Sauf si Dataset est cached en utilisant un stockage fiable (standard Spark cache ne vous donnera que de faibles garanties) la base de données peut être consultée plusieurs fois, affichant à chaque fois l'état actuel de la base de données. Depuis
voir des décomptes différents est un comportement attendu.
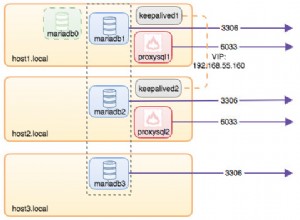
De plus, si la source JDBC est utilisée en mode distribué (avec colonne de partitionnement ou predicates ), alors chaque thread exécuteur utilisera sa propre transaction. En conséquence, l'état du Dataset peut ne pas être entièrement cohérent.
N'utilisez pas JDBC. Vous pouvez par exemple
COPYdonnées dans un système de fichiers et chargez-les à partir de là.- Utilisez la solution de réplication de votre choix pour créer une réplique dédiée à l'analyse, puis configurez et suspendez la réplication pendant l'analyse des données.