J'ai eu le plaisir d'assister à PGDay UK la semaine dernière - un très bel événement, j'espère avoir la chance de revenir l'année prochaine. Il y avait beaucoup de discussions intéressantes, mais celle qui a particulièrement retenu mon attention était Performace pour les requêtes avec regroupement par Alexey Bashtanov.
J'ai donné un bon nombre de conférences similaires axées sur la performance dans le passé, donc je sais à quel point il est difficile de présenter des résultats de référence de manière compréhensible et intéressante, et Alexey a fait du bon travail, je pense. Donc, si vous traitez l'agrégation de données (c'est-à-dire la BI, l'analyse ou des charges de travail similaires), je vous recommande de parcourir les diapositives et si vous avez la chance d'assister à la présentation d'une autre conférence, je vous recommande fortement de le faire.
Mais il y a un point sur lequel je ne suis pas d'accord avec le discours. À plusieurs endroits, la discussion a suggéré que vous devriez généralement préférer HashAggregate, car les tris sont lents.
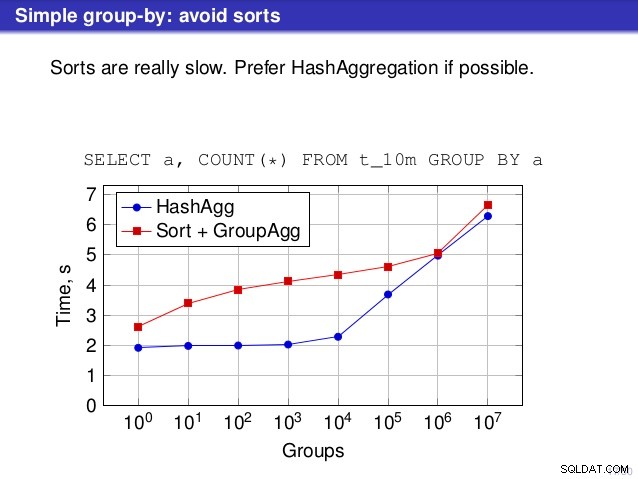
Je considère cela un peu trompeur, car une alternative à HashAggregate est GroupAggregate, pas Sort. La recommandation suppose donc que chaque GroupAggregate a un tri imbriqué, mais ce n'est pas tout à fait vrai. GroupAggregate nécessite une entrée triée, et un tri explicite n'est pas le seul moyen de le faire - nous avons également des nœuds IndexScan et IndexOnlyScan, qui éliminent les coûts de tri et conservent les autres avantages associés aux chemins triés (en particulier IndexOnlyScan).
Permettez-moi de démontrer comment (IndexOnlyScan+GroupAggregate) fonctionne par rapport à HashAggregate et (Sort+GroupAggregate) - le script que j'ai utilisé pour les mesures est ici. Il construit quatre tables simples, chacune avec 100 millions de lignes et un nombre différent de groupes dans la colonne "branch_id" (déterminant la taille de la table de hachage). Le plus petit a 10k groupes
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
et trois tables supplémentaires ont des groupes 100k, 1M et 5M. Exécutons cette requête simple en agrégeant les données :
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
puis convaincre la base de données d'utiliser trois plans différents :
1) Agrégat de hachage
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (avec un tri)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (avec un IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Résultats
Après avoir mesuré les délais de chaque plan sur toutes les tables, les résultats ressemblent à ceci :
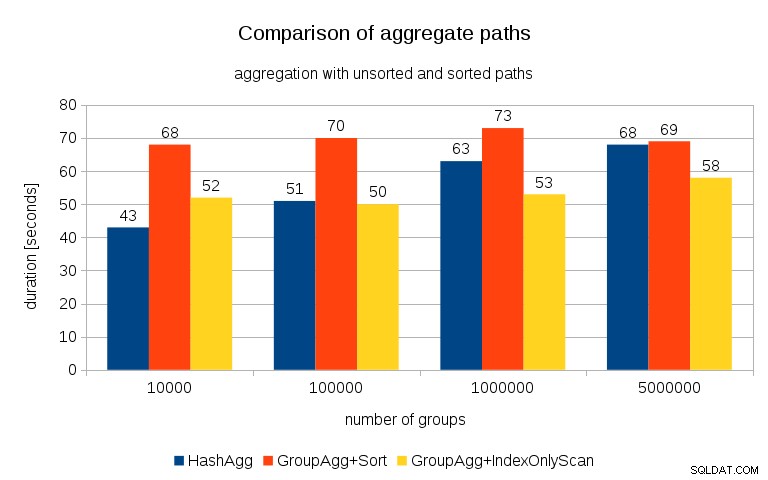
Pour les petites tables de hachage (convenant au cache L3, qui est de 16 Mo dans ce cas), le chemin HashAggregate est clairement plus rapide que les deux chemins triés. Mais bientôt GroupAgg+IndexOnlyScan devient tout aussi rapide ou même plus rapide - cela est dû à l'efficacité du cache, le principal avantage de GroupAggregate. Alors que HashAggregate doit conserver toute la table de hachage en mémoire à la fois, GroupAggregate n'a besoin de conserver que le dernier groupe. Et moins vous utilisez de mémoire, plus il est probable qu'elle s'intègre dans le cache L3, qui est à peu près un ordre de grandeur plus rapide par rapport à la RAM ordinaire (pour les caches L1/L2, la différence est encore plus grande).
Ainsi, bien qu'il y ait une surcharge considérable associée à IndexOnlyScan (pour le cas 10k, il est environ 20% plus lent que le chemin HashAggregate), à mesure que la table de hachage augmente, le taux d'accès au cache L3 diminue rapidement et la différence finit par rendre le GroupAggregate plus rapide. Et finalement, même le chemin GroupAggregate+Sort est à égalité avec le chemin HashAggregate.
Vous pourriez dire que vos données ont généralement un nombre assez faible de groupes, et donc la table de hachage tiendra toujours dans le cache L3. Mais considérez que le cache L3 est partagé par tous les processus exécutés sur le processeur, ainsi que par toutes les parties du plan de requête. Ainsi, bien que nous disposions actuellement d'environ 20 Mo de cache L3 par socket, votre requête n'en obtiendra qu'une partie, et ce bit sera partagé par tous les nœuds de votre requête (éventuellement assez complexe).
Mise à jour 2016/07/26 :Comme indiqué dans les commentaires de Peter Geoghegan, la façon dont les données ont été générées entraîne probablement une corrélation - pas les valeurs (ou plutôt les hachages des valeurs), mais les allocations de mémoire. J'ai répété les requêtes avec des données correctement randomisées, c'est-à-dire faisant
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
au lieu de
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
et les résultats ressemblent à ceci :
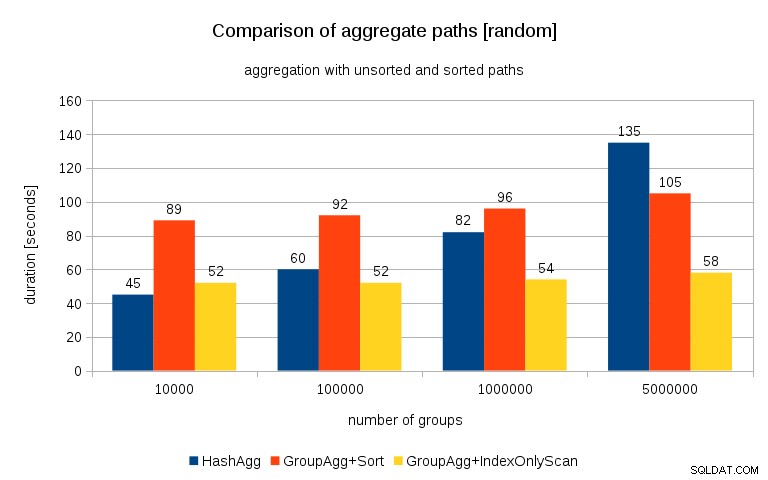
En comparant cela avec le graphique précédent, je pense qu'il est assez clair que les résultats sont encore plus en faveur des chemins triés, en particulier pour l'ensemble de données avec des groupes de 5M. L'ensemble de données 5M montre également que GroupAgg avec un tri explicite peut être plus rapide que HashAgg.
Résumé
Bien que HashAggregate soit probablement plus rapide que GroupAggregate avec un tri explicite (j'hésite à dire que c'est toujours le cas, cependant), l'utilisation plus rapide de GroupAggregate avec IndexOnlyScan peut facilement le rendre beaucoup plus rapide que HashAggregate.
Bien sûr, vous ne pouvez pas choisir directement le plan exact - le planificateur devrait le faire pour vous. Mais vous affectez le processus de sélection en (a) créant des index et (b) en définissant work_mem . C'est pourquoi parfois inférieur work_mem (et maintenance_work_mem ) entraînent de meilleures performances.
Cependant, les index supplémentaires ne sont pas gratuits - ils coûtent à la fois du temps CPU (lors de l'insertion de nouvelles données) et de l'espace disque. Pour IndexOnlyScans, les besoins en espace disque peuvent être assez importants car l'index doit inclure toutes les colonnes référencées par la requête, et IndexScan normal ne vous offrirait pas les mêmes performances car il génère beaucoup d'E/S aléatoires sur la table (éliminant toutes les gains potentiels).
Une autre fonctionnalité intéressante est la stabilité des performances - notez comment les timings HashAggregate varient en fonction du nombre de groupes, tandis que les chemins GroupAggregate fonctionnent généralement de la même manière.