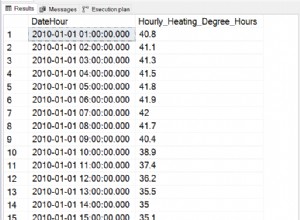
Le moteur d'expression régulière de PG 9.1 et des versions antérieures ne classe pas correctement les caractères dont le point de code ne correspond pas à un octet. Le point de code de 'Ó' étant 211, il a raison, mais le point de code de 'Ą' est de 260, au-delà de 255.
PG 9.2 est meilleur dans ce domaine, mais pas encore à 100% pour tous les alphabets. Voir ce commit dans le code source PostgreSQL, et en particulier ces parties du commentaire :
et
Malheureusement, cela n'a pas été rétroporté vers 9.1