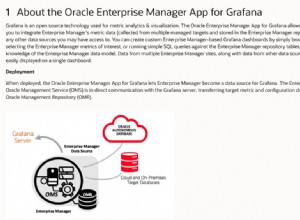
Émuler EVERY() avec CASE et SUM()
En fait, cet article décrit comment EVERY() peut être émulé via CASE et SUM()
. Les deux déclarations suivantes sont équivalentes :
SELECT EVERY(id < 10)
FROM book
SELECT CASE SUM(CASE WHEN id < 10 THEN 0 ELSE 1 END)
WHEN 0 THEN 1
ELSE 0
END
FROM book;
Il en va de même pour le EVERY() fonction fenêtre :
SELECT
book.*,
EVERY(title LIKE '%a') OVER (PARTITION BY author_id)
FROM book
SELECT
book.*,
CASE SUM(CASE WHEN title LIKE '%a' THEN 0 ELSE 1 END)
OVER(PARTITION BY author_id)
WHEN 0 THEN 1
ELSE 0
END
FROM book;
Norme SQL
Le SQL:2008 standard mentionne le EVERY fonction d'agrégat :
10.9 <aggregate function>
[...]
<aggregate function> ::=
COUNT <left paren> <asterisk> <right paren> [ <filter clause> ]
| <general set function> [ <filter clause> ]
| <binary set function> [ <filter clause> ]
| <ordered set function> [ <filter clause> ]
<general set function> ::=
<set function type> <left paren> [ <set quantifier> ]
<value expression> <right paren>
<set function type> ::=
<computational operation>
<computational operation> ::=
AVG
| MAX
| MIN
| SUM
| EVERY
| [...]
Mais les fonctionnalités standard SQL "avancées" ne sont pas souvent implémentées par les bases de données. Oracle 11g par exemple, ne le prend pas en charge, pas plus que SQL Server 2012 .
Avec HSQLDB
, cependant, vous pourriez être plus chanceux. HSQLDB 2.x est très conforme aux normes, également MySQL connaît le BIT_AND()
fonction d'agrégation, qui est un alias non standard pour EVERY() , également pris en charge par Postgres.
Notez que certaines bases de données permettent d'écrire des fonctions d'agrégation définies par l'utilisateur, vous pouvez donc également implémenter EVERY() vous-même.