De nombreux outils puissants doivent être disponibles comme option de sauvegarde et de restauration pour PostgreSQL en général ; Barman, PgBackRest, BART sont pour n'en nommer que quelques-uns dans ce contexte. Ce qui a attiré notre attention, c'est que Barman est un outil qui rattrape rapidement le déploiement de la production et les tendances du marché.
Qu'il s'agisse d'un déploiement basé sur docker, d'un besoin de stocker la sauvegarde dans un stockage cloud différent ou d'une architecture de reprise après sinistre hautement personnalisable, Barman est un concurrent très sérieux dans tous ces cas.
Ce blog explore Barman avec peu d'hypothèses sur le déploiement, mais en aucun cas cela ne doit être considéré comme un ensemble de fonctionnalités possibles. Barman va bien au-delà de ce que nous pouvons capturer dans ce blog et doit être exploré plus avant si la "sauvegarde et restauration de l'instance PostgreSQL" est envisagée.
Hypothèse de déploiement prêt pour la DR
RPO=0 a généralement un coût - le déploiement de serveur de secours synchrone répondrait souvent à cela, mais cela impacte assez souvent le TPS du serveur principal.
Comme PostgreSQL, Barman offre de nombreuses options de déploiement pour répondre à vos besoins en matière de RPO par rapport aux performances. Pensez à la simplicité du déploiement, au RPO=0 ou à un impact quasi nul sur les performances ; Barman s'adapte à tous.
Nous avons envisagé le déploiement suivant pour établir une solution de reprise après sinistre pour notre architecture de sauvegarde et de restauration.
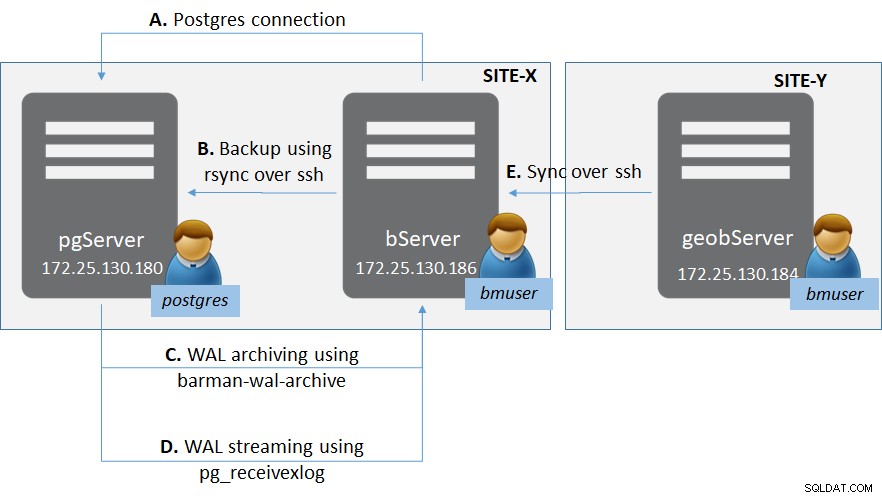 Figure 1 :Déploiement PostgreSQL avec Barman
Figure 1 :Déploiement PostgreSQL avec BarmanIl existe deux sites (comme en général pour les sites de reprise après sinistre) - Site-X et Site-Y.
Dans Site-X, il y a :
- Un serveur « pgServer » hébergeant une instance de serveur PostgreSQL pgServer et un utilisateur du système d'exploitation « postgres »
- Instance PostgreSQL également pour héberger un rôle de superutilisateur ‘bmuser’
- Un serveur 'bServer' hébergeant les binaires Barman et un utilisateur OS 'bmuser'
Dans Site-Y il y a :
- Un serveur 'geobServer' hébergeant les binaires Barman et un utilisateur du système d'exploitation 'bmuser'
Plusieurs types de connexion sont impliqués dans cette configuration.
- Entre 'bServer' et 'pgServer' :
- Connectivité du plan de gestion de Barman à l'instance PostgreSQL
- Connectivité rsync pour effectuer une sauvegarde de base réelle de Barman vers l'instance PostgreSQL
- Archivage WAL à l'aide de barman-wal-archive de l'instance PostgreSQL vers Barman
- Streaming WAL en utilisant pg_receivexlog chez Barman
- Entre 'bServer' et 'geobserver' :
- Synchronisation entre les serveurs Barman pour fournir une géo-réplication
La connectivité d'abord
Le principal besoin de connectivité entre les serveurs se fait via ssh. Afin de le rendre sans mot de passe, des clés ssh sont utilisées. Établissons les clés ssh et échangeons-les.
Sur pgServer :
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Sur bServer :
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Sur geobServer :
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Configuration de l'instance PostgreSQL
Il y a deux choses principales dont nous avons besoin pour reconstituer une instance postgres - Le répertoire de base et les journaux WAL / Transactions générés par la suite. Le serveur Barman les suit intelligemment. Ce dont nous avons besoin, c'est de nous assurer que les flux appropriés sont générés pour que Barman puisse collecter ces artefacts.
Ajouter les lignes suivantes à postgresql.conf :
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'La commande Archive garantit que lorsque WAL doit être archivé par l'instance postgres, l'utilitaire barman-wal-archive le soumet au serveur Barman. Il convient de noter que le package barman-cli devrait donc être mis à disposition sur « pgServer ». Il existe une autre option d'utilisation de rsync si nous ne voulons pas utiliser l'utilitaire barman-wal-archive.
Ajouter ce qui suit à pg_hba.conf :
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5Il permet essentiellement une réplication et une connexion normale de 'bmserver' à cette instance postgres.
Maintenant, redémarrez simplement l'instance et créez un rôle de super utilisateur appelé bmuser :
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser Si nécessaire, nous pouvons également éviter d'utiliser bmuser en tant que super-utilisateur ; qui nécessiterait des privilèges attribués à cet utilisateur. Pour l'exemple ci-dessus, nous avons également utilisé bmuser comme mot de passe. Mais c'est à peu près tout, dans la mesure où une configuration d'instance PostgreSQL est requise.
Configuration du barman
Barman a trois composants de base dans sa configuration :
- Configuration globale
- Configuration au niveau du serveur
- Utilisateur qui dirigera le barman
Dans notre cas, étant donné que Barman est installé à l'aide de rpm, nos fichiers de configuration globale sont stockés dans :
/etc/barman.confNous voulions stocker la configuration au niveau du serveur dans le répertoire personnel de bmuser, donc notre fichier de configuration globale avait le contenu suivant :
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOConfiguration du serveur Barman principal
Dans le déploiement ci-dessus, nous avons décidé de conserver le serveur Barman principal dans le même centre de données/site où l'instance PostgreSQL est conservée. L'avantage de la même chose est qu'il y a moins de décalage et une récupération plus rapide en cas de besoin. Inutile de dire que moins de besoins en calcul et/ou en bande passante réseau sont également requis sur le serveur PostgreSQL.
Afin de laisser Barman gérer l'instance PostgreSQL sur le pgServer, nous devons ajouter un fichier de configuration (que nous avons nommé pgserver.conf) avec le contenu suivant :
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoEt un fichier .pgpass contenant les identifiants pour bmuser dans l'instance PostgreSQL :
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Pour comprendre un peu plus les éléments de configuration importants :
- ssh_command :utilisé pour établir une connexion sur laquelle rsync sera effectué
- conninfo :chaîne de connexion permettant à Barman d'établir une connexion avec le serveur postgres
- reuse_backup :Pour autoriser la sauvegarde incrémentielle avec moins d'espace de stockage
- backup_method :méthode pour effectuer une sauvegarde du répertoire de base
- path_prefix :emplacement où les fichiers binaires pg_receivexlog sont stockés
- streaming_conninfo :chaîne de connexion utilisée pour diffuser des WAL
- create_slot :Pour s'assurer que les emplacements ont été créés par l'instance postgres
Configuration du serveur Barman passif
La configuration d'un site de géo-réplication est assez simple. Tout ce dont il a besoin est une information de connexion ssh sur laquelle ce site de nœud passif effectuera la réplication.
Ce qui est intéressant, c'est qu'un tel nœud passif peut fonctionner en mode mixte ; en d'autres termes - ils peuvent agir en tant que serveurs Barman actifs pour effectuer des sauvegardes pour les sites PostgreSQL et en parallèle agir en tant que site de réplication/en cascade pour d'autres serveurs Barman.
Puisque, dans notre cas, cette instance de Barman (sur Site-Y) doit être juste un nœud passif, tout ce dont nous avons besoin est de créer le fichier /home/bmuser/barman.d/pgserver.conf avec la configuration suivante :
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comEn supposant que les clés ont été échangées et que la configuration globale sur ce nœud est effectuée comme mentionné précédemment - nous avons pratiquement terminé la configuration.
Et voici notre première sauvegarde et restauration
Sur le bserver, assurez-vous que le processus d'arrière-plan pour recevoir les WAL a été déclenché ; puis vérifiez la configuration du serveur :
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverLa vérification doit être correcte pour toutes les sous-étapes. Sinon, consultez /home/bmuser/barman.log.
Émettez une commande de sauvegarde sur Barman pour vous assurer qu'il existe une base de données sur laquelle WAL peut être appliqué :
example@sqldat.com$ barman backup pgserverSur le "geobmserver", assurez-vous que la réplication est effectuée en exécutant les commandes suivantes :
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverLe cron doit être inséré dans le fichier crontab (s'il n'est pas présent). Par souci de simplicité, je ne l'ai pas montré ici. La dernière commande montrera que le dossier de sauvegarde a également été créé sur le geobmserver.
Maintenant, sur l'instance Postgres, créons des données factices :
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"La réplication du WAL à partir de l'instance PostgreSQL peut être vue à l'aide de la commande ci-dessous :
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Afin de recréer une instance sur Site-Y, assurez-vous d'abord que les enregistrements WAL sont basculés. ou cet exemple, pour créer une restauration propre :
example@sqldat.com$ barman switch-xlog --force --archive pgserverSur le Site-X, lançons une instance PostgreSQL autonome pour vérifier si la sauvegarde est saine :
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataMaintenant, éditez les fichiers postgresql.conf et postgresql.auto.conf selon les besoins. Expliquez ci-dessous les modifications apportées à cet exemple :
- postgresql.conf :listen_addresses commenté pour être par défaut localhost
- postgresql.auto.conf :suppression de sudo bmuser de restore_command
Affichez ces DATA dans /tmp/data et vérifiez l'existence de vos enregistrements.
Conclusion
Ce n'était que la pointe d'un iceberg. Barman est bien plus profond que cela en raison de la fonctionnalité qu'il offre - par ex. agissant comme une veille synchronisée, des scripts de crochet et ainsi de suite. Inutile de dire que la documentation dans son intégralité doit être explorée pour la configurer selon les besoins de votre environnement de production.