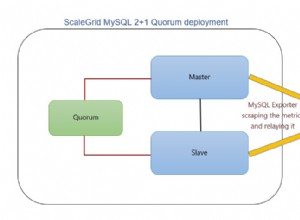
1ère RÈGLE : Vous ne mettez pas à niveau PostgreSQL avec la réplication basée sur les déclencheurs
2ème RÈGLE : Vous NE mettez PAS à niveau PostgreSQL avec la réplication basée sur les déclencheurs
3ème RÈGLE : Si vous mettez à niveau PostgreSQL avec une réplication basée sur des déclencheurs, préparez-vous à en souffrir. Et préparez-vous bien.
Il doit y avoir une raison très sérieuse de ne pas utiliser pg_upgrade pour mettre à jour PostgreSQL.
OK, disons que vous ne pouvez pas vous permettre plus de quelques secondes d'indisponibilité. Utilisez pglogical alors.
OK, disons que vous exécutez 9.3 et que vous ne pouvez donc pas utiliser pglogical. Utilisez Londiste.
Vous ne trouvez pas de fichier README lisible ? Utilisez SLONY.
Trop compliqué? Utilisez la réplication en continu - faites la promotion de l'esclave et exécutez pg_upgrade dessus - puis changez d'application pour qu'elle fonctionne avec le nouveau serveur promu.
Votre application est relativement intensive en écriture tout le temps ? Vous avez examiné toutes les solutions possibles et souhaitez toujours configurer une réplication basée sur un déclencheur personnalisé ? Il y a des choses auxquelles vous devriez faire attention alors :
- Toutes les tables ont besoin de PK. Vous ne devriez pas vous fier à ctid (même avec l'autovacuum désactivé)
- Vous devrez activer le déclencheur pour toutes les tables liées par contrainte (et pourriez avoir besoin d'un FK différé)
- Les séquences nécessitent une synchronisation manuelle
- Les autorisations ne sont pas répliquées (sauf si vous avez également configuré un déclencheur d'événement)
- Les déclencheurs d'événements peuvent aider à automatiser la prise en charge des nouvelles tables, mais il vaut mieux ne pas trop compliquer un processus déjà compliqué. (comme créer un déclencheur et une table étrangère lors de la création de la table, créer également la même table sur un serveur étranger ou modifier la table du serveur distant avec la même modification, vous le faites sur l'ancienne base de données)
- Pour chaque instruction, le déclencheur est moins fiable mais probablement plus simple
- Vous devez imaginer clairement votre processus de migration de données préexistant
- Vous devez prévoir une accessibilité limitée aux tables lors de la configuration et de l'activation de la réplication basée sur des déclencheurs
- Vous devez absolument connaître les dépendances et les contraintes de vos relations avant de suivre cette voie.
Assez d'avertissements ? Vous voulez déjà jouer ? Commençons par un peu de code alors.
Avant d'écrire des déclencheurs, nous devons créer un ensemble de données fictives. Pourquoi? Ne serait-il pas beaucoup plus facile d'avoir un déclencheur avant d'avoir des données ? Ainsi, les données seraient répliquées sur le cluster « de mise à niveau » immédiatement ? Bien sûr que ce serait le cas. Mais alors que voulons-nous mettre à jour ? Créez simplement un ensemble de données sur une version plus récente. Alors oui, si vous prévoyez de passer à une version supérieure et que vous devez ajouter une table, créez des déclencheurs de réplication avant de mettre les données, cela éliminera le besoin de synchroniser les données non répliquées plus tard. Mais de telles nouvelles tables sont, pouvons-nous dire, une partie facile. Alors, imaginons d'abord le cas où nous avons des données avant de décider de mettre à niveau.
Supposons qu'un serveur obsolète s'appelle p93 (le plus ancien pris en charge) et celui sur lequel nous répliquons s'appelle p10 (11 est en route ce trimestre, mais n'est toujours pas arrivé) :
\c PostgreSQL
select pg_terminate_backend(pid) from pg_stat_activity where datname in ('p93','p10');
drop database if exists p93;
drop database if exists p10;Ici, j'utilise psql, je peux donc utiliser la méta-commande \c pour me connecter à une autre base de données. Si vous souhaitez suivre ce code avec un autre client, vous devrez vous reconnecter à la place. Bien sûr, vous n'avez pas besoin de cette étape si vous l'exécutez pour la première fois. J'ai dû recréer mon bac à sable plusieurs fois, j'ai donc enregistré des déclarations…
create database p93; --old db (I use 9.3 as oldest supported ATM version)
create database p10; --new db Nous créons donc deux nouvelles bases de données. Maintenant, je vais me connecter à celui que nous voulons mettre à jour et créer plusieurs types de données funkey et les utiliser pour remplir un tableau que nous considérerons comme préexistant plus tard :
\c p93
create type myenum as enum('a', 'b');--adding some complex types
create type mycomposit as (a int, b text); --and again...
create table t(i serial not null primary key, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit);
insert into t values(0, now(), '{"a":{"aa":[1,3,2]}}', 'foo', 'b', (3,'aloha'));
insert into t (j,e) values ('{"b":null}', 'a');
insert into t (t) select chr(g) from generate_series(100,240) g;--add some more data
delete from t where i > 3 and i < 142; --mockup activity and mix tuples to be not sequential
insert into t (t) select null;Maintenant, qu'avons-nous ?
ctid | i | ts | j | t | e | c
---------+-----+------------------------+----------------------+-----+---+-----------
(0,1) | 0 | 2018-07-08 08:03:00+03 | {"a":{"aa":[1,3,2]}} | foo | b | (3,aloha)
(0,2) | 1 | 2018-07-08 08:03:00+03 | {"b":null} | | a |
(0,3) | 2 | 2018-07-08 08:03:00+03 | | d | |
(0,4) | 3 | 2018-07-08 08:03:00+03 | | e | |
(0,143) | 142 | 2018-07-08 08:03:00+03 | | ð | |
(0,144) | 143 | 2018-07-08 08:03:00+03 | | | |
(6 rows)OK, quelques données - pourquoi ai-je inséré puis supprimé autant de données ? Eh bien, nous essayons de modéliser un ensemble de données qui existait depuis un certain temps. J'essaie donc de le disperser un peu. Déplaçons une ligne de plus (0,3) vers la fin de la page (0,145) :
update t set j = '{}' where i =3; --(0,4)Supposons maintenant que nous allons utiliser PostgreSQL_fdw (utiliser dblink ici serait fondamentalement le même et probablement plus rapide pour 9.3, alors faites-le si vous le souhaitez).
create extension PostgreSQL_fdw;
create server p10 foreign data wrapper PostgreSQL_fdw options (host 'localhost', dbname 'p10'); --I know it's the same 9.3 server - change host to other version and use other cluster if you wish. It's not important for the sandbox...
create user MAPPING FOR vao SERVER p10 options(user 'vao', password 'tsun');Maintenant, nous pouvons utiliser pg_dump -s pour obtenir le DDL, mais je l'ai juste au-dessus. Nous devons créer la même table dans le cluster de version supérieure pour répliquer les données vers :
\c p10
create type myenum as enum('a', 'b');--adding some complex types
create type mycomposit as (a int, b text); --and again...
create table t(i serial not null primary key, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit);Maintenant, nous revenons à 9.3 et utilisons des tables étrangères pour la migration des données (j'utiliserai f_ convention pour les noms de table ici, f signifie étranger):
\c p93
create foreign table f_t(i serial, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit) server p10 options (TABLE_name 't');Pour terminer! Nous créons une fonction d'insertion et un déclencheur.
create or replace function tgf_i() returns trigger as $$
begin
execute format('insert into %I select ($1).*','f_'||TG_RELNAME) using NEW;
return NEW;
end;
$$ language plpgsql;Ici et plus tard, j'utiliserai des liens pour un code plus long. Premièrement, pour que le texte parlé ne sombre pas dans le langage machine. Deuxièmement parce que j'utilise plusieurs versions des mêmes fonctions pour refléter comment le code doit évoluer à la demande.
--OK - first table ready - lets try logical trigger based replication on inserts:
insert into t (t) select 'one';
--and now transactional:
begin;
insert into t (t) select 'two';
select ctid, * from f_t;
select ctid, * from t;
rollback;
select ctid, * from f_t where i > 143;
select ctid, * from t where i > 143;Résultat :
INSERT 0 1
BEGIN
INSERT 0 1
ctid | i | ts | j | t | e | c
-------+-----+------------------------+---+-----+---+---
(0,1) | 144 | 2018-07-08 08:27:15+03 | | one | |
(0,2) | 145 | 2018-07-08 08:27:15+03 | | two | |
(2 rows)
ctid | i | ts | j | t | e | c
---------+-----+------------------------+----------------------+-----+---+-----------
(0,1) | 0 | 2018-07-08 08:27:15+03 | {"a":{"aa":[1,3,2]}} | foo | b | (3,aloha)
(0,2) | 1 | 2018-07-08 08:27:15+03 | {"b":null} | | a |
(0,3) | 2 | 2018-07-08 08:27:15+03 | | d | |
(0,143) | 142 | 2018-07-08 08:27:15+03 | | ð | |
(0,144) | 143 | 2018-07-08 08:27:15+03 | | | |
(0,145) | 3 | 2018-07-08 08:27:15+03 | {} | e | |
(0,146) | 144 | 2018-07-08 08:27:15+03 | | one | |
(0,147) | 145 | 2018-07-08 08:27:15+03 | | two | |
(8 rows)
ROLLBACK
ctid | i | ts | j | t | e | c
-------+-----+------------------------+---+-----+---+---
(0,1) | 144 | 2018-07-08 08:27:15+03 | | one | |
(1 row)
ctid | i | ts | j | t | e | c
---------+-----+------------------------+---+-----+---+---
(0,146) | 144 | 2018-07-08 08:27:15+03 | | one | |
(1 row)Que voyons-nous ici ? Nous voyons que les données nouvellement insérées sont répliquées avec succès dans la base de données p10. Et en conséquence est annulé si la transaction échoue. Jusqu'ici tout va bien. Mais vous ne pouviez pas remarquer (oui, oui - pas non) que le tableau sur p93 est beaucoup plus grand - les anciennes données ne se sont pas répliquées. Comment pouvons-nous l'obtenir là-bas? Bien simple :
insert into … select local.* from ...outer join foreign where foreign.PK is null ferait. Et ce n'est pas la principale préoccupation ici - vous devriez plutôt vous inquiéter de la façon dont vous gérerez les données préexistantes sur les mises à jour et les suppressions - car les instructions exécutées avec succès sur la version inférieure de la base de données échoueront ou affecteront simplement zéro ligne sur la version supérieure - simplement parce qu'il n'y a pas de données préexistantes ! Et nous arrivons ici aux secondes de la phrase de temps d'arrêt. (S'il s'agissait d'un film, bien sûr ici nous aurions un flashback, mais hélas - si la phrase "secondes d'indisponibilité" n'a pas retenu votre attention plus tôt, vous devrez aller chercher la phrase ci-dessus...)
Afin d'activer tous les déclencheurs d'instructions, vous devez geler la table, copier toutes les données, puis activer les déclencheurs, afin que les tables des bases de données des versions inférieures et supérieures soient synchronisées et que toutes les instructions aient la même (ou extrêmement proche, car physique la distribution sera différente, regardez à nouveau ci-dessus le premier exemple pour la colonne ctid) affecte. Mais exécuter une telle « activation de la réplication » sur la table dans une transaction biiiiiiiig ne représentera pas des secondes d'indisponibilité. Potentiellement, cela rendra le site en lecture seule pendant des heures. Surtout si la table est grossièrement collée par FK avec d'autres grosses tables.
Eh bien, la lecture seule n'est pas un temps d'arrêt complet. Mais plus tard, nous essaierons de laisser tous les SELECTS et certains INSERT, DELETE, UPDATE fonctionnels (sur les nouvelles données, échouant sur les anciennes). Le déplacement d'une table ou d'une transaction en lecture seule peut être effectué de plusieurs manières - que ce soit une approche PostgreSQL, ou au niveau de l'application, ou même la révocation temporaire des autorisations en fonction. Ces approches elles-mêmes peuvent être un sujet pour son propre blog, donc je ne ferai que le mentionner.
En tous cas. Retour aux déclencheurs. Pour effectuer la même action, nécessitant de travailler sur une ligne distincte (UPDATE, DELETE) sur une table distante comme vous le faites sur une table locale, nous devons utiliser des clés primaires, car l'emplacement physique sera différent. Et les clés primaires sont créées sur différentes tables avec différentes colonnes, nous devons donc soit créer une fonction unique pour chaque table, soit essayer d'écrire un générique. Supposons (pour plus de simplicité) que nous n'avons qu'une seule colonne PK, alors cette fonction devrait aider. Alors enfin ! Ayons une fonction de mise à jour ici. Et évidemment un déclencheur :
create trigger tgu before update on t for each row execute procedure tgf_u();Et voyons si cela fonctionne :
begin;
update t set j = '{"updated":true}' where i = 144;
select * from t where i = 144;
select * from f_t where i = 144;
Rollback;Résultat :
BEGIN
psql:blog.sql:71: INFO: (144,"2018-07-08 09:09:20+03","{""updated"":true}",one,,)
UPDATE 1
i | ts | j | t | e | c
-----+------------------------+------------------+-----+---+---
144 | 2018-07-08 09:09:20+03 | {"updated":true} | one | |
(1 row)
i | ts | j | t | e | c
-----+------------------------+------------------+-----+---+---
144 | 2018-07-08 09:09:20+03 | {"updated":true} | one | |
(1 row)
ROLLBACKD'ACCORD. Et tant qu'il est encore chaud, ajoutons également la fonction de déclenchement de suppression et la réplication :
create trigger tgd before delete on t for each row execute procedure tgf_d();Et vérifiez :
begin;
delete from t where i = 144;
select * from t where i = 144;
select * from f_t where i = 144;
Rollback;Donner :
DELETE 1
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)Comme nous nous en souvenons (qui pourrait l'oublier !), nous ne transformons pas le support de "réplication" en transaction. Et nous devrions le faire si nous voulons des données cohérentes. Comme indiqué ci-dessus, TOUS les déclencheurs d'instructions sur TOUTES les tables liées à FK doivent être activés dans une transaction, préalablement préparée en synchronisant les données. Sinon, nous pourrions tomber dans :
begin;
select * from t where i = 3;
delete from t where i = 3;
select * from t where i = 3;
select * from f_t where i = 3;
Rollback;Donner :
p93=# begin;
BEGIN
p93=# select * from t where i = 3;
i | ts | j | t | e | c
---+------------------------+----+---+---+---
3 | 2018-07-08 09:16:27+03 | {} | e | |
(1 row)
p93=# delete from t where i = 3;
DELETE 1
p93=# select * from t where i = 3;
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
p93=# select * from f_t where i = 3;
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
p93=# rollback;Yayki ! Nous avons supprimé une ligne sur la version inférieure de la base de données et non sur la plus récente ! Tout simplement parce qu'il n'y était pas. Cela ne se produirait pas si nous le faisions correctement (début ; synchronisation ; activer le déclencheur ; fin ;). Mais la bonne méthode rendrait les tables en lecture seule pendant longtemps ! Le lecteur le plus endurci dirait même "pourquoi feriez-vous alors une réplication basée sur les déclencheurs ?".
Vous pouvez le faire avec pg_upgrade comme le feraient des gens "normaux". Et en cas de réplication en continu, vous pouvez rendre tous les ensembles en lecture seule. Mettez en pause la relecture de xlog et mettez à niveau le maître pendant que l'application est toujours RO l'esclave.
Exactement! N'ai-je pas commencé par ça ?
La réplication basée sur le déclencheur arrive sur scène lorsque vous avez besoin de quelque chose de très spécial. Par exemple, vous pouvez essayer d'autoriser SELECT et certaines modifications sur les données nouvellement créées, pas seulement RO. Disons que vous avez un questionnaire en ligne - l'utilisateur s'inscrit, répond, obtient son bonus-points-gratuits-autre-personne-n'a-besoin-de-super-choses et part. Avec une telle structure, vous pouvez simplement interdire les modifications sur les données qui ne sont pas encore sur la version supérieure, permettant ainsi l'ensemble du flux de données pour les nouveaux utilisateurs.
Ainsi, vous abandonnez quelques travailleurs des guichets automatiques en ligne, laissant les nouveaux arrivants travailler sans même remarquer que vous êtes au milieu d'une mise à niveau. Cela semble horrible, mais n'ai-je pas dit hypothétiquement? Je ne l'ai pas fait ? Eh bien, je le pensais.
Quel que soit le cas réel, voyons comment vous pouvez le mettre en œuvre. Les fonctions de suppression et de mise à jour changeront. Et vérifions le dernier scénario maintenant :
BEGIN
psql:blog.sql:86: ERROR: This data is not replicated yet, thus can't be deleted
psql:blog.sql:87: ERROR: current transaction is aborted, commands ignored until end of transaction block
psql:blog.sql:88: ERROR: current transaction is aborted, commands ignored until end of transaction block
ROLLBACKLa ligne n'a pas été supprimée sur la version inférieure, car elle n'a pas été trouvée sur la version supérieure. La même chose se produirait avec la mise à jour. Essayez-le vous-même. Vous pouvez maintenant démarrer la synchronisation des données sans arrêter beaucoup de modifications sur la table que vous incluez dans la réplication basée sur les déclencheurs.
Est-ce mieux? Pire? C'est différent - il présente de nombreux défauts et certains avantages par rapport au système RO mondial. Mon objectif était de démontrer pourquoi quelqu'un voudrait utiliser une méthode aussi compliquée que la normale - pour obtenir des capacités spécifiques sur un processus stable et bien connu. A un certain prix bien sûr…
Ainsi, maintenant que nous nous sentons un peu plus en sécurité pour la cohérence des données et que nos données préexistantes dans la table t se synchronisent avec p10, nous pouvons parler d'autres tables. Comment tout cela fonctionnerait-il avec FK (après tout, j'ai mentionné FK tant de fois, je dois l'inclure dans l'échantillon). Eh bien, pourquoi attendre ?
create table c (i serial, t int references t(i), x text);
--and accordingly a foreign table - the one on newer version...
\c p10
create table c (i serial, t int references t(i), x text);
\c p93
create foreign table f_c(i serial, t int, x text) server p10 options (TABLE_name 'c');
--let’s pretend it had some data before we decided to migrate with triggers to a higher version
insert into c (t,x) values (1,'FK');
--- so now we add triggers to replicate DML:
create trigger tgi before insert on c for each row execute procedure tgf_i();
create trigger tgu before update on c for each row execute procedure tgf_u();
create trigger tgd before delete on c for each row execute procedure tgf_d();Cela vaut sûrement la peine de regrouper ces trois éléments dans une fonction dans le but de "déclencher" de nombreuses tables. Mais je ne le ferai pas. Comme je ne vais pas ajouter d'autres tables - deux bases de données de relations référencées sont déjà un tel réseau en désordre !
--now, what would happen if we tr inserting referenced FK, that does not exist on remote db?..
insert into c (t,x) values (2,'FK');
/* it fails with:
psql:blog.sql:139: ERROR: insert or update on table "c" violates foreign key constraint "c_t_fkey"
a new row isn't inserted neither on remote, nor local db, so we have safe data consistencyy, but inserts are blocked?..
Yes untill data that existed untill trigerising gets to remote db - ou cant insert FK with before triggerising keys, yet - a new (both t and c tables) data will be accepted:
*/
insert into t(i) values(4); --I use gap we got by deleting data above, so I dont need to "returning" and know the exact id -less coding in sample script
insert into c(t) values(4);
select * from c;
select * from f_c;Résultat :
psql:blog.sql:109: ERROR: insert or update on table "c" violates foreign key constraint "c_t_fkey"
DETAIL: Key (t)=(2) is not present in table "t".
CONTEXT: Remote SQL command: INSERT INTO public.c(i, t, x) VALUES ($1, $2, $3)
SQL statement "insert into f_c select ($1).*"
PL/pgSQL function tgf_i() line 3 at EXECUTE statement
INSERT 0 1
INSERT 0 1
i | t | x
---+---+----
1 | 1 | FK
3 | 4 |
(2 rows)
i | t | x
---+---+---
3 | 4 |
(1 row)De nouveau. Il semble que la cohérence des données soit en place. Vous pouvez également commencer à synchroniser les données pour la nouvelle table c…
Fatigué? Je le suis définitivement.
Conclusion
En conclusion, je voudrais souligner certaines erreurs que j'ai commises en examinant cette approche. Pendant que je construisais l'instruction de mise à jour, répertoriant dynamiquement toutes les colonnes de pg_attribute, j'ai perdu une bonne heure. Imaginez à quel point j'ai été déçu de découvrir plus tard que j'avais complètement oublié la construction UPDATE (list) =(list) ! Et la fonction est arrivée à un état beaucoup plus court et plus lisible.
Donc, l'erreur numéro un était d'essayer de tout construire vous-même, simplement parce que cela semble si accessible. C'est toujours le cas, mais comme toujours, quelqu'un a probablement déjà fait mieux - passer deux minutes juste pour vérifier si c'est le cas peut vous faire économiser une heure de réflexion plus tard.
Et deuxièmement, la chose m'a semblé beaucoup plus simple là où elle s'est avérée beaucoup plus profonde, et j'ai trop compliqué de nombreux cas qui sont parfaitement gérés par le modèle de transaction PostgreSQL.
Donc, ce n'est qu'après avoir essayé de construire le bac à sable que j'ai eu une compréhension assez claire des estimations de cette approche.
La planification est donc évidemment nécessaire, mais ne planifiez pas plus que ce que vous pouvez réellement faire.
L'expérience vient avec la pratique.
Mon bac à sable m'a rappelé une stratégie informatique - vous vous asseyez dessus après le déjeuner et pensez - "ah, ici je construis Pyramyd, là je fais du tir à l'arc, puis je me convertis en Sons of Ra et construis 20 hommes à arc long, et ici j'attaque le pathétique voisins. Deux heures de gloire. Et SOUDAIN vous vous retrouvez le lendemain matin, deux heures avant le travail avec « Comment suis-je arrivé ici ? Pourquoi dois-je signer cette alliance humiliante avec des barbares pas lavés pour sauver mon dernier arc long et ai-je vraiment besoin de vendre ma pyramide si durement construite pour cela ?"
Lectures :
- https://www.PostgreSQL.org/docs/current/static/different-replication-solutions.html
- https://stackoverflow.com/questions/15343075/update-multiple-columns-in-a-trigger-function-in-plpgsql