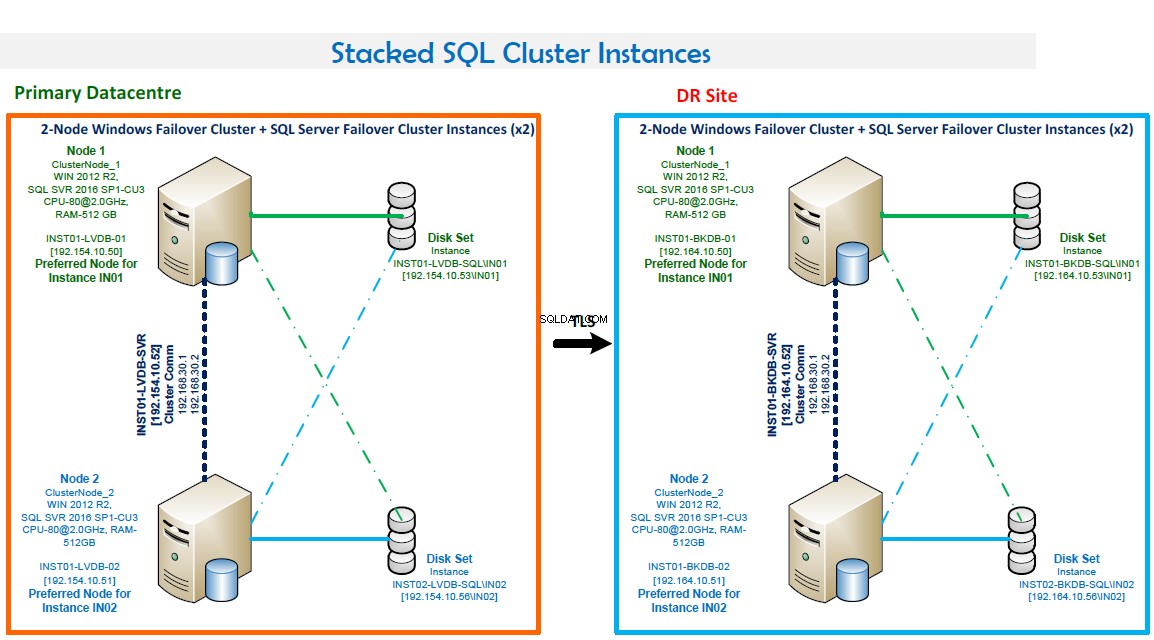
REMARQUES :
- Cluster de basculement Windows comprenant deux nœuds.
- Deux instances de cluster de basculement SQL Server. Cette configuration optimise le matériel. IN01 est préféré sur Node1 et IN02 est préféré sur Node2.
- Numéros de port :IN01 écoute sur le port 1435 et IN02 écoute sur le port 1436.
- Haute disponibilité. Les deux nœuds se soutiennent mutuellement. Le basculement est automatique en cas d'échec.
- Le mode quorum est la majorité des nœuds et des disques.
- LAN de sauvegarde en place et sauvegarde de routine configurée à l'aide de Veritas
Présentation
Il n'est pas rare que des développeurs et des chefs de projet exigent une nouvelle instance de SQL Server pour chaque nouvelle application ou service. Alors que des technologies telles que la virtualisation et le cloud ont facilité la création de nouvelles instances, certaines techniques séculaires intégrées à SQL Server permettent de réduire les délais d'exécution lorsqu'il est nécessaire de fournir une nouvelle base de données pour un nouveau service ou une nouvelle application. Cet état de fait peut être créé par un DBA qui peut concevoir et déployer un grand cluster SQL Server capable de prendre en charge la plupart des bases de données SQL Server requises par l'organisation. Ce type de consolidation présente des avantages supplémentaires, tels que des coûts de licence réduits, une meilleure gouvernance et une facilité d'administration. Dans cet article, nous mettrons en évidence certaines considérations que nous avons eu l'occasion d'expérimenter lors de l'utilisation du clustering et de l'empilement comme moyen de consolider les bases de données SQL Server.
Cluster
Le clustering de basculement Windows Server est une solution de haute disponibilité très connue qui a survécu à de nombreuses versions de Windows Server et dans laquelle Microsoft a l'intention de continuer à investir et à améliorer. Les instances de cluster de basculement SQL Server s'appuient sur WSFC. Les éditions Standard et Enterprise de SQL Server prennent en charge les instances de cluster de basculement SQL Server, mais l'édition Standard est limitée à seulement deux nœuds. La consolidation des bases de données sur un seul FCI SQL Server offre les avantages suivants :
- HA par défaut — Toutes les bases de données déployées sur une instance SQL Server en cluster sont hautement disponibles par défaut ! Une fois qu'une instance en cluster est créée, les nouveaux déploiements sont pris en charge en termes de haute disponibilité à l'avance.
- Facilité d'administration – Moins d'administrateurs de base de données peuvent passer du temps à configurer, surveiller et, si nécessaire, dépanner UNE instance en cluster prenant en charge de nombreuses applications. Correctement, la documentation de l'instance est également beaucoup plus facile lorsqu'il s'agit d'un grand environnement. La configuration d'une solution de sauvegarde d'entreprise pour gérer toutes les bases de données de votre environnement est facilitée par le fait que vous ne devez effectuer cette configuration qu'une seule fois lorsque vous utilisez des instances consolidées.
- Conformité – Des exigences clés telles que l'application de correctifs et même le renforcement peuvent être effectuées une seule fois avec un temps d'arrêt minimal sur un grand nombre de bases de données en un seul effort administratif. Dans notre boutique, nous avons utilisé Transaction Log Shipping entre les instances en cluster de deux centres de données pour nous assurer que les bases de données sont protégées contre les risques de catastrophe.
- Normalisation – L'application de normes telles que les conventions de dénomination, la gestion des accès, l'authentification Windows, l'audit et la gestion basée sur des règles est beaucoup plus facile lorsqu'il s'agit d'un ou deux environnements en fonction de la taille de votre boutique
Liste 1 : Extraire des informations sur votre instance
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Empilement
SQL Server prend en charge jusqu'à cinquante instances uniques sur un serveur et jusqu'à 25 instances de cluster de basculement sur un cluster de basculement Windows Server. Différentes versions de SQL Server peuvent être empilées sur le même environnement pour fournir un environnement robuste qui prendra en charge différentes applications. Dans une telle configuration, la mise à niveau des bases de données peut prendre la forme d'une simple promotion d'une instance SQL Server vers la version suivante dans le même cluster jusqu'à ce que le matériel vieillisse. Une considération clé à garder à l'esprit lors de l'empilement de SQL Server est que vous devez allouer de la mémoire à chaque instance de manière à ce que la quantité totale de mémoire allouée ne dépasse pas la mémoire disponible sur le système d'exploitation. L'autre point dans cette direction est de s'assurer que le compte de service SQL Server de chaque instance doit disposer des privilèges de verrouillage des pages en mémoire. L'attribution de pages de verrouillage en mémoire garantit que lorsque SQL Server acquiert de la mémoire, le système d'exploitation ne tente pas de récupérer cette mémoire lorsque d'autres processus sur le serveur ont besoin de mémoire. La configuration d'un compte de service SQL Server défini, la configuration de MAX_SERVER_MEMORY et l'octroi du privilège Verrouiller les pages en mémoire constituent un trio essentiel lors de l'empilement d'instances SQL Server.
Microsoft facture quelques milliers de dollars par paire de cœurs de processeur. L'empilement d'instances SQL Server vous permet de tirer parti de ce modèle de licence en faisant en sorte que les instances partagent le même ensemble de processeurs (surcharge de l'actif). Nous avons déjà mentionné que vous pouvez empiler différentes versions de SQL Server en prenant ainsi soin des applications héritées exécutant toujours des versions antérieures à SQL Server 2016 par exemple. Lorsque vous utilisez différentes éditions de SQL Server, vous pouvez envisager d'utiliser Processor Affinity comme décrit par Glen Berry dans cet article. L'affinité du processeur peut également être utilisée pour contrôler la façon dont les ressources du processeur sont partagées entre les instances, tout comme vous contrôlez la mémoire. L'empilement résout également les problèmes de sécurité pour les applications qui doivent utiliser le compte SA par exemple ou les problèmes de configuration pour les applications qui nécessitent une instance dédiée, ou ces options sont un classement spécifique. Les inquiétudes concernant les performances de la TempDB partagée sont une autre raison pour laquelle vous pouvez vouloir empiler plutôt que regrouper toutes les bases de données sur une instance en cluster.
Il convient de noter que la valeur du clustering, comme souligné précédemment, s'étend encore plus loin avec l'empilement. Par exemple, lors de la correction d'une instance SQL Server avec plusieurs FCI, toutes les FCI peuvent être corrigées en une seule fois.
Points à noter
Lors de l'utilisation du clustering, certaines conventions faciliteront un peu l'administration et la gestion de l'environnement et feront mieux transpirer les actifs. Nous en aborderons brièvement quelques-unes :
- Outils client actuels :vous pouvez rencontrer des erreurs inhabituelles lorsque vous essayez de gérer une instance SQL Server 2016 à l'aide de SQL Server Management Studio 2012. Les erreurs ne vous indiquent pas spécifiquement que le problème est lié à la version de l'outil client. Nous avons généralement une instance SQL Server Management Studio 17.3 sur le client que nous souhaitons utiliser pour nous connecter à nos instances.
- Conventions de dénomination :une convention de dénomination vous permet de savoir facilement sur quelle instance vous travaillez à tout moment. En utilisant des alias, vous pouvez encore réduire la charge de mémorisation du nom d'instance long pour les utilisateurs finaux qui ont besoin d'accéder à la base de données.
- Nœud préféré :définir un nœud préféré pour chaque rôle SQL Server sur le gestionnaire de cluster de basculement est une bonne idée, un bon moyen de s'assurer que la puissance de traitement de tous vos nœuds de cluster est utilisée. Dans notre boutique, après avoir configuré les nœuds préférés, nous avons configuré le rôle pour qu'il bascule entre 05h00 et 06h00 en cas de basculement par inadvertance.
- Envoi des journaux de transactions :lors de la configuration de la récupération après sinistre pour les FCI, il est judicieux d'identifier tous les chemins UNC à l'aide de noms virtuels, et non des noms ou de l'adresse IP des nœuds du cluster. Cela garantit que les choses continuent de fonctionner correctement en cas de basculement. Il est également très important de s'assurer que les comptes de l'agent SQL Server sur les deux sites ont un contrôle total sur ces chemins.
Liste 2 : Configurer la surveillance de l'envoi des journaux de transactions par e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Lecteurs de disque
L'un des effets secondaires de l'empilement d'instances SQL Server et de la mise à disposition de plusieurs bases de données est la tendance à manquer de lettres de lecteur. Nous avons contourné ce problème en configurant des points de montage de volume. Chaque disque affecté à un rôle de cluster est configuré en tant que point de montage avec une lettre de lecteur uniquement nécessaire pour un ou deux lecteurs par instance. Un point important à noter lors de l'utilisation de points de montage de volume sur un cluster est qu'à l'avenir, lorsque vous aurez besoin d'ajouter plus de points de montage pour effectuer des tâches de maintenance similaires, il sera nécessaire de mettre DEUX le lecteur principal qui possède la lettre de lecteur et le support. point en mode maintenance sur le cluster.
Dans notre cas, nous avons trouvé le nom de chaque point de montage de volume en fonction du rôle de cluster auquel il a été attribué. Avec autant de disques à gérer, vous auriez certainement besoin de trouver un moyen pour vous et l'administrateur de stockage d'identifier un disque unique afin que le maintien des disques au niveau du stockage, par exemple, ne soit pas très compliqué.
Liste 3 : Surveiller l'utilisation de l'espace disque lors de l'utilisation de points de montage de volume
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Déploiement de la base de données
Dans notre cas, notre stratégie consistait à nous assurer que les nouvelles bases de données suivaient notre norme. Les bases de données plus anciennes ont été traitées avec un peu plus de soin puisque nous étions en quelque sorte en train de consolider et de mettre à niveau en même temps. L'assistant de migration de base de données nous a aidés à nous dire quelles bases de données ne seraient certainement pas compatibles avec notre instance sacrée SQL Server 2016 et nous les avons laissées tranquilles (certaines avec des niveaux de compatibilité aussi bas que 100). Chaque base de données déployée doit avoir ses propres volumes de données et de fichiers journaux en fonction de sa taille. L'utilisation de volumes séparés pour chaque base de données est une autre étape vers un environnement très bien organisé, ce qui est important compte tenu de la complexité potentielle de cet environnement consolidé. La dernière déclaration implique également que lorsque vous autorisez une application à créer ses propres bases de données, vous devez, en tant que DBA, déplacer les fichiers de données une fois le déploiement terminé, car l'application utilisera les mêmes emplacements de fichiers que ceux utilisés par la base de données modèle.
Liste 4 : Déplacement des bases de données utilisateur
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Gestion des accès
Vous conviendrez que dans notre environnement consolidé, nous pourrions finir par avoir une très longue liste d'objets de niveau serveur tels que les connexions. L'utilisation de groupes Windows permet de raccourcir cette liste et de simplifier la gestion des accès sur chaque instance en cluster. En règle générale, vous aurez besoin de groupes créés sur Active Directory pour les administrateurs d'application qui ont besoin d'un accès, les comptes de service d'application, les utilisateurs professionnels qui doivent extraire des rapports et bien sûr les administrateurs de base de données. L'un des principaux avantages de l'utilisation des groupes Windows est que l'accès peut être accordé ou révoqué simplement en gérant l'appartenance à ces groupes directement dans Active Directory.
Il est probablement évident maintenant que cet avantage dans le domaine de la gestion des accès n'est possible qu'avec l'authentification Windows. Les connexions SQL Server ne peuvent pas être gérées en groupes.
Liste 5 : Connexions d'instance, utilisateurs de base de données et leurs rôles
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Conclusion
Nous avons examiné à un niveau très élevé les avantages qui peuvent être obtenus en mettant en cluster et en empilant des instances SQL Server comme moyen de parvenir à la consolidation, à l'optimisation des coûts et à la facilité de gestion. Si vous vous sentez capable d'acheter du matériel volumineux, vous pouvez explorer cette option et profiter des avantages que nous avons décrits ci-dessus.