La haute disponibilité est une exigence pour presque toutes les entreprises du monde utilisant PostgreSQL. Il est bien connu que PostgreSQL utilise la réplication en continu comme méthode de réplication. PostgreSQL Streaming Replication est asynchrone par défaut, il est donc possible que certaines transactions soient validées dans le nœud principal qui n'ont pas encore été répliquées sur le serveur de secours. Cela signifie qu'il existe un risque de perte potentielle de données.
Ce délai dans le processus de validation est censé être très faible... si le serveur de secours est suffisamment puissant pour suivre la charge. Si ce petit risque de perte de données n'est pas acceptable dans l'entreprise, vous pouvez également utiliser la réplication synchrone au lieu de la réplication par défaut.
Dans la réplication synchrone, chaque validation d'une transaction d'écriture attendra la confirmation que la validation a été écrite dans le journal d'écriture anticipée sur le disque du serveur principal et du serveur de secours.
Cette méthode minimise la possibilité de perte de données. Pour qu'une perte de données se produise, il faudrait que le primaire et le standby tombent en panne en même temps.
L'inconvénient de cette méthode est le même pour toutes les méthodes synchrones car avec cette méthode le temps de réponse pour chaque transaction d'écriture augmente. Cela est dû à la nécessité d'attendre jusqu'à toutes les confirmations que la transaction a été validée. Heureusement, les transactions en lecture seule ne seront pas affectées par cela mais ; uniquement les transactions d'écriture.
Dans ce blog, vous montrez comment installer un cluster PostgreSQL à partir de zéro, convertir la réplication asynchrone (par défaut) en une réplication synchrone. Je vais également vous montrer comment revenir en arrière si le temps de réponse n'est pas acceptable, car vous pouvez facilement revenir à l'état précédent. Vous verrez comment déployer, configurer et surveiller facilement une réplication synchrone PostgreSQL à l'aide de ClusterControl en utilisant un seul outil pour l'ensemble du processus.
Installer un cluster PostgreSQL
Commençons par installer et configurer une réplication PostgreSQL asynchrone, c'est-à-dire le mode de réplication habituel utilisé dans un cluster PostgreSQL. Nous utiliserons PostgreSQL 11 sur CentOS 7.
Installation de PostgreSQL
Suivant le guide d'installation officiel de PostgreSQL, cette tâche est assez simple.
Tout d'abord, installez le référentiel :
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstallez les packages client et serveur PostgreSQL :
$ yum install postgresql11 postgresql11-serverInitialiser la base de données :
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Sur le nœud de secours, vous pouvez éviter la dernière commande (démarrer le service de base de données) car vous restaurerez une sauvegarde binaire pour créer la réplication en continu.
Voyons maintenant la configuration requise par une réplication PostgreSQL asynchrone.
Configuration de la réplication PostgreSQL asynchrone
Configuration du nœud principal
Dans le nœud principal PostgreSQL, vous devez utiliser la configuration de base suivante pour créer une réplication asynchrone. Les fichiers qui seront modifiés sont postgresql.conf et pg_hba.conf. En général, elles sont dans le répertoire data (/var/lib/pgsql/11/data/) mais vous pouvez le vérifier côté base de données :
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Modifiez ou ajoutez les paramètres suivants dans le fichier de configuration postgresql.conf.
Ici, vous devez ajouter la ou les adresses IP sur lesquelles écouter. La valeur par défaut est 'localhost', et pour cet exemple, nous utiliserons '*' pour toutes les adresses IP du serveur.
listen_addresses = '*' Définissez le port du serveur sur lequel écouter. Par défaut 5432.
port = 5432 Déterminez la quantité d'informations écrites dans les WAL. Les valeurs possibles sont minimal, replica ou logical. La valeur hot_standby est mappée au réplica et est utilisée pour maintenir la compatibilité avec les versions précédentes.
wal_level = hot_standby Définir le nombre maximum de processus walsender, qui gèrent la connexion avec un serveur de secours.
max_wal_senders = 16Définissez le nombre minimum de fichiers WAL à conserver dans le répertoire pg_wal.
wal_keep_segments = 32La modification de ces paramètres nécessite un redémarrage du service de base de données.
$ systemctl restart postgresql-11Pg_hba.conf
Modifiez ou ajoutez les paramètres suivants dans le fichier de configuration pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Comme vous pouvez le voir, vous devez ajouter ici l'autorisation d'accès de l'utilisateur. La première colonne est le type de connexion, qui peut être hôte ou local. Ensuite, vous devez spécifier la base de données (réplication), l'utilisateur, l'adresse IP source et la méthode d'authentification. La modification de ce fichier nécessite un rechargement du service de base de données.
$ systemctl reload postgresql-11Vous devez ajouter cette configuration dans les nœuds principal et de secours, car vous en aurez besoin si le nœud de secours est promu maître en cas de panne.
Maintenant, vous devez créer un utilisateur de réplication.
Rôle de réplication
Le ROLE (utilisateur) doit avoir le privilège REPLICATION pour l'utiliser dans la réplication en continu.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEAprès avoir configuré les fichiers correspondants et la création de l'utilisateur, vous devez créer une sauvegarde cohérente à partir du nœud principal et la restaurer sur le nœud de secours.
Configuration du nœud de veille
Sur le nœud de secours, accédez au répertoire /var/lib/pgsql/11/ et déplacez ou supprimez le répertoire de données actuel :
$ cd /var/lib/pgsql/11/
$ mv data data.bkEnsuite, exécutez la commande pg_basebackup pour obtenir le répertoire de données principal actuel et attribuer le propriétaire correct (postgres) :
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataMaintenant, vous devez utiliser la configuration de base suivante pour créer une réplication asynchrone. Le fichier qui sera modifié est postgresql.conf, et vous devez créer un nouveau fichier recovery.conf. Les deux seront situés dans /var/lib/pgsql/11/.
Récupération.conf
Spécifiez que ce serveur sera un serveur de secours. S'il est activé, le serveur continuera la récupération en récupérant de nouveaux segments WAL lorsque la fin du WAL archivé sera atteinte.
standby_mode = 'on'Spécifiez une chaîne de connexion à utiliser pour que le serveur de secours se connecte au nœud principal.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Spécifiez la récupération dans une chronologie particulière. La valeur par défaut consiste à restaurer le long de la même chronologie qui était en cours lorsque la sauvegarde de base a été effectuée. Le définir sur "dernier" récupère la dernière chronologie trouvée dans l'archive.
recovery_target_timeline = 'latest'Spécifiez un fichier déclencheur dont la présence met fin à la récupération en veille.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Modifiez ou ajoutez les paramètres suivants dans le fichier de configuration postgresql.conf.
Déterminer la quantité d'informations écrites sur les WAL. Les valeurs possibles sont minimal, replica ou logical. La valeur hot_standby est mappée à la réplique et est utilisée pour conserver la compatibilité avec les versions précédentes. La modification de cette valeur nécessite un redémarrage du service.
wal_level = hot_standbyAutoriser les requêtes pendant la récupération. La modification de cette valeur nécessite un redémarrage du service.
hot_standby = onDémarrage du nœud de veille
Maintenant que vous avez toute la configuration requise en place, il vous suffit de démarrer le service de base de données sur le nœud de secours.
$ systemctl start postgresql-11Et vérifiez les journaux de la base de données dans /var/lib/pgsql/11/data/log/. Vous devriez avoir quelque chose comme ça :
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Vous pouvez également vérifier l'état de la réplication dans le nœud principal en exécutant la requête suivante :
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Comme vous pouvez le voir, nous utilisons une réplication asynchrone.
Conversion de la réplication PostgreSQL asynchrone en réplication synchrone
Maintenant, il est temps de convertir cette réplication asynchrone en une réplication synchronisée, et pour cela, vous devrez configurer à la fois le nœud principal et le nœud de secours.
Nœud principal
Dans le nœud principal PostgreSQL, vous devez utiliser cette configuration de base en plus de la configuration asynchrone précédente.
Postgresql.conf
Spécifiez une liste de serveurs de secours pouvant prendre en charge la réplication synchrone. Ce nom de serveur de secours est le paramètre application_name dans le fichier recovery.conf du serveur de secours.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Spécifie si la validation de la transaction attendra que les enregistrements WAL soient écrits sur le disque avant que la commande ne renvoie une indication de "succès" au client. Les valeurs valides sont on, remote_apply, remote_write, local et off. La valeur par défaut est activée.
synchronous_commit = onConfiguration du nœud de secours
Dans le nœud de secours PostgreSQL, vous devez modifier le fichier recovery.conf en ajoutant la valeur 'application_name dans le paramètre primary_conninfo.
Récupération.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Redémarrez le service de base de données dans les nœuds principal et de secours :
$ service postgresql-11 restartMaintenant, votre réplication de flux de synchronisation devrait être opérationnelle :
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Restauration de la réplication PostgreSQL synchrone à asynchrone
Si vous avez besoin de revenir à la réplication PostgreSQL asynchrone, il vous suffit d'annuler les modifications effectuées dans le fichier postgresql.conf sur le nœud principal :
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onEt redémarrez le service de base de données.
$ service postgresql-11 restartAlors maintenant, vous devriez avoir à nouveau une réplication asynchrone.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Comment déployer une réplication synchrone PostgreSQL à l'aide de ClusterControl
Avec ClusterControl, vous pouvez effectuer les tâches de déploiement, de configuration et de surveillance tout-en-un à partir du même travail et vous pourrez le gérer à partir de la même interface utilisateur.
Nous supposerons que vous avez installé ClusterControl et qu'il peut accéder aux nœuds de la base de données via SSH. Pour plus d'informations sur la configuration de l'accès à ClusterControl, veuillez consulter notre documentation officielle.
Allez dans ClusterControl et utilisez l'option "Déployer" pour créer un nouveau cluster PostgreSQL.
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier l'utilisateur, la clé ou le mot de passe et un port pour se connecter en SSH à nos serveurs. Vous avez également besoin d'un nom pour votre nouveau cluster et si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
Après avoir configuré les informations d'accès SSH, vous devez entrer les données pour accéder votre base de données. Vous pouvez également spécifier le référentiel à utiliser.
À l'étape suivante, vous devez ajouter vos serveurs au cluster qui vous allez créer. Lors de l'ajout de vos serveurs, vous pouvez entrer l'adresse IP ou le nom d'hôte.
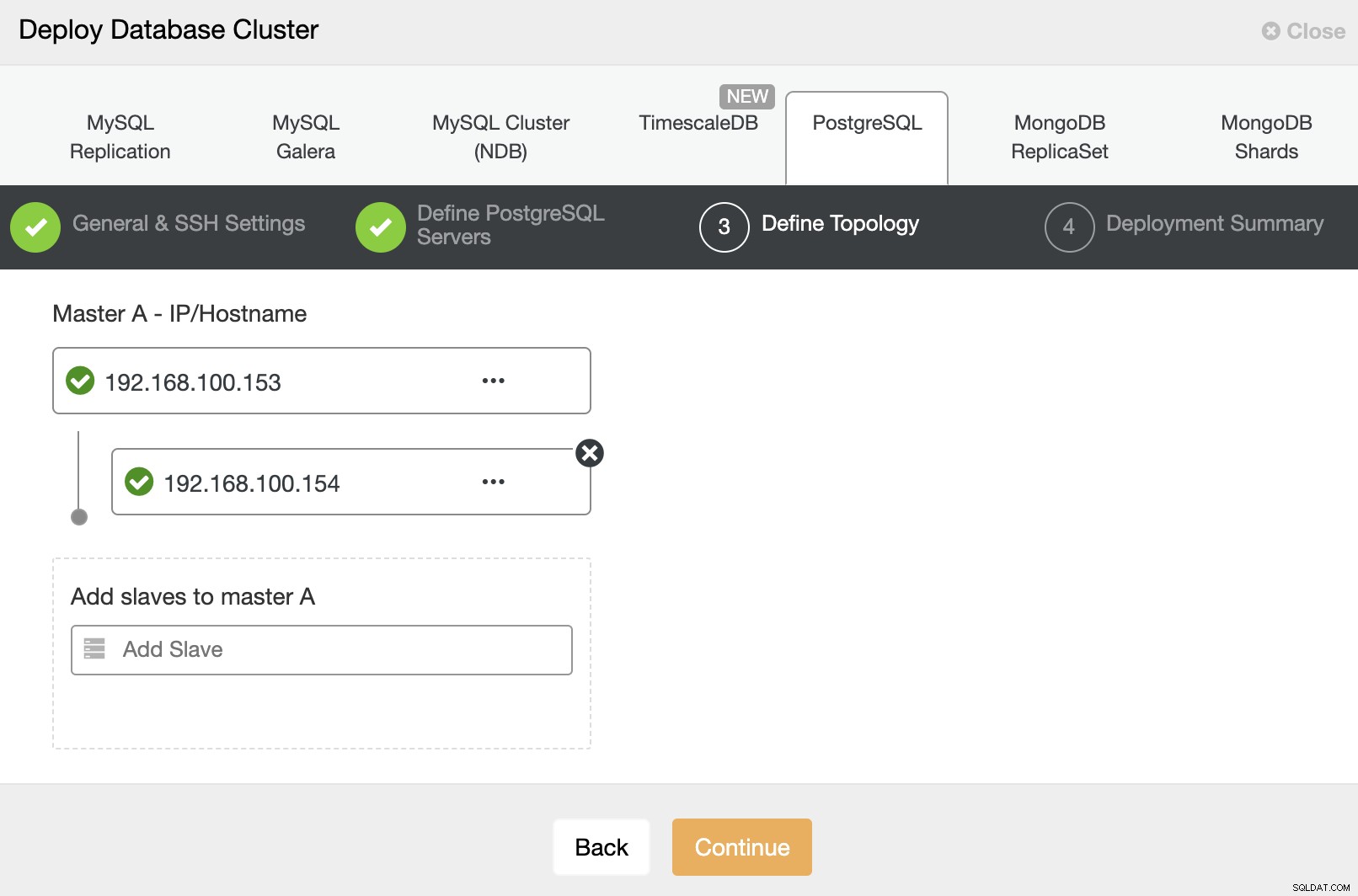
Et enfin, dans la dernière étape, vous pouvez choisir la méthode de réplication, qui peut être une réplication asynchrone ou synchrone.
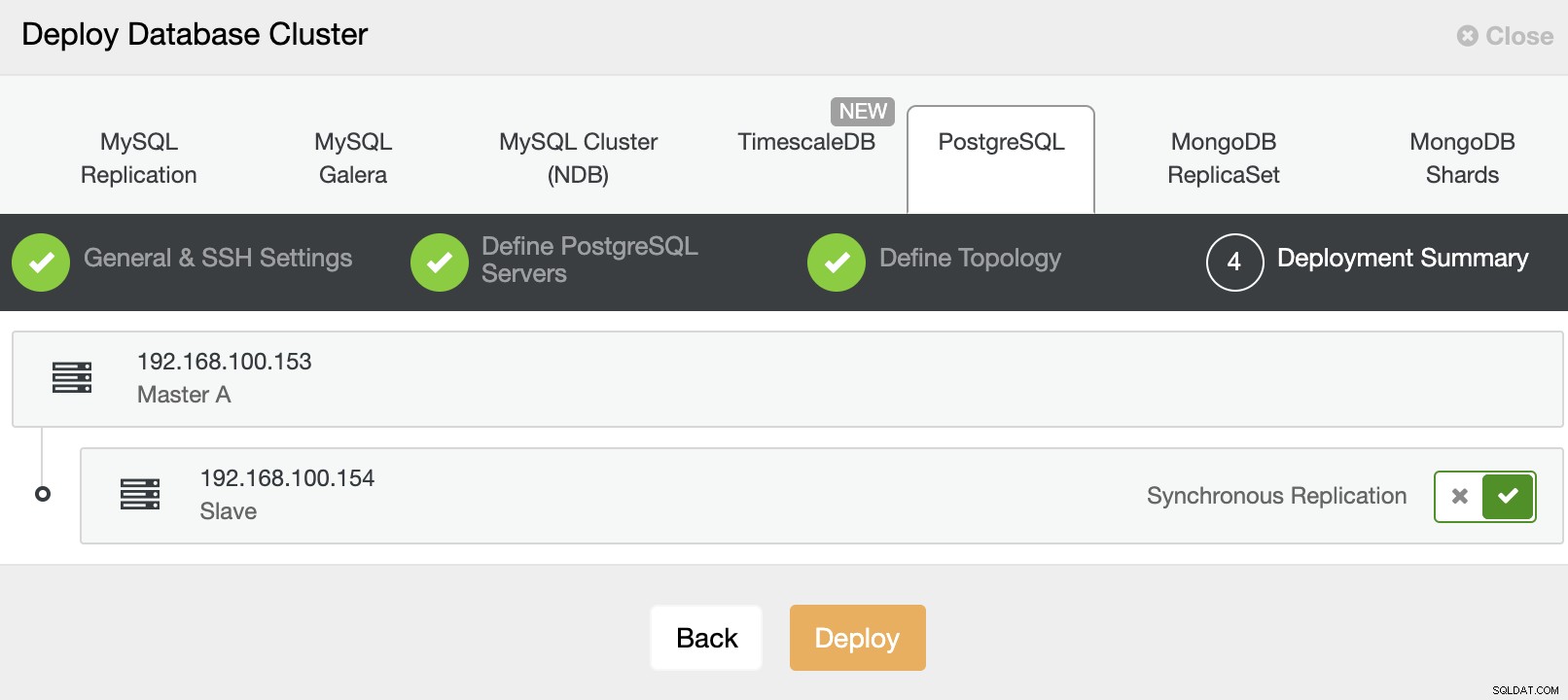
C'est tout. Vous pouvez surveiller l'état du travail dans la section d'activité de ClusterControl.
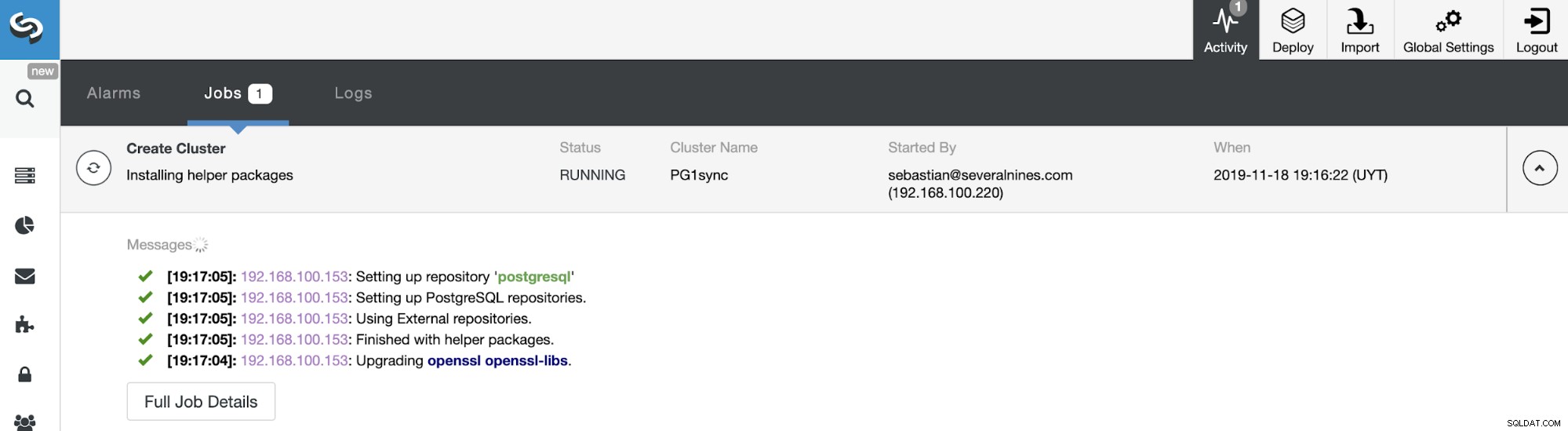
Et lorsque ce travail sera terminé, votre cluster synchrone PostgreSQL sera installé, configuré et surveillé par ClusterControl.
Conclusion
Comme nous l'avons mentionné au début de ce blog, la haute disponibilité est une exigence pour toutes les entreprises, vous devez donc connaître les options disponibles pour y parvenir pour chaque technologie utilisée. Pour PostgreSQL, vous pouvez utiliser la réplication de flux synchrone comme moyen le plus sûr de l'implémenter, mais cette méthode ne fonctionne pas pour tous les environnements et charges de travail.
Attention à la latence générée par l'attente de la confirmation de chaque transaction qui pourrait poser problème au lieu d'une solution Haute Disponibilité.