Nous voilà. Près de deux décennies dans le 21e siècle et le besoin de plus de puissance de calcul est toujours un problème. Les entreprises technologiques battent le pavé pour s'attaquer de front à cet énorme problème. Les ingénieurs en matériel ont trouvé une solution en modifiant la façon dont ils conçoivent et fabriquent l'unité centrale de traitement (CPU) d'un ordinateur. Ils contiennent désormais plusieurs cœurs, ce qui permet la simultanéité. À leur tour, les développeurs de logiciels ont ajusté leur façon d'écrire des programmes pour s'adapter à ce changement de matériel.
La communauté PostgreSQL a pleinement tiré parti de ces processeurs multicœurs pour améliorer les performances des requêtes. En mettant simplement à jour vers les versions 9.6 ou supérieures, vous pouvez utiliser une fonctionnalité appelée parallélisme des requêtes pour effectuer diverses opérations. Il décompose les tâches en parties plus petites et répartit chaque tâche sur plusieurs cœurs de processeur. Chaque cœur peut traiter les tâches en même temps. En raison des limitations matérielles, c'est le seul moyen d'améliorer les performances de l'ordinateur à l'avenir.
Avant d'utiliser la fonctionnalité de parallélisme dans la base de données PostgreSQL, il est essentiel de reconnaître comment elle rend une requête parallèle. Vous pourrez déboguer et résoudre tous les problèmes qui surviennent.
Comment fonctionne le parallélisme des requêtes ?
Pour mieux comprendre comment le parallélisme est exécuté, c'est une bonne idée de commencer au niveau du client. Pour accéder à PostgreSQL, un client doit envoyer une demande de connexion au serveur de base de données appelé le postmaster. Le postmaster terminera l'authentification, puis créera un nouveau processus serveur pour chaque connexion. Il est également responsable de la création d'une zone de mémoire partagée qui contient un pool de mémoire tampon. Le pool de mémoire tampon supervise le transfert de données entre la mémoire partagée et le stockage. Par conséquent, dès qu'une connexion est établie, le pool de mémoire tampon transfère les données et permet le parallélisme des requêtes.
Il n'est pas nécessaire que toutes les requêtes soient parallèles. Il existe des cas où seule une petite quantité de données est nécessaire et qui peuvent être traitées rapidement par un seul cœur. Cette fonctionnalité n'est utilisée que lorsqu'une requête prend beaucoup de temps à se terminer. L'optimiseur de base de données détermine si le parallélisme doit être exécuté. Si nécessaire, la base de données utilisera une portion supplémentaire de mémoire appelée mémoire partagée dynamique (DSM). Cela permet au processus leader et aux processus de travail conscients parallèles de diviser la requête entre plusieurs cœurs et de collecter des données pertinentes.
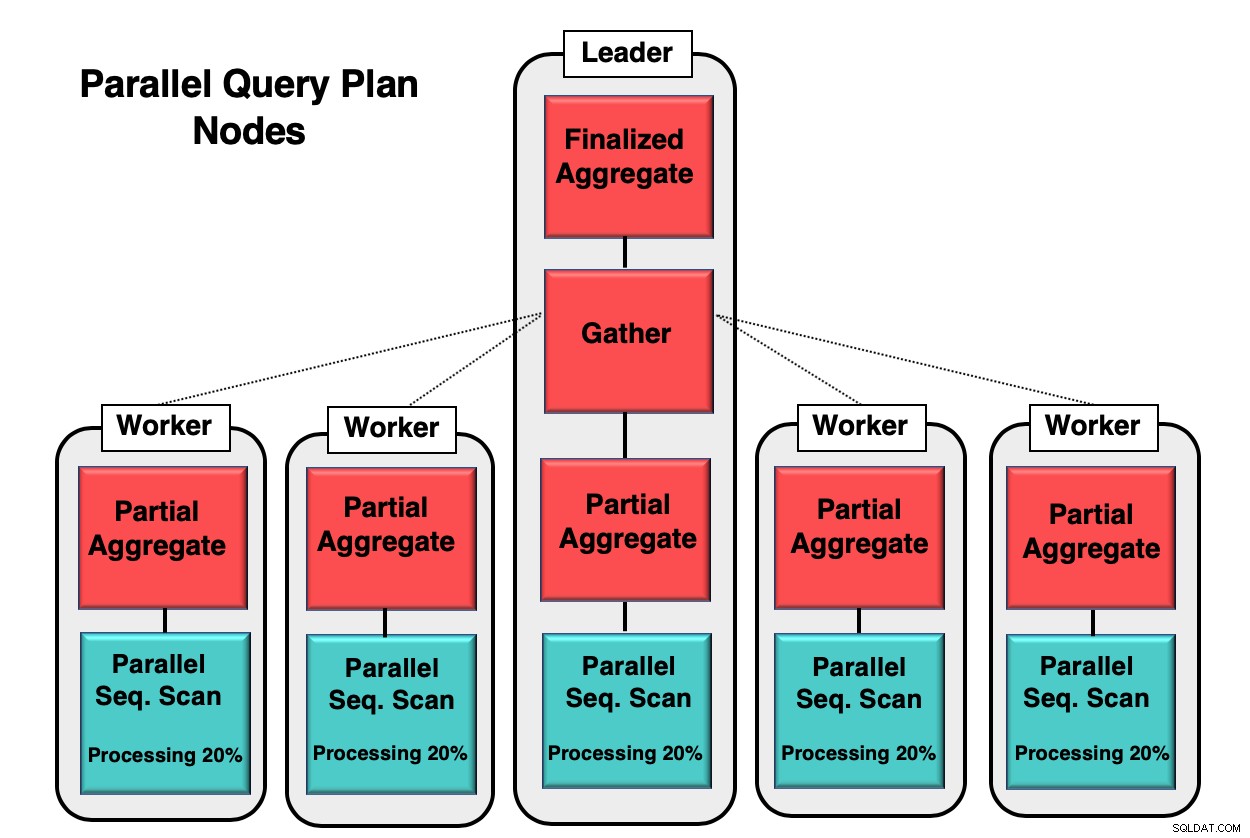
La figure 1 vous donne un exemple de la façon dont le parallélisme a lieu à l'intérieur de la base de données. Le processus leader exécute la requête initiale, tandis que les processus de travail individuels lancent une copie du même processus. Le nœud d'agrégat partiel, ou cœur du processeur, est responsable de la mise en œuvre de l'analyse séquentielle parallèle de la table de la base de données.
Dans ce cas, chaque nœud de balayage séquentiel traite 20 % des données dans des blocs de 8 ko. Ces mêmes nœuds peuvent coordonner leur activité en utilisant une technique appelée parallèle consciente. Chaque nœud a une connaissance complète des données qui ont déjà été traitées et des données qui doivent être analysées dans la table pour terminer la requête. Une fois que les tuples sont collectés dans leur intégralité, ils sont envoyés au nœud de collecte pour être compilés et finalisés.
Opérations parallèles
Différents types de requêtes peuvent être utilisés pour extraire des données d'une base de données afin de produire des ensembles de résultats. Voici des opérations spécifiques qui vous permettent d'exploiter efficacement l'utilisation de plusieurs cœurs.
Analyse séquentielle
Cette opération lit les données d'une table du début à la fin pour recueillir des données. Il répartit uniformément la charge de travail entre plusieurs cœurs pour augmenter la vitesse de traitement des requêtes. Il est conscient de l'activité de chaque cœur, ce qui permet de déterminer plus facilement si l'intégralité de la requête a été effectuée. Le nœud de collecte reçoit ensuite les données extraites en fonction de la requête.
Agrégation
Une opération standard, qui prend une grande quantité de données et la condense en un plus petit nombre de lignes. Cela se produit lors du traitement parallèle en extrayant uniquement d'une table ou d'index, les informations appropriées en fonction de la requête. Effectuer une moyenne de données spécifiques est un excellent exemple d'agrégation.
Hash Join
Technique utilisée pour joindre les données entre deux tables. C'est l'algorithme de jointure le plus rapide, qui est généralement exécuté avec une petite table et une grande. Vous créez d'abord une table de hachage et y chargez toutes les données d'une table. Ensuite, vous pouvez analyser toutes les données du hachage et de la deuxième table, en utilisant une analyse séquentielle parallèle. Chaque tuple extrait de l'analyse est comparé à la table de hachage pour voir s'il y a une correspondance. Si une correspondance est identifiée, les données sont jointes. Avec la sortie de PostgreSQL 11, l'utilisation du parallélisme pour effectuer une jointure par hachage prend environ un tiers de son temps de traitement précédent.
Fusionner la jointure
Si l'optimiseur détermine qu'une jointure par hachage va dépasser la capacité de la mémoire, il effectuera une jointure par fusion à la place. Le processus consiste à parcourir deux listes triées en même temps et à réunir les mêmes éléments. Si les éléments ne sont pas égaux, les données ne seront pas jointes.
Joindre une boucle imbriquée
Cette opération est utilisée lorsque vous deviez joindre deux tables contenant différents langages de programmation, tels que Quick Basic, Python, etc. Chaque table est analysée et traitée à l'aide de plusieurs cœurs. Si les données correspondent, elles sont envoyées au nœud de collecte pour être jointes. Les index sont également scannés, c'est pourquoi ce processus contient plusieurs boucles pour récupérer les données. En moyenne, il ne faudra qu'un tiers du temps pour terminer la jointure en utilisant le processus parallèle.
Analyse de l'index B-tree
Cette opération parcourt une arborescence de données triées pour localiser des informations spécifiques. Ce processus prend plus de temps que l'analyse séquentielle typique car il y a beaucoup d'attente lors de la recherche d'enregistrements. Cependant, le travail de recherche des données appropriées est réparti entre plusieurs processeurs.
Analyse du tas bitmap
Vous pouvez fusionner plusieurs index en utilisant cette opération. Vous voulez d'abord créer le nombre équivalent de bitmaps, car vous avez des index. Par exemple, si vous avez trois index, vous devez d'abord créer trois bitmaps. Chaque bitmap récupère et compile les tuples en fonction de la requête.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancParallélisme des partitions
Il existe une autre forme de parallélisme qui peut avoir lieu dans la base de données PostgreSQL. Cependant, cela ne vient pas de la numérisation des tables et de la décomposition des tâches. Vous pouvez partitionner ou diviser les données par des valeurs spécifiques. Par exemple, vous pouvez prendre les acheteurs de valeur et avoir un seul noyau traitant les données uniquement dans cette valeur. De cette façon, vous savez précisément ce que chaque cœur traite à un moment donné.
Partitionnement par hachage
Cette opération est utilisée en répartissant les lignes du tableau dans des sous-tables. Encore une fois, la division est généralement déterminée par une valeur distincte ou une liste de valeurs d'une table. C'est une excellente méthode à utiliser si vous ne disposez pas d'une technique de gestion de stockage efficace sur tous vos appareils. Vous voudriez utiliser le partitionnement pour distribuer aléatoirement les données afin d'éviter les goulots d'étranglement d'E/S.
Joindre par partition
Une technique utilisée pour décomposer les tables par partitions et les joindre en faisant correspondre des partitions similaires. Par exemple, vous pouvez avoir une grande table d'acheteurs de tous les États-Unis. Vous pouvez d'abord décomposer le tableau en différentes villes, puis regrouper certaines villes en fonction de la région de chaque État. La jointure par partition simplifie vos données et permet la manipulation des tables.
Parallèle non sécurisé
PostgreSQL 11 exécute automatiquement le parallélisme des requêtes si l'optimiseur détermine que c'est le moyen le plus rapide de terminer la requête. Plus la version de PostgreSQL que vous utilisez est élevée, plus votre base de données aura de capacité parallèle. Malheureusement, toutes les requêtes ne doivent pas être exécutées de manière parallèle, même si cela en est possible. Le type de requête que vous effectuez peut avoir des limites spécifiques et nécessitera qu'un seul cœur effectue tout le traitement. Cela ralentira les performances de votre système, mais cela garantira que les données reçues sont complètes.
Pour s'assurer que vos requêtes ne soient jamais mises en danger, les développeurs ont créé une fonction appelée parallel unsafe. Vous pouvez remplacer manuellement l'optimiseur de base de données et demander que la requête ne soit jamais parallèle. Le processus de parallélisme ne sera pas exécuté.
Le parallélisme au sein de la base de données PostgreSQL est une fonctionnalité qui ne fait que s'améliorer avec chaque version de la base de données. Même si l'avenir de la technologie est incertain, il semble que l'utilisation de cette fonctionnalité soit là pour rester.
Pour plus d'informations, vous pouvez consulter ce qui suit...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-"divide-and-conquer-joins-between-partitioned-table