Je ne trouve pas de défaut dans votre conception. J'ai essayé.
Paramètres régionaux et classement
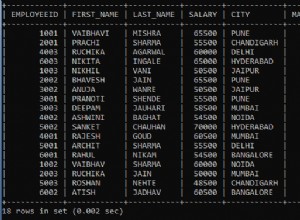
J'ai revisité cette question. Considérez ce cas de test sur sqlfiddle
. Cela semble fonctionner très bien. J'ai même créé la locale ca_ES.utf8 dans mon serveur de test local (PostgreSQL 9.1.6 sur Debian Squeeze) et ajouté les paramètres régionaux à mon cluster DB :
CREATE COLLATION "ca_ES" (LOCALE = 'ca_ES.utf8');
J'obtiens les mêmes résultats que ceux que l'on peut voir dans le sqlfiddle ci-dessus.
Notez que les noms de classement sont des identifiants et doivent être entre guillemets pour préserver l'orthographe CamelCase comme "ca_ES" . Peut-être y a-t-il eu une certaine confusion avec d'autres paramètres régionaux de votre système ? Vérifiez vos classements disponibles
:
SELECT * FROM pg_collation;
Généralement, les règles de classement sont dérivées des localisations système . Lisez les détails dans le manuel ici
. Si vous obtenez toujours des résultats incorrects, j'essaierai de mettre à jour votre système et de régénérer les paramètres régionaux pour "ca_ES" . Dans Debian (et les distributions Linux associées), cela peut être fait avec :
dpkg-reconfigure locales
NFC
J'ai une autre idée :chaînes UNICODE non normalisées .
Se pourrait-il que votre 'Àudio' est en fait '̀ ' || 'Audio' ? Ce serait ce personnage :
SELECT U&'\0300A';
SELECT ascii(U&'\0300A');
SELECT chr(768);
En savoir plus sur l'l'accent aigu sur wikipedia
.
Vous devez SET standard_conforming_strings = TRUE pour utiliser des chaînes Unicode comme dans la première ligne.
Notez que certains navigateurs ne peuvent pas afficher correctement les caractères Unicode non normalisés et que de nombreuses polices n'ont pas de glyphe approprié pour les caractères spéciaux, vous pouvez donc ne rien voir ici ou du charabia. Mais UNICODE permet ce non-sens. Testez pour voir ce que vous avez :
SELECT octet_length('̀A') -- returns 3 (!)
SELECT octet_length('À') -- returns 2
Si c'est ce que votre base de données a contracté, vous devez vous en débarrasser ou en subir les conséquences. Le remède consiste à normaliser vos chaînes en NFC . Perl a des compétences UNICODE-foo supérieures, vous pouvez utiliser leurs bibliothèques dans une fonction plperlu pour le faire dans PostgreSQL. J'ai fait ça pour me sauver de la folie.
Lisez les instructions d'installation dans cet excellent article sur normalisation UNICODE dans PostgreSQL par David Wheeler .
Lisez tous les détails sanglants sur Formulaires de normalisation Unicode sur unicode.org
.