Comme nous l'avons récemment annoncé, ClusterControl 1.7.4 a une nouvelle fonctionnalité appelée Cluster-to-Cluster Replication. Il vous permet d'avoir une réplication en cours d'exécution entre deux clusters autonomes. Pour plus d'informations, veuillez vous référer à l'annonce mentionnée ci-dessus.
Nous verrons comment utiliser cette nouvelle fonctionnalité pour un cluster PostgreSQL existant. Pour cette tâche, nous supposerons que vous avez installé ClusterControl et que le cluster maître a été déployé à l'aide de celui-ci.
Exigences pour le cluster maître
Il y a certaines exigences pour que le cluster principal fonctionne :
- PostgreSQL 9.6 ou version ultérieure.
- Il doit y avoir un serveur PostgreSQL avec le rôle ClusterControl 'Master'.
- Lors de la configuration du cluster esclave, les informations d'identification de l'administrateur doivent être identiques à celles du cluster maître.
Préparer le cluster maître
Le cluster principal doit répondre aux exigences mentionnées ci-dessus.
En ce qui concerne la première exigence, assurez-vous que vous utilisez la bonne version de PostgreSQL dans le cluster maître et choisissez la même chose pour le cluster esclave.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitSi vous devez attribuer le rôle de maître à un nœud spécifique, vous pouvez le faire à partir de l'interface utilisateur de ClusterControl. Accédez à ClusterControl -> Sélectionnez le cluster maître -> Nœuds -> Sélectionnez le nœud -> Actions du nœud -> Promouvoir l'esclave.
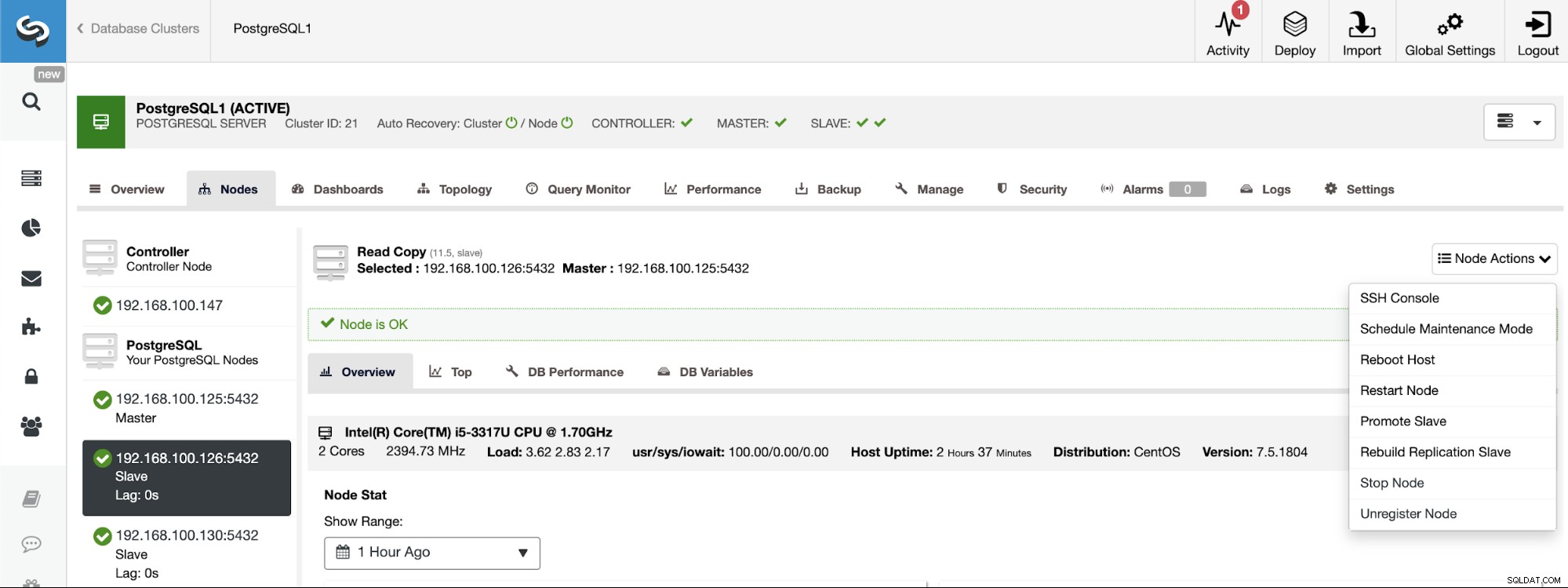
Et enfin, lors de la création du cluster esclave, vous devez utiliser le même administrateur informations d'identification que vous utilisez actuellement dans le cluster maître. Vous verrez où l'ajouter dans la section suivante.
Création du cluster esclave à partir de l'interface utilisateur ClusterControl
Pour créer un nouveau cluster esclave, accédez à ClusterControl -> Sélectionner un cluster -> Actions du cluster -> Créer un cluster esclave.
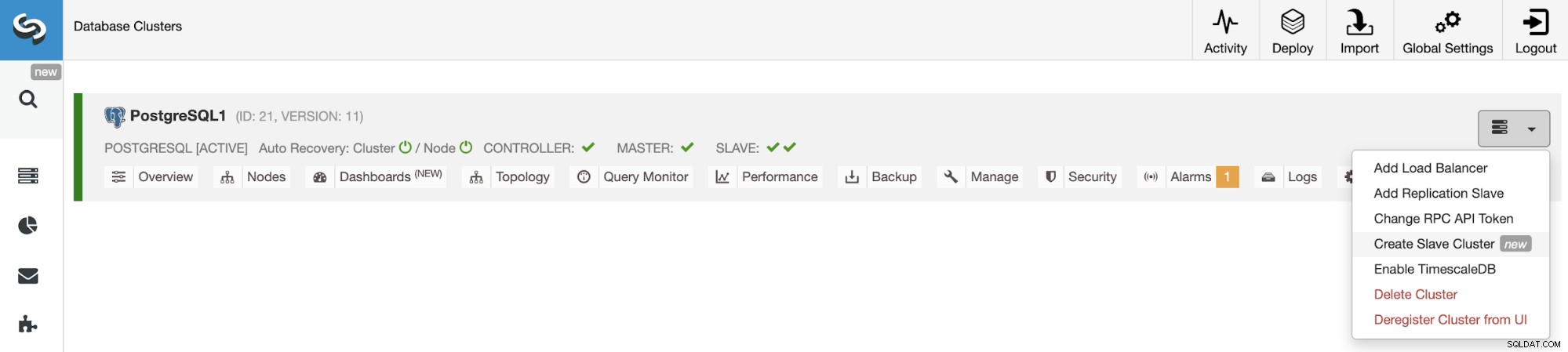
Le cluster esclave sera créé en diffusant les données du cluster maître actuel.
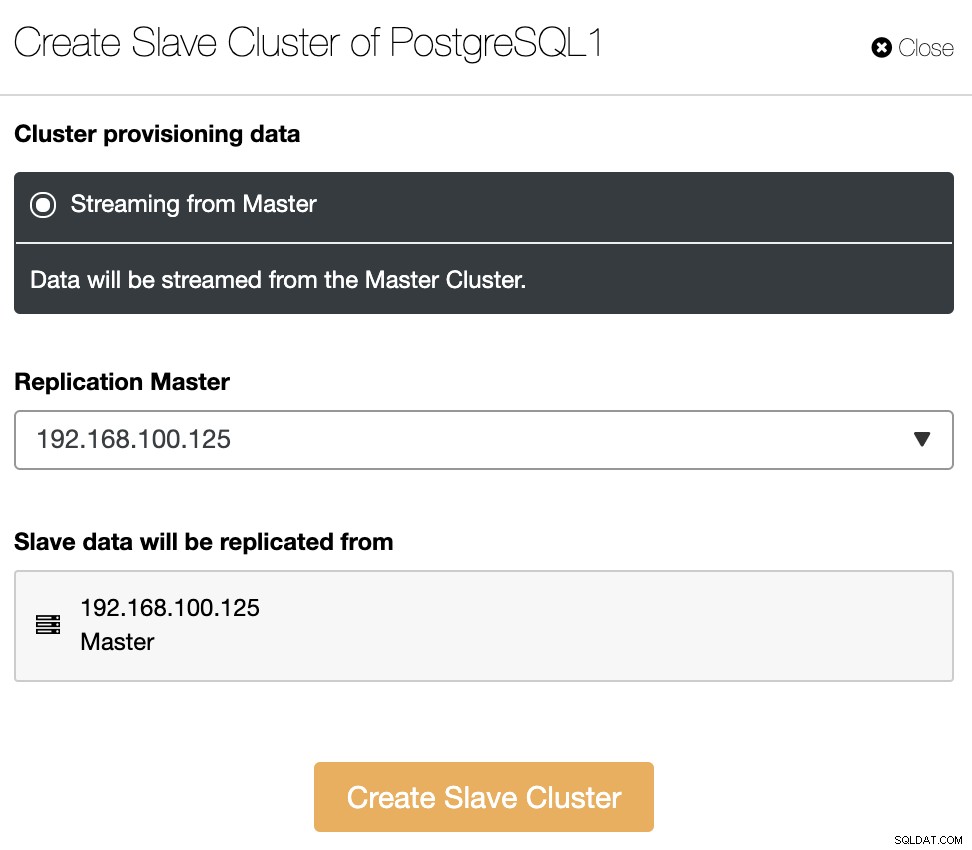
Dans cette section, vous devez également choisir le nœud maître du cluster actuel à partir duquel les données seront répliquées.
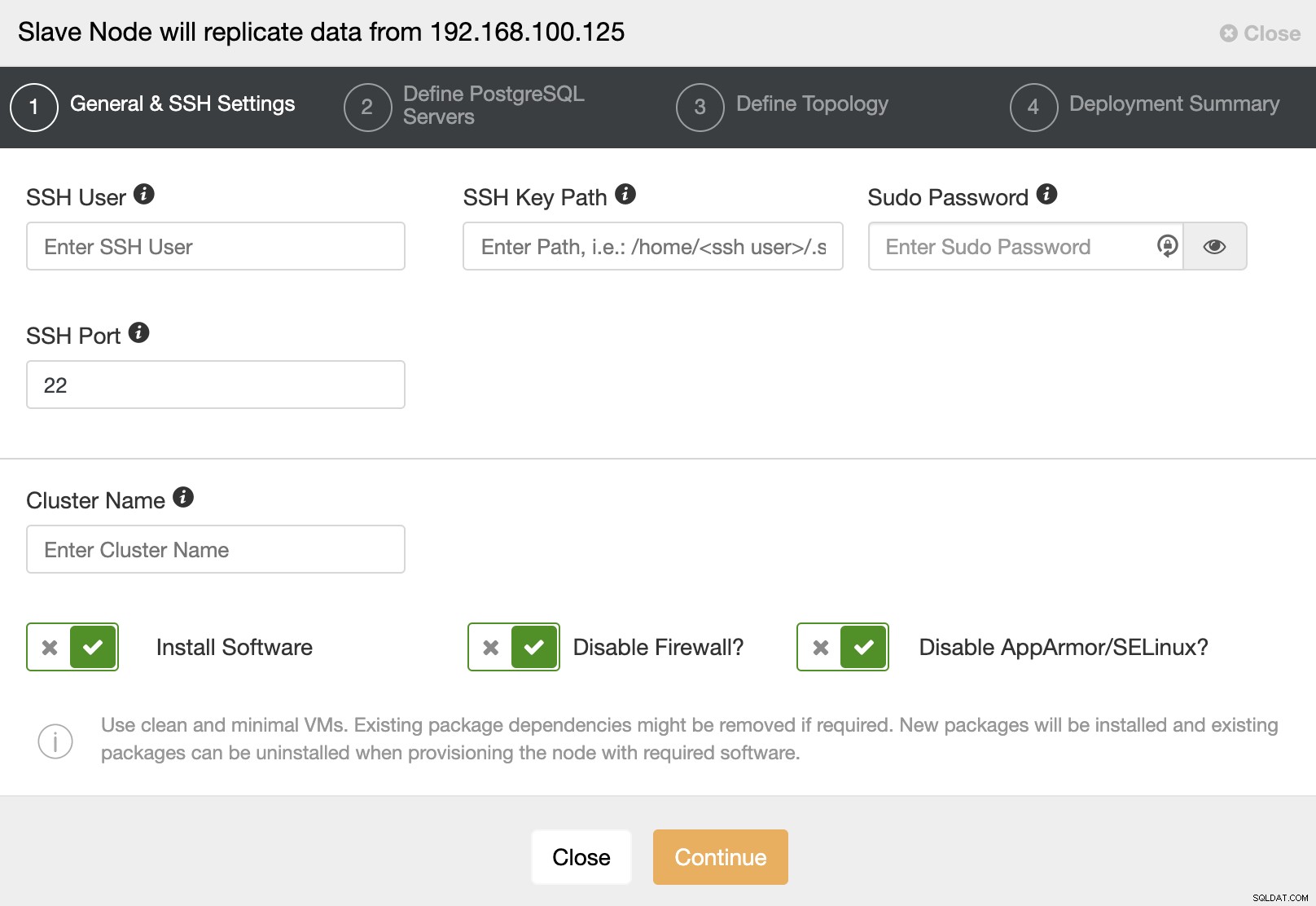
Lorsque vous passez à l'étape suivante, vous devez spécifier Utilisateur, Clé ou Mot de passe et port pour se connecter en SSH à vos serveurs. Vous avez également besoin d'un nom pour votre cluster esclave et si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
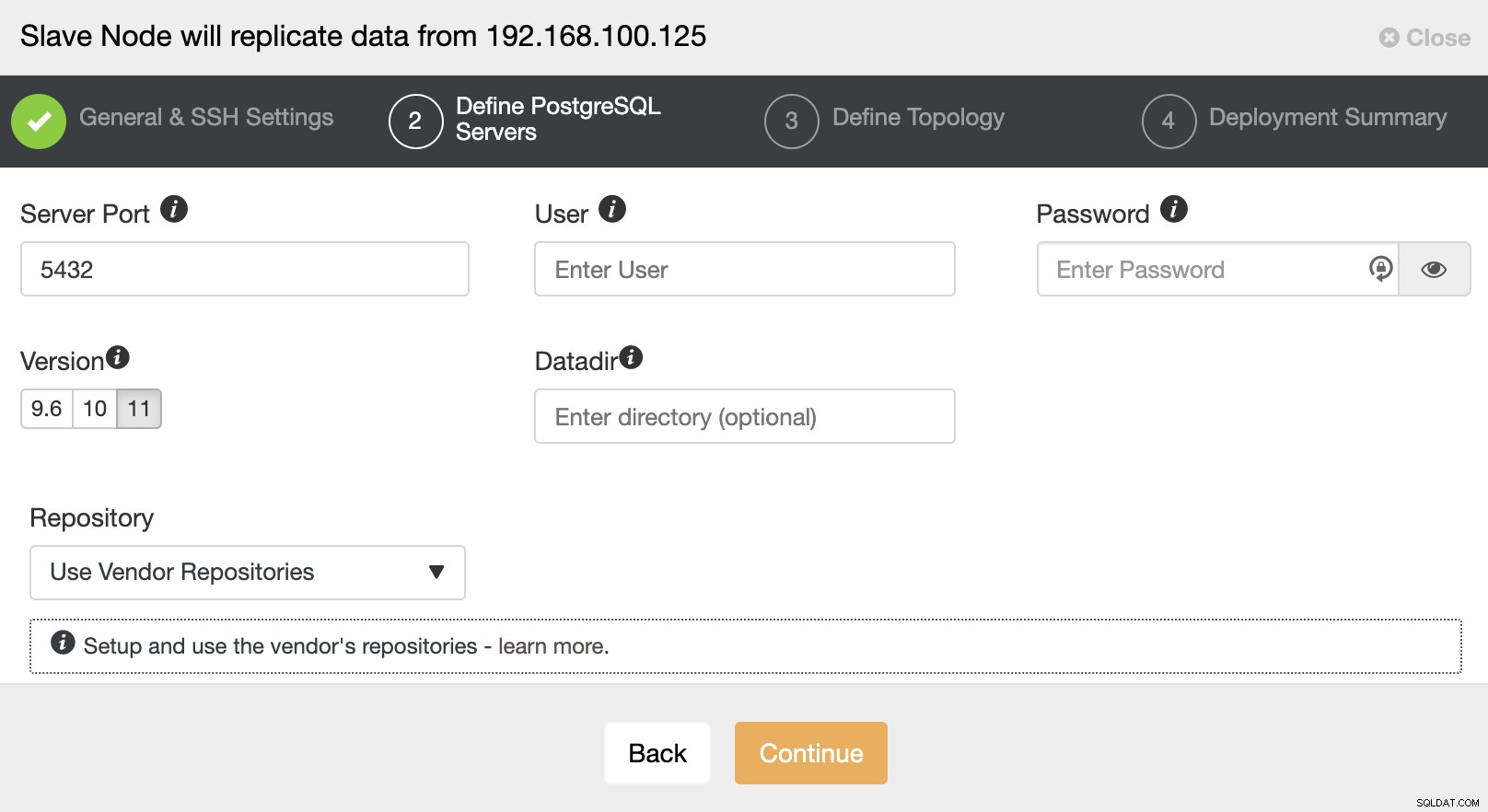
Après avoir configuré les informations d'accès SSH, vous devez définir la version de la base de données, datadir, port et informations d'identification d'administrateur. Comme il utilisera la réplication en continu, assurez-vous d'utiliser la même version de base de données et, comme nous l'avons mentionné précédemment, les informations d'identification doivent être les mêmes que celles utilisées par le cluster maître. Vous pouvez également spécifier le référentiel à utiliser.
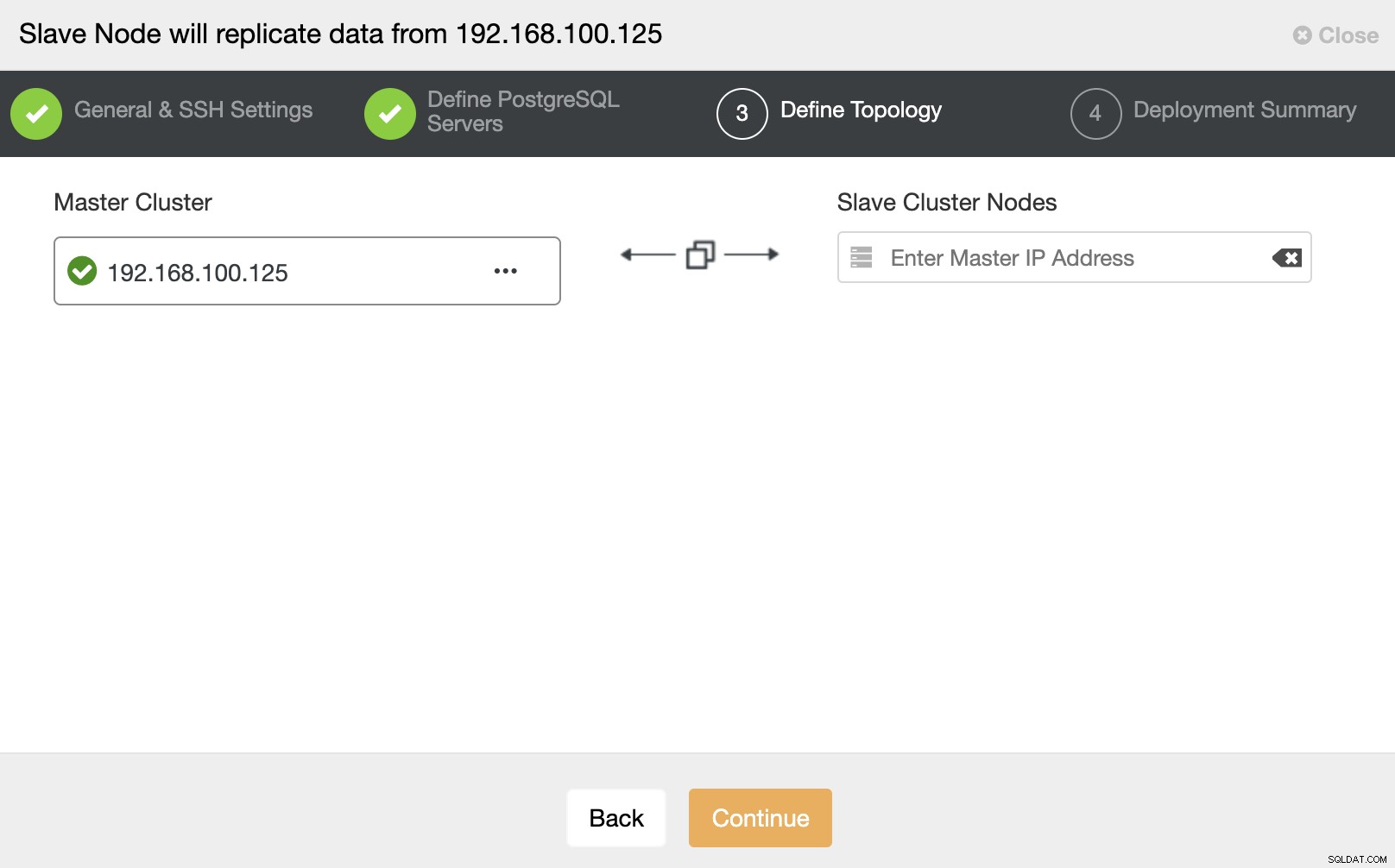
Dans cette étape, vous devez ajouter le serveur au nouveau cluster esclave . Pour cette tâche, vous pouvez entrer à la fois l'adresse IP ou le nom d'hôte du nœud de la base de données.
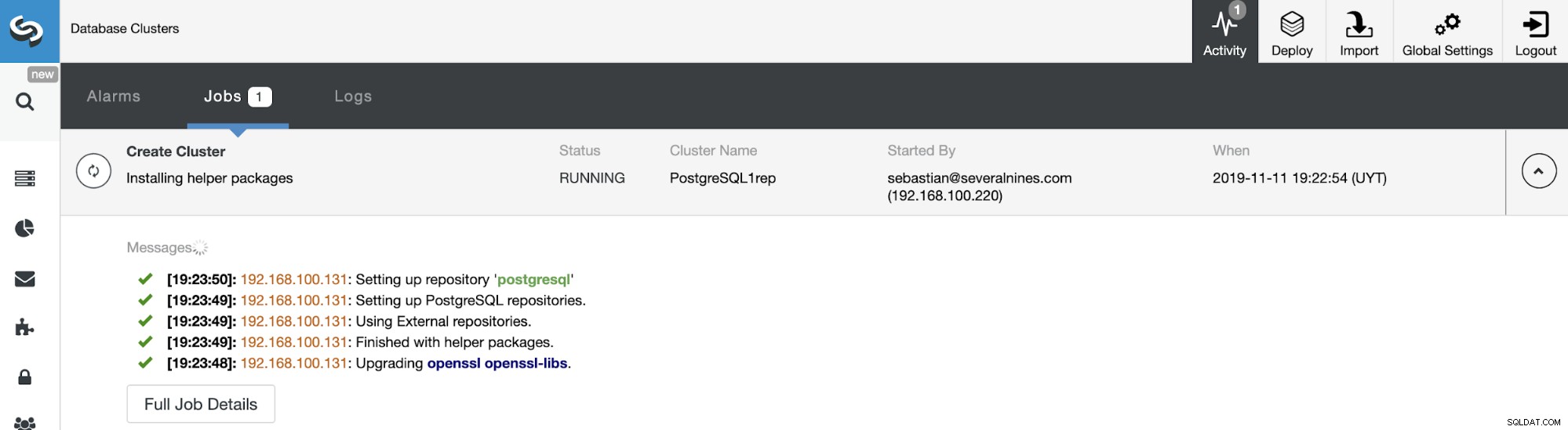
Vous pouvez surveiller l'état de la création de votre nouveau cluster esclave depuis le Moniteur d'activité ClusterControl. Une fois la tâche terminée, vous pouvez voir le cluster dans l'écran principal de ClusterControl.
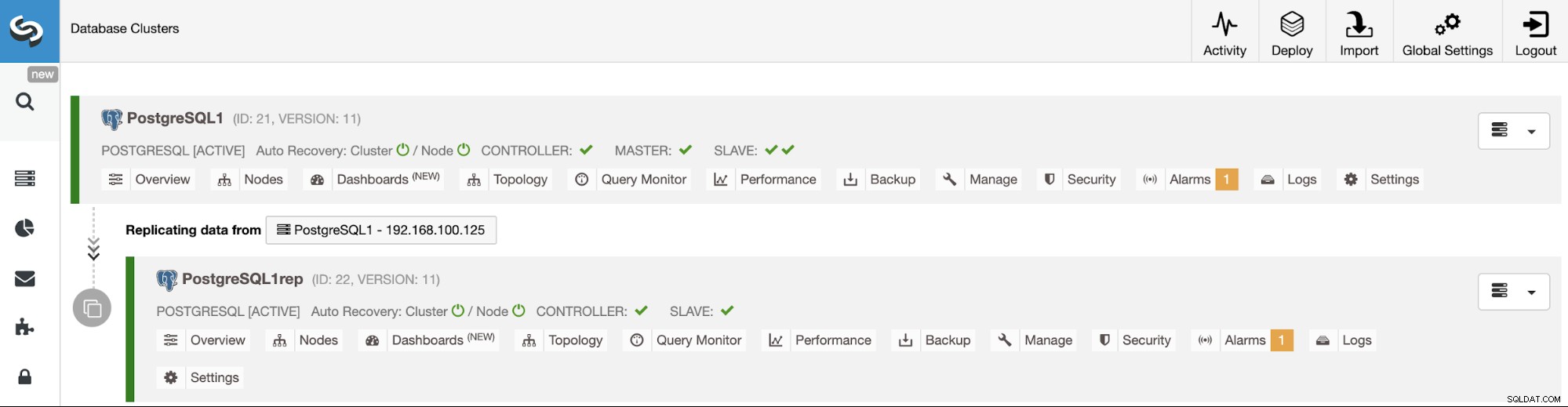
Gestion de la réplication cluster à cluster à l'aide de l'interface utilisateur ClusterControl
Maintenant que votre réplication de cluster à cluster est opérationnelle, il y a différentes actions à effectuer sur cette topologie à l'aide de ClusterControl.
Reconstruire un cluster esclave
Pour reconstruire un cluster esclave, accédez à ClusterControl -> Sélectionnez le cluster esclave -> Nœuds -> Choisissez le nœud connecté au cluster maître -> Actions du nœud -> Reconstruire l'esclave de réplication.
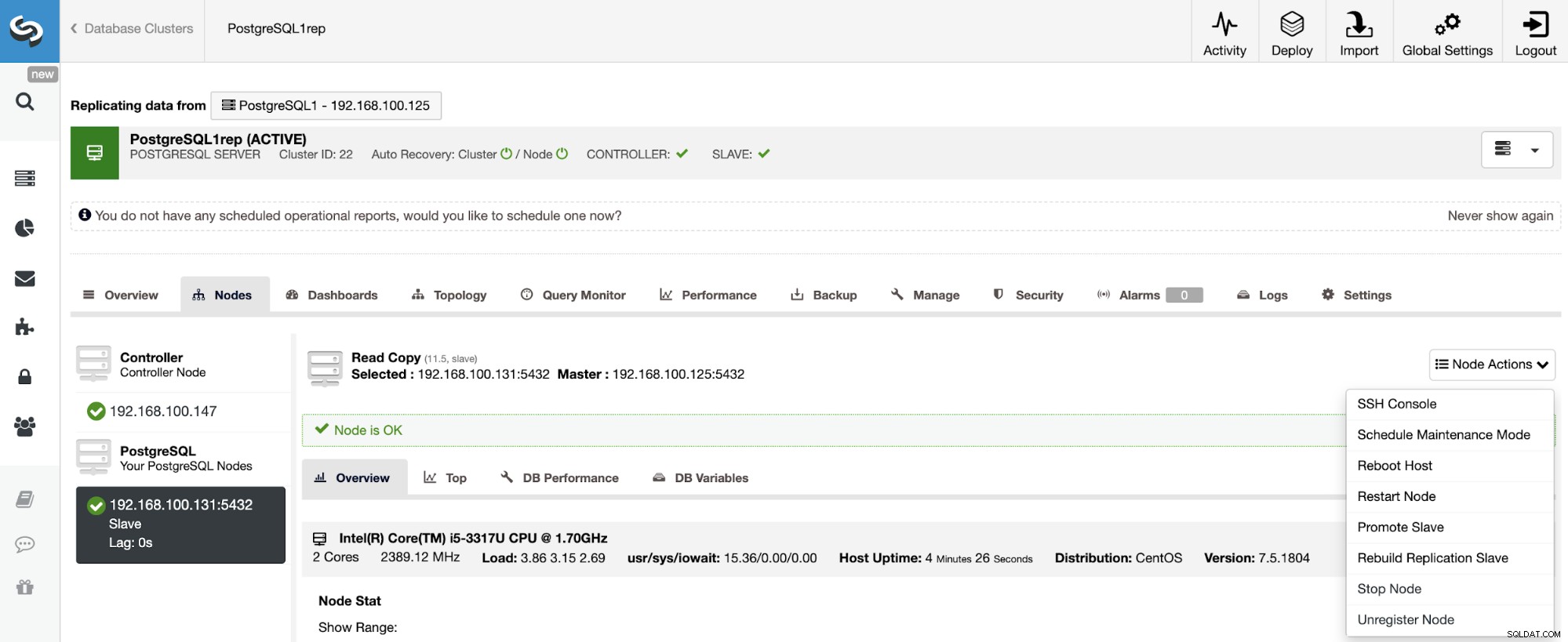
ClusterControl effectuera les étapes suivantes :
- Arrêter le serveur PostgreSQL
- Supprimer le contenu de son répertoire de données
- Diffusez une sauvegarde du maître vers l'esclave à l'aide de pg_basebackup
- Démarrer l'esclave
Arrêter/Démarrer l'esclave de réplication
L'arrêt et le démarrage de la réplication dans PostgreSQL signifient la mettre en pause et la reprendre, mais nous utilisons ces termes pour être cohérents avec les autres technologies de base de données que nous prenons en charge.
Cette fonction sera bientôt disponible à partir de l'interface utilisateur de ClusterControl. Cette action utilisera les fonctions PostgreSQL pg_wal_replay_pause et pg_wal_replay_resume pour effectuer cette tâche.
En attendant, vous pouvez utiliser une solution de contournement pour arrêter et démarrer l'esclave de réplication en arrêtant et en démarrant le nœud de base de données de manière simple à l'aide de ClusterControl.
Aller à ClusterControl -> Select Slave Cluster -> Nodes -> Choisissez le Nœud -> Actions de nœud -> Arrêter le nœud/Démarrer le nœud. Cette action arrêtera/démarrera le service de base de données directement.
Gestion de la réplication de cluster à cluster à l'aide de l'interface de ligne de commande ClusterControl
Dans la section précédente, vous avez pu voir comment gérer une réplication de cluster à cluster à l'aide de l'interface utilisateur de ClusterControl. Voyons maintenant comment le faire en utilisant la ligne de commande.
Remarque :comme nous l'avons mentionné au début de ce blog, nous supposerons que vous avez installé ClusterControl et que le cluster principal a été déployé à l'aide de celui-ci.
Créer le cluster esclave
Tout d'abord, voyons un exemple de commande pour créer un cluster esclave à l'aide de la CLI ClusterControl :
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logMaintenant que votre processus de création d'esclave est en cours d'exécution, voyons chaque paramètre utilisé :
- Cluster :pour répertorier et manipuler les clusters.
- Créer :créez et installez un nouveau cluster.
- Cluster-name :le nom du nouveau cluster esclave.
- Cluster-type :le type de cluster à installer.
- Provider-version :la version du logiciel.
- Nœuds :liste des nouveaux nœuds du cluster esclave.
- Os-user :le nom d'utilisateur pour les commandes SSH.
- Os-key-file :fichier de clé à utiliser pour la connexion SSH.
- Db-admin :le nom d'utilisateur de l'administrateur de la base de données.
- Db-admin-passwd :le mot de passe de l'administrateur de la base de données.
- Remote-cluster-id :ID de cluster maître pour la réplication de cluster à cluster.
- Journal :attendez et surveillez les messages de tâche.
En utilisant le drapeau --log, vous pourrez voir les journaux en temps réel :
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Reconstruire un cluster esclave
Vous pouvez reconstruire un cluster esclave à l'aide de la commande suivante :
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logLes paramètres sont :
- Réplication :pour surveiller et contrôler la réplication des données.
- Étape :étape/reconstruction d'un esclave de réplication.
- Maître :maître de réplication dans le cluster maître.
- Esclave :l'esclave de réplication dans le cluster esclave.
- Cluster-id :l'ID du cluster esclave.
- Remote-cluster-id :l'ID du cluster principal.
- Journal :attendez et surveillez les messages de tâche.
Le journal des tâches doit ressembler à celui-ci :
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Arrêter/Démarrer l'esclave de réplication
Comme nous l'avons mentionné dans la section de l'interface utilisateur, l'arrêt et le démarrage de la réplication dans PostgreSQL signifie la mettre en pause et la reprendre, mais nous utilisons ces termes pour conserver le parallélisme avec d'autres technologies.
Vous pouvez arrêter de répliquer les données du cluster maître de cette manière :
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logVous verrez ceci :
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Et maintenant, vous pouvez le redémarrer :
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logDonc, vous verrez :
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Maintenant, vérifions les paramètres utilisés.
- Réplication :pour surveiller et contrôler la réplication des données.
- Stop/Start :pour que l'esclave arrête/démarre la réplication.
- Esclave :le nœud esclave de réplication.
- Cluster-id :ID du cluster dans lequel se trouve le nœud esclave.
- Journal :attendez et surveillez les messages de tâche.
Conclusion
Cette nouvelle fonctionnalité ClusterControl vous permettra de configurer rapidement la réplication entre différents clusters PostgreSQL et de gérer la configuration de manière simple et conviviale. L'équipe de développement de Manynines travaille à l'amélioration de cette fonctionnalité, donc toute idée ou suggestion serait la bienvenue.