PostgreSQL est l'une des bases de données open source les plus avancées au monde avec de nombreuses fonctionnalités intéressantes. L'un d'eux est la réplication en continu (réplication physique) qui a été introduite dans PostgreSQL 9.0. Il est basé sur des enregistrements XLOG qui sont transférés vers le serveur de destination et y sont appliqués. Cependant, il est basé sur un cluster et nous ne pouvons pas effectuer une réplication de base de données unique ou d'objet unique (réplication sélective). Au fil des ans, nous avons été dépendants d'outils externes comme Slony, Bucardo, BDR, etc. pour la réplication sélective ou partielle car il n'y avait pas de fonctionnalité au niveau du noyau jusqu'à PostgreSQL 9.6. Cependant, PostgreSQL 10 a proposé une fonctionnalité appelée réplication logique, grâce à laquelle nous pouvons effectuer une réplication au niveau base de données/objet.
La réplication logique réplique les modifications des objets en fonction de leur identité de réplication, qui est généralement une clé primaire. Elle est différente de la réplication physique, dans laquelle la réplication est basée sur des blocs et la réplication octet par octet. La réplication logique n'a pas besoin d'une copie binaire exacte côté serveur de destination, et nous avons la possibilité d'écrire sur le serveur de destination contrairement à la réplication physique. Cette fonctionnalité provient du module pglogical.
Dans cet article de blog, nous allons discuter :
- Comment ça marche – Architecture
- Fonctionnalités
- Cas d'utilisation :lorsque cela est utile
- Limites
- Comment y parvenir
Fonctionnement - Architecture de réplication logique
La réplication logique implémente un concept de publication et d'abonnement (Publication &Subscription). Vous trouverez ci-dessous un schéma architectural de niveau supérieur sur son fonctionnement.
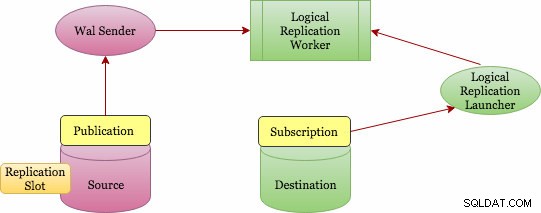
Architecture de réplication logique de base
La publication peut être définie sur le serveur maître et le nœud sur lequel elle est définie est appelé « éditeur ». La publication est un ensemble de modifications d'une seule table ou d'un groupe de tables. C'est au niveau de la base de données et chaque publication existe dans une base de données. Plusieurs tables peuvent être ajoutées à une seule publication et une table peut se trouver dans plusieurs publications. Vous devez ajouter des objets explicitement à une publication sauf si vous choisissez l'option "TOUTES LES TABLES" qui nécessite un privilège de superutilisateur.
Vous pouvez limiter les modifications d'objets (INSERT, UPDATE et DELETE) à répliquer. Par défaut, tous les types d'opérations sont répliqués. Vous devez disposer d'une identité de réplication configurée pour l'objet que vous souhaitez ajouter à une publication. Ceci afin de répliquer les opérations UPDATE et DELETE. L'identité de réplication peut être une clé primaire ou un index unique. Si la table n'a pas de clé primaire ou d'index unique, elle peut être définie sur l'identité de réplique "complète" dans laquelle elle prend toutes les colonnes comme clé (la ligne entière devient la clé).
Vous pouvez créer une publication à l'aide de CREATE PUBLICATION. Certaines commandes pratiques sont couvertes dans la section "Comment y parvenir".
L'abonnement peut être défini sur le serveur de destination et le nœud sur lequel il est défini est appelé « abonné ». La connexion à la base de données source est définie dans l'abonnement. Le nœud d'abonné est le même que toute autre base de données postgres autonome, et vous pouvez également l'utiliser comme publication pour d'autres abonnements.
L'abonnement est ajouté à l'aide de CREATE SUBSCRIPTION et peut être arrêté/repris à tout moment à l'aide de la commande ALTER SUBSCRIPTION et supprimé à l'aide de DROP SUBSCRIPTION.
Une fois qu'un abonnement est créé, la réplication logique copie un instantané des données sur la base de données de l'éditeur. Une fois cela fait, il attend les modifications delta et les envoie au nœud d'abonnement dès qu'elles se produisent.
Cependant, comment les changements sont-ils collectés ? Qui les envoie à la cible ? Et qui les applique à la cible ? La réplication logique est également basée sur la même architecture que la réplication physique. Il est mis en œuvre par les processus « walsender » et « apply ». Comme il est basé sur le décodage WAL, qui démarre le décodage ? Le processus walsender est chargé de démarrer le décodage logique du WAL et charge le plugin de décodage logique standard (pgoutput). Le plugin transforme les modifications lues depuis WAL vers le protocole de réplication logique et filtre les données en fonction de la spécification de publication. Les données sont ensuite transférées en continu à l'aide du protocole de réplication en continu vers le travailleur d'application, qui mappe les données sur des tables locales et applique les modifications individuelles au fur et à mesure de leur réception, dans l'ordre transactionnel correct.
Il enregistre toutes ces étapes dans des fichiers journaux lors de sa configuration. Nous pouvons voir les messages dans la section "Comment y parvenir" plus loin dans le message.
Caractéristiques de la réplication logique
- La réplication logique réplique les objets de données en fonction de leur identité de réplication (généralement un
- clé primaire ou index unique).
- Le serveur de destination peut être utilisé pour les écritures. Vous pouvez avoir différents index et définitions de sécurité.
- La réplication logique prend en charge plusieurs versions. Contrairement à la réplication en continu, la réplication logique peut être définie entre différentes versions de PostgreSQL (> 9.4, cependant)
- La réplication logique effectue un filtrage basé sur les événements
- En comparaison, la réplication logique a moins d'amplification en écriture que la réplication en continu
- Les publications peuvent avoir plusieurs abonnements
- La réplication logique offre une flexibilité de stockage en répliquant des ensembles plus petits (même des tables partitionnées)
- Charge serveur minimale par rapport aux solutions basées sur des déclencheurs
- Permet le streaming parallèle entre les éditeurs
- La réplication logique peut être utilisée pour les migrations et les mises à niveau
- La transformation des données peut être effectuée lors de la configuration.
Cas d'utilisation – Quand la réplication logique est-elle utile ?
Il est très important de savoir quand utiliser la réplication logique. Sinon, vous n'obtiendrez pas beaucoup d'avantages si votre cas d'utilisation ne correspond pas. Voici donc quelques cas d'utilisation pour savoir quand utiliser la réplication logique :
- Si vous souhaitez consolider plusieurs bases de données en une seule à des fins d'analyse.
- Si votre besoin est de répliquer des données entre différentes versions majeures de PostgreSQL.
- Si vous souhaitez envoyer des modifications incrémentielles dans une seule base de données ou un sous-ensemble d'une base de données à d'autres bases de données.
- Si vous donnez accès aux données répliquées à différents groupes d'utilisateurs.
- Si vous partagez un sous-ensemble de la base de données entre plusieurs bases de données.
Limites de la réplication logique
La réplication logique a certaines limites sur lesquelles la communauté travaille en permanence pour surmonter :
- Les tableaux doivent avoir le même nom qualifié complet entre la publication et l'abonnement.
- Les tables doivent avoir une clé primaire ou une clé unique
- La réplication mutuelle (bidirectionnelle) n'est pas prise en charge
- Ne réplique pas le schéma/DDL
- Ne réplique pas les séquences
- Ne réplique pas TRUNCATE
- Ne réplique pas les objets volumineux
- Les abonnements peuvent avoir plus de colonnes ou un ordre de colonnes différent, mais les types et les noms de colonne doivent correspondre entre Publication et Abonnement.
- Privilèges de superutilisateur pour ajouter toutes les tables
- Vous ne pouvez pas diffuser sur le même hôte (l'abonnement sera verrouillé).
Comment réaliser une réplication logique
Voici les étapes pour réaliser la réplication logique de base. Nous pourrons discuter de scénarios plus complexes plus tard.
-
Initialisez deux instances différentes pour la publication et l'abonnement et démarrez.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Paramètres à modifier avant de démarrer les instances (pour les instances de publication et de souscription).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedD'autres paramètres peuvent être par défaut pour la configuration de base.
-
Modifiez le fichier pg_hba.conf pour autoriser la réplication. Notez que ces valeurs dépendent de votre environnement, cependant, il ne s'agit que d'un exemple de base (pour les instances de publication et d'abonnement).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Créez quelques tables de test pour répliquer et insérer des données sur l'instance de publication.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Créez la structure des tables sur l'instance d'abonnement car la réplication logique ne réplique pas la structure.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Créer une publication sur l'instance de publication (port 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Créez un abonnement sur l'instance d'abonnement (port 5556) à la publication créée à l'étape 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msÀ partir du journal :
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedComme vous pouvez le voir dans le message NOTICE, il a créé un emplacement de réplication qui garantit que le nettoyage WAL ne doit pas être effectué tant que l'instantané initial ou les modifications delta ne sont pas transférés vers la base de données cible. Ensuite, l'expéditeur WAL a commencé à décoder les modifications et l'application de la réplication logique a fonctionné lorsque pub et sub sont démarrés. Ensuite, il démarre la synchronisation de la table.
-
Vérifiez les données sur l'instance d'abonnement.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Comme vous le voyez, les données ont été répliquées via l'instantané initial.
-
Vérifiez les modifications delta.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Voici les étapes d'une configuration de base de la réplication logique.