Dans le précédent article de blog, nous vous avons montré quelques étapes de base pour déployer et gérer un serveur MySQL autonome ainsi que la configuration de la réplication MySQL à l'aide du module MySQL Puppet. Dans cette deuxième installation, nous allons couvrir des étapes similaires, mais maintenant avec une configuration Galera Cluster.
Galera Cluster avec marionnette
Comme vous le savez peut-être, Galera Cluster a trois fournisseurs principaux :
- Cluster MySQL Galera (Codership)
- Cluster Percona XtraDB (Percona)
- Cluster MariaDB (intégré dans MariaDB Server par MariaDB)
Une pratique courante avec les déploiements Galera Cluster consiste à disposer d'une couche supplémentaire au-dessus du cluster de bases de données à des fins d'équilibrage de charge. Cependant, c'est un processus complexe qui mérite son propre article.
Il existe un certain nombre de modules Puppet disponibles dans Puppet Forge qui peuvent être utilisés pour déployer un cluster Galera. En voici quelques-uns..
- puppetlabs/mysql - MariaDB Galera uniquement
- fraenki/galera - Cluster Percona XtraDB et MySQL Galera de Codership
- edestecd/mariadb - cluster MariaDB uniquement
- filiadata/percona - Grappe Percona XtraDB
Étant donné que notre objectif est de fournir une compréhension de base de la manière d'écrire un manifeste et d'automatiser le déploiement pour Galera Cluster, nous couvrirons le déploiement de MariaDB Galera Cluster à l'aide du module puppetlabs/mysql. Pour les autres modules, vous pouvez toujours consulter leur documentation respective pour obtenir des instructions ou des conseils sur l'installation.
Dans Galera Cluster, l'ordre lors du démarrage du nœud est essentiel. Pour démarrer correctement un nouveau cluster, un nœud doit être configuré en tant que nœud de référence. Ce nœud sera démarré avec une chaîne de connexion d'hôte vide (gcomm://) pour initialiser le cluster. Ce processus s'appelle l'amorçage.
Une fois démarré, le nœud deviendra un composant principal et les nœuds restants pourront être démarrés à l'aide de la commande mysql start standard (systemctl start mysql ou service mysql start ) suivi d'une chaîne de connexion à l'hôte complet (gcomm://db1,db2,db3). L'amorçage n'est requis que s'il n'y a aucun composant principal détenu par un autre nœud du cluster (vérifiez avec wsrep_cluster_status statut).
Le processus de démarrage du cluster doit être exécuté explicitement par l'utilisateur. Le manifeste lui-même ne doit PAS démarrer le cluster (amorcer n'importe quel nœud) lors de la première exécution pour éviter tout risque de perte de données. N'oubliez pas que le manifeste Puppet doit être écrit pour être aussi idempotent que possible. Le manifeste doit être sûr afin d'être exécuté plusieurs fois sans affecter les instances MySQL déjà en cours d'exécution. Cela signifie que nous devons nous concentrer principalement sur la configuration du référentiel, l'installation du package, la configuration préalable à l'exécution et la configuration de l'utilisateur SST.
Les options de configuration suivantes sont obligatoires pour Galera :
- wsrep_on :Un indicateur pour activer l'API de réplication des jeux d'écriture pour Galera Cluster (MariaDB uniquement).
- wsrep_cluster_name :Le nom du cluster. Doit être identique sur tous les nœuds faisant partie du même cluster.
- wsrep_cluster_address :La chaîne de connexion de communication Galera, préfixée par gcomm:// et suivie de la liste des nœuds, séparée par une virgule. Une liste de nœuds vide signifie l'initialisation du cluster.
- wsrep_provider :Le chemin où se trouve la bibliothèque Galera. Le chemin peut être différent selon le système d'exploitation.
- bind_address :MySQL doit être accessible en externe, la valeur '0.0.0.0' est donc obligatoire.
- wsrep_sst_method :Pour MariaDB, la méthode SST préférée est mariabackup.
- wsrep_sst_auth :Utilisateur et mot de passe MySQL (séparés par deux-points) pour effectuer le transfert d'instantané. Généralement, nous spécifions un utilisateur qui a la possibilité de créer une sauvegarde complète.
- wsrep_node_address :Adresse IP pour la communication et la réplication Galera. Utilisez le facteur Puppet pour choisir la bonne adresse IP.
- wsrep_node_name :nom d'hôte du FQDN. Utilisez le facteur Puppet pour choisir le bon nom d'hôte.
Pour les déploiements basés sur Debian, le script de post-installation tentera de démarrer automatiquement le serveur MariaDB. Si nous avons configuré wsrep_on=ON (drapeau pour activer Galera) avec l'adresse complète dans wsrep_cluster_address variable, le serveur échouerait lors de l'installation. C'est parce qu'il n'a pas de composant principal auquel se connecter.
Pour démarrer correctement un cluster dans Galera, le premier nœud (appelé nœud d'amorçage) doit être configuré avec une chaîne de connexion vide (wsrep_cluster_address =gcomm://) pour lancer le nœud en tant que composant principal. Vous pouvez également exécuter le script d'amorçage fourni, appelé galera_new_cluster, qui fait essentiellement une chose similaire mais en arrière-plan.
Déploiement du cluster Galera (MariaDB)
Le déploiement de Galera Cluster nécessite une configuration supplémentaire sur la source APT pour installer le référentiel de version MariaDB préféré.
Notez que la réplication Galera est intégrée à MariaDB Server et ne nécessite l'installation d'aucun package supplémentaire. Cela étant dit, un indicateur supplémentaire est requis pour activer Galera en utilisant wsrep_on=ON. Sans cet indicateur, MariaDB agira comme un serveur autonome.
Dans notre environnement basé sur Debian, l'option wsrep_on ne peut être présente dans le manifeste qu'une fois le premier déploiement terminé (comme indiqué plus bas dans les étapes de déploiement). Cela permet de s'assurer que le premier démarrage initial agit comme un serveur autonome pour que Puppet provisionne le nœud avant qu'il ne soit complètement prêt à être un nœud Galera.
Commençons par préparer le contenu du manifeste comme ci-dessous (modifiez la section des variables globales si nécessaire) :
# Puppet manifest for Galera Cluster MariaDB 10.3 on Ubuntu 18.04 (Puppet v6.4.2)
# /etc/puppetlabs/code/environments/production/manifests/galera.pp
# global vars
$sst_user = 'sstuser'
$sst_password = 'S3cr333t$'
$backup_dir = '/home/backup/mysql'
$mysql_cluster_address = 'gcomm://192.168.0.161,192.168.0.162,192.168.0.163'
# node definition
node "db1.local", "db2.local", "db3.local" {
Apt::Source['mariadb'] ~>
Class['apt::update'] ->
Class['mysql::server'] ->
Class['mysql::backup::xtrabackup']
}
# apt module must be installed first: 'puppet module install puppetlabs-apt'
include apt
# custom repository definition
apt::source { 'mariadb':
location => 'https://sfo1.mirrors.digitalocean.com/mariadb/repo/10.3/ubuntu',
release => $::lsbdistcodename,
repos => 'main',
key => {
id => 'A6E773A1812E4B8FD94024AAC0F47944DE8F6914',
server => 'hkp://keyserver.ubuntu.com:80',
},
include => {
src => false,
deb => true,
},
}
# Galera configuration
class {'mysql::server':
package_name => 'mariadb-server',
root_password => 'example@sqldat.com#',
service_name => 'mysql',
create_root_my_cnf => true,
remove_default_accounts => true,
manage_config_file => true,
override_options => {
'mysqld' => {
'datadir' => '/var/lib/mysql',
'bind_address' => '0.0.0.0',
'binlog-format' => 'ROW',
'default-storage-engine' => 'InnoDB',
'wsrep_provider' => '/usr/lib/galera/libgalera_smm.so',
'wsrep_provider_options' => 'gcache.size=1G',
'wsrep_cluster_name' => 'galera_cluster',
'wsrep_cluster_address' => $mysql_cluster_address,
'log-error' => '/var/log/mysql/error.log',
'wsrep_node_address' => $facts['networking']['interfaces']['enp0s8']['ip'],
'wsrep_node_name' => $hostname,
'innodb_buffer_pool_size' => '512M',
'wsrep_sst_method' => 'mariabackup',
'wsrep_sst_auth' => "${sst_user}:${sst_password}"
},
'mysqld_safe' => {
'log-error' => '/var/log/mysql/error.log'
}
}
}
# force creation of backup dir if not exist
exec { "mkdir -p ${backup_dir}" :
path => ['/bin','/usr/bin'],
unless => "test -d ${backup_dir}"
}
# create SST and backup user
class { 'mysql::backup::xtrabackup' :
xtrabackup_package_name => 'mariadb-backup',
backupuser => "${sst_user}",
backuppassword => "${sst_password}",
backupmethod => 'mariabackup',
backupdir => "${backup_dir}"
}
# /etc/hosts definition
host {
'db1.local': ip => '192.168.0.161';
'db2.local': ip => '192.169.0.162';
'db3.local': ip => '192.168.0.163';
}Un peu d'explication est nécessaire à ce stade. 'wsrep_node_address' doit pointer vers la même adresse IP que celle déclarée dans wsrep_cluster_address. Dans cet environnement, nos hôtes ont deux interfaces réseau et nous voulons utiliser la deuxième interface (appelée enp0s8) pour la communication Galera (où le réseau 192.168.0.0/24 est connecté). C'est pourquoi nous utilisons le facteur Puppet pour obtenir les informations du nœud et les appliquer à l'option de configuration. Le reste est assez explicite.
Sur chaque nœud MariaDB, exécutez la commande suivante pour appliquer le catalogue en tant qu'utilisateur root :
$ puppet agent -tLe catalogue sera appliqué à chaque nœud pour l'installation et la préparation. Une fois cela fait, nous devons ajouter la ligne suivante dans notre manifeste sous la section "override_options => mysqld":
'wsrep_on' => 'ON',Ce qui précède satisfera à l'exigence Galera pour MariaDB. Ensuite, appliquez à nouveau le catalogue sur chaque nœud MariaDB :
$ puppet agent -tUne fois cela fait, nous sommes prêts à démarrer notre cluster. Puisqu'il s'agit d'un nouveau cluster, nous pouvons choisir n'importe quel nœud comme nœud de référence, c'est-à-dire le nœud d'amorçage. Choisissons db1.local (192.168.0.161) et exécutons la commande suivante :
$ galera_new_cluster #db1Une fois le premier nœud démarré, nous pouvons démarrer le nœud restant avec la commande de démarrage standard (un nœud à la fois) :
$ systemctl restart mariadb #db2 and db3Une fois démarré, jetez un coup d'œil au journal des erreurs MySQL sur /var/log/mysql/error.log et assurez-vous que le journal se termine par la ligne suivante :
2019-06-10 4:11:10 2 [Note] WSREP: Synchronized with group, ready for connectionsCe qui précède nous indique que les nœuds sont synchronisés avec le groupe. Nous pouvons ensuite vérifier le statut en utilisant la commande suivante :
$ mysql -uroot -e 'show status like "wsrep%"'Assurez-vous que sur tous les nœuds, le wsrep_cluster_size , wsrep_cluster_status et wsrep_local_state_comment sont 3, "Primaire" et "Synchronisé" respectivement.
Gestion MySQL
Ce module peut être utilisé pour effectuer un certain nombre de tâches de gestion MySQL...
- options de configuration (modifier, appliquer, configuration personnalisée)
- Ressources de la base de données (base de données, utilisateur, subventions)
- sauvegarde (création, planification, utilisateur de sauvegarde, stockage)
- restauration simple (mysqldump uniquement)
- installation/activation des plugins
Contrôle des services
Le moyen le plus sûr lors de l'approvisionnement de Galera Cluster avec Puppet est de gérer manuellement toutes les opérations de contrôle de service (ne laissez pas Puppet le faire). Pour un simple redémarrage progressif du cluster, la commande de service standard ferait l'affaire. Exécutez la commande suivante un nœud à la fois.
$ systemctl restart mariadb # Systemd
$ service mariadb restart # SysVinitCependant, dans le cas où une partition réseau se produit et qu'aucun composant principal n'est disponible (vérifiez avec wsrep_cluster_status ), le nœud le plus récent doit être amorcé pour rendre le cluster opérationnel sans perte de données. Vous pouvez suivre les étapes indiquées dans la section de déploiement ci-dessus. Pour en savoir plus sur le processus d'amorçage avec des exemples de scénario, nous avons couvert cela en détail dans cet article de blog, Comment amorcer MySQL ou MariaDB Galera Cluster.
Ressource de base de données
Utilisez la classe mysql::db pour vous assurer qu'une base de données avec l'utilisateur et les privilèges associés est présente, par exemple :
# make sure the database and user exist with proper grant
mysql::db { 'mynewdb':
user => 'mynewuser',
password => 'passw0rd',
host => '192.168.0.%',
grant => ['SELECT', 'UPDATE']
} La définition ci-dessus peut être attribuée à n'importe quel nœud puisque chaque nœud d'un cluster Galera est un maître.
Sauvegarde et restauration
Puisque nous avons créé un utilisateur SST à l'aide de la classe xtrabackup, Puppet configurera tous les prérequis pour la tâche de sauvegarde - création de l'utilisateur de sauvegarde, préparation du chemin de destination, attribution de la propriété et de l'autorisation, définition de la tâche cron et configuration des options de commande de sauvegarde à utiliser dans le script de sauvegarde fourni. Chaque nœud sera configuré avec deux tâches de sauvegarde (une pour l'hebdomadaire complet et l'autre pour l'incrémentale quotidienne) par défaut à 23h05, comme vous pouvez le voir à partir de la sortie crontab :
$ crontab -l
# Puppet Name: xtrabackup-weekly
5 23 * * 0 /usr/local/sbin/xtrabackup.sh --target-dir=/home/backup/mysql --backup
# Puppet Name: xtrabackup-daily
5 23 * * 1-6 /usr/local/sbin/xtrabackup.sh --incremental-basedir=/home/backup/mysql --target-dir=/home/backup/mysql/`date +%F_%H-%M-%S` --backupSi vous souhaitez planifier mysqldump à la place, utilisez la classe mysql::server::backup pour préparer les ressources de sauvegarde. Supposons que nous ayons la déclaration suivante dans notre manifeste :
# Prepare the backup script, /usr/local/sbin/mysqlbackup.sh
class { 'mysql::server::backup':
backupuser => 'backup',
backuppassword => 'passw0rd',
backupdir => '/home/backup',
backupdirowner => 'mysql',
backupdirgroup => 'mysql',
backupdirmode => '755',
backuprotate => 15,
time => ['23','30'], #backup starts at 11:30PM everyday
include_routines => true,
include_triggers => true,
ignore_events => false,
maxallowedpacket => '64M'
}Ce qui précède indique à Puppet de configurer le script de sauvegarde sur /usr/local/sbin/mysqlbackup.sh et de le programmer à 23h30 tous les jours. Si vous souhaitez effectuer une sauvegarde immédiate, invoquez simplement :
$ mysqlbackup.shPour la restauration, le module ne prend en charge que la restauration avec la méthode de sauvegarde mysqldump, en important le fichier SQL directement dans la base de données à l'aide de la classe mysql::db, par exemple :
mysql::db { 'mydb':
user => 'myuser',
password => 'mypass',
host => 'localhost',
grant => ['ALL PRIVILEGES'],
sql => '/home/backup/mysql/mydb/backup.gz',
import_cat_cmd => 'zcat',
import_timeout => 900
}Le fichier SQL ne sera chargé qu'une seule fois et non à chaque exécution, à moins que l'enforce_sql => true ne soit utilisé.
Gestion des configurations
Dans cet exemple, nous avons utilisé manage_config_file => true avec override_options pour structurer nos lignes de configuration qui seront ensuite poussées par Puppet. Toute modification du fichier manifeste ne reflétera que le contenu du fichier de configuration MySQL cible. Ce module ne chargera pas la configuration dans l'exécution ni ne redémarrera le service MySQL après avoir poussé les modifications dans le fichier de configuration. Il est de la responsabilité de l'administrateur système de redémarrer le service afin d'activer les modifications.
Pour ajouter une configuration MySQL personnalisée, nous pouvons placer des fichiers supplémentaires dans "includir", par défaut dans /etc/mysql/conf.d. Cela nous permet de remplacer les paramètres ou d'en ajouter d'autres, ce qui est utile si vous n'utilisez pas override_options dans mysql::server class. L'utilisation du modèle Puppet est fortement recommandée ici. Placez le fichier de configuration personnalisé sous le répertoire du modèle de module (par défaut, /etc/puppetlabs/code/environments/production/modules/mysql/templates) puis ajoutez les lignes suivantes dans le manifeste :
# Loads /etc/puppetlabs/code/environments/production/modules/mysql/templates/my-custom-config.cnf.erb into /etc/mysql/conf.d/my-custom-config.cnf
file { '/etc/mysql/conf.d/my-custom-config.cnf':
ensure => file,
content => template('mysql/my-custom-config.cnf.erb')
}Marionnette vs ClusterControl
Saviez-vous que vous pouvez également automatiser le déploiement de MySQL ou MariaDB Galera en utilisant ClusterControl ? Vous pouvez utiliser le module ClusterControl Puppet pour l'installer, ou simplement en le téléchargeant depuis notre site Web.
Par rapport à ClusterControl, vous pouvez vous attendre aux différences suivantes :
- Un peu de courbe d'apprentissage pour comprendre les syntaxes, le formatage et les structures de Puppet avant de pouvoir écrire des manifestes.
- Le manifeste doit être testé régulièrement. Il est très courant que vous obteniez une erreur de compilation sur le code, surtout si le catalogue est appliqué pour la première fois.
- Puppet suppose que les codes sont idempotents. La condition de test/vérification/vérification relève de la responsabilité de l'auteur pour éviter de gâcher un système en cours d'exécution.
- Puppet nécessite un agent sur le nœud géré.
- Incompatibilité descendante. Certains anciens modules ne fonctionnaient pas correctement sur la nouvelle version.
- La surveillance de la base de données/de l'hôte doit être configurée séparément.
L'assistant de déploiement de ClusterControl guide le processus de déploiement :
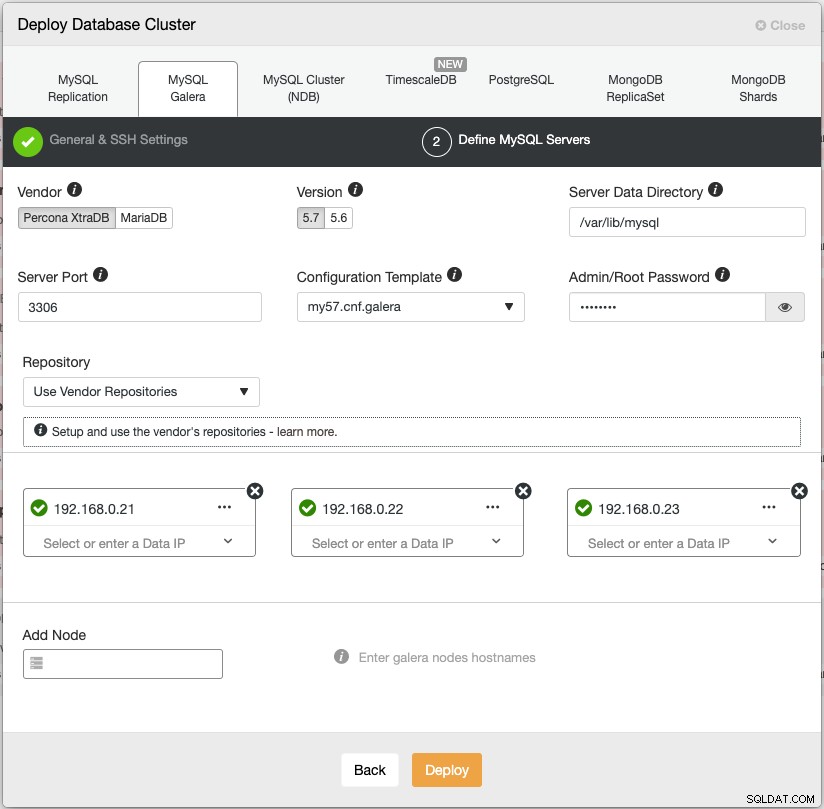
Vous pouvez également utiliser l'interface de ligne de commande ClusterControl appelée "s9s" pour obtenir des résultats similaires. La commande suivante crée un cluster Percona XtraDB à trois nœuds (fourni sans mot de passe à tous les nœuds a été configuré au préalable) :
$ s9s cluster --create \
--cluster-type=galera \
--nodes='192.168.0.21;192.168.0.22;192.168.0.23' \
--vendor=percona \
--cluster-name='Percona XtraDB Cluster 5.7' \
--provider-version=5.7 \
--db-admin='root' \
--db-admin-passwd='$ecR3t^word' \
--logDe plus, ClusterControl prend en charge le déploiement d'équilibreurs de charge pour Galera Cluster - HAproxy, ProxySQL et MariaDB MaxScale - avec une adresse IP virtuelle (fournie par Keepalived) pour éliminer tout point de défaillance unique pour votre service de base de données.
Après le déploiement, les nœuds/clusters peuvent être surveillés et entièrement gérés par ClusterControl, y compris la détection automatique des pannes, la récupération automatique, la gestion des sauvegardes, la gestion de l'équilibreur de charge, l'attachement d'un esclave asynchrone, la gestion de la configuration, etc. Tous ces éléments sont regroupés dans un seul produit. En moyenne, votre cluster de base de données sera opérationnel en 30 minutes. Ce dont il a besoin, c'est uniquement d'un SSH sans mot de passe vers les nœuds cibles.
Vous pouvez également importer un cluster Galera déjà en cours d'exécution, déployé par Puppet (ou tout autre moyen) dans ClusterControl pour suralimenter votre cluster avec toutes les fonctionnalités intéressantes qui l'accompagnent. L'édition communautaire (gratuite pour toujours !) propose le déploiement et la surveillance.
Dans le prochain épisode, nous allons vous expliquer le déploiement de l'équilibreur de charge MySQL à l'aide de Puppet. Restez à l'écoute !