Utilisez agrégat défini par l'utilisateur
Test en direct :https://sqlfiddle.com/#!17/03ee7/1
LDD
CREATE TABLE t
(grop varchar(1), month_year text, something int)
;
INSERT INTO t
(grop, month_year, something)
VALUES
('a', '201901', -2),
('a', '201902', -4),
('a', '201903', -6),
('a', '201904', 60),
('a', '201905', -2),
('a', '201906', 9),
('a', '201907', 11),
('b', '201901', 100),
('b', '201902', -200),
('b', '201903', 300),
('b', '201904', -50),
('b', '201905', 30),
('b', '201906', -88),
('b', '201907', -86)
;
Agrégat défini par l'utilisateur
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$
select case when _accumulated_b < 0 then
_accumulated_b + _current_b
else
_current_b
end
$$ language 'sql';
create aggregate negative_summer(numeric)
(
sfunc = negative_accum,
stype = numeric,
initcond = 0
);
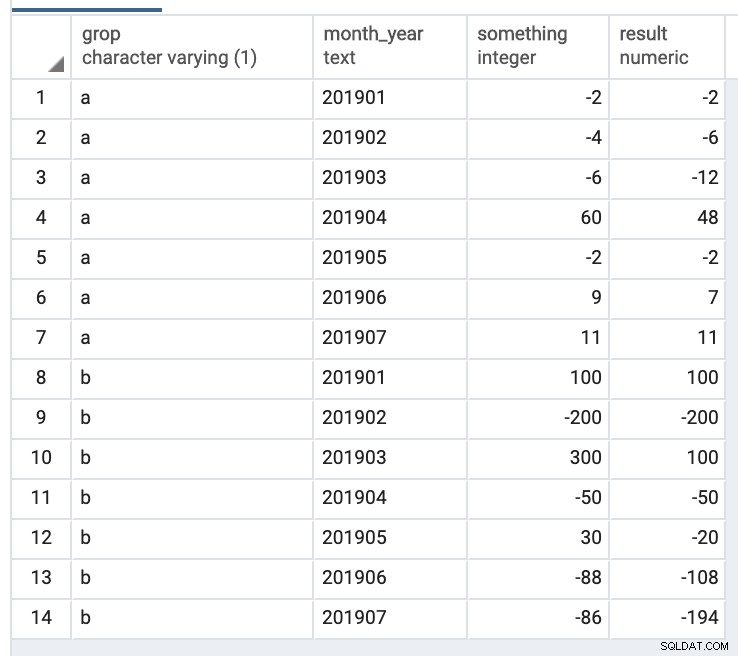
select
*,
negative_summer(something) over (order by grop, month_year) as result
from t
Le premier paramètre (_accumulated_b) contient la valeur cumulée de la colonne. Le deuxième paramètre (_current_b) contient la valeur de la colonne de la ligne actuelle.
Sortie :
Quant à votre pseudo-code B3 = A3 + MIN(0, B2)
J'ai utilisé ce code typique :
select case when _accumulated_b < 0 then
_accumulated_b + _current_b
else
_current_b
end
Cela peut être écrit idiomatiquement dans Postgres comme :
select _current_b + least(_accumulated_b, 0)
Test en direct :https://sqlfiddle.com/#!17/70fa8/1
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$
select _current_b + least(_accumulated_b, 0)
$$ language 'sql';
Vous pouvez également utiliser un autre langage avec la fonction d'accumulateur, par exemple plpgsql. Notez que plpgsql (ou peut-être la citation $$) n'est pas pris en charge dans https://sqlfiddle.com . Donc pas de lien de test en direct, cela fonctionnerait sur votre machine :
create or replace function negative_accum(_accumulated_b numeric, _current_b numeric)
returns numeric as
$$begin
return _current_b + least(_accumulated_b, 0);
end$$ language 'plpgsql';
MISE À JOUR
J'ai raté la partition by , voici un exemple de données (changé de 11 à -11) où sans partition by et avec partition by donnerait des résultats différents :
Test en direct :https://sqlfiddle.com/#!17/87795/4
INSERT INTO t
(grop, month_year, something)
VALUES
('a', '201901', -2),
('a', '201902', -4),
('a', '201903', -6),
('a', '201904', 60),
('a', '201905', -2),
('a', '201906', 9),
('a', '201907', -11), -- changed this from 11 to -11
('b', '201901', 100),
('b', '201902', -200),
('b', '201903', 300),
('b', '201904', -50),
('b', '201905', 30),
('b', '201906', -88),
('b', '201907', -86)
;
Sortie :
| grop | month_year | something | result_wrong | result |
|------|------------|-----------|--------------|--------|
| a | 201901 | -2 | -2 | -2 |
| a | 201902 | -4 | -6 | -6 |
| a | 201903 | -6 | -12 | -12 |
| a | 201904 | 60 | 48 | 48 |
| a | 201905 | -2 | -2 | -2 |
| a | 201906 | 9 | 7 | 7 |
| a | 201907 | -11 | -11 | -11 |
| b | 201901 | 100 | 89 | 100 |
| b | 201902 | -200 | -200 | -200 |
| b | 201903 | 300 | 100 | 100 |
| b | 201904 | -50 | -50 | -50 |
| b | 201905 | 30 | -20 | -20 |
| b | 201906 | -88 | -108 | -108 |
| b | 201907 | -86 | -194 | -194 |