PostgreSQL 11 est sorti le 10 octobre 2018 et dans les délais, marquant le 23e anniversaire de la base de données open source de plus en plus populaire.
Bien qu'une liste complète des modifications soit disponible dans les notes de version habituelles, il vaut la peine de consulter la page remaniée de la matrice des fonctionnalités qui, tout comme la documentation officielle, a fait peau neuve depuis sa première version, ce qui facilite la détection des modifications avant de plonger dans les détails. .
Par exemple, sur la page des notes de version, la "liaison de canal pour l'authentification SCAM" est enterrée sous le code source tandis que la matrice l'a sous la section Sécurité. Pour les curieux voici une capture d'écran de l'interface :
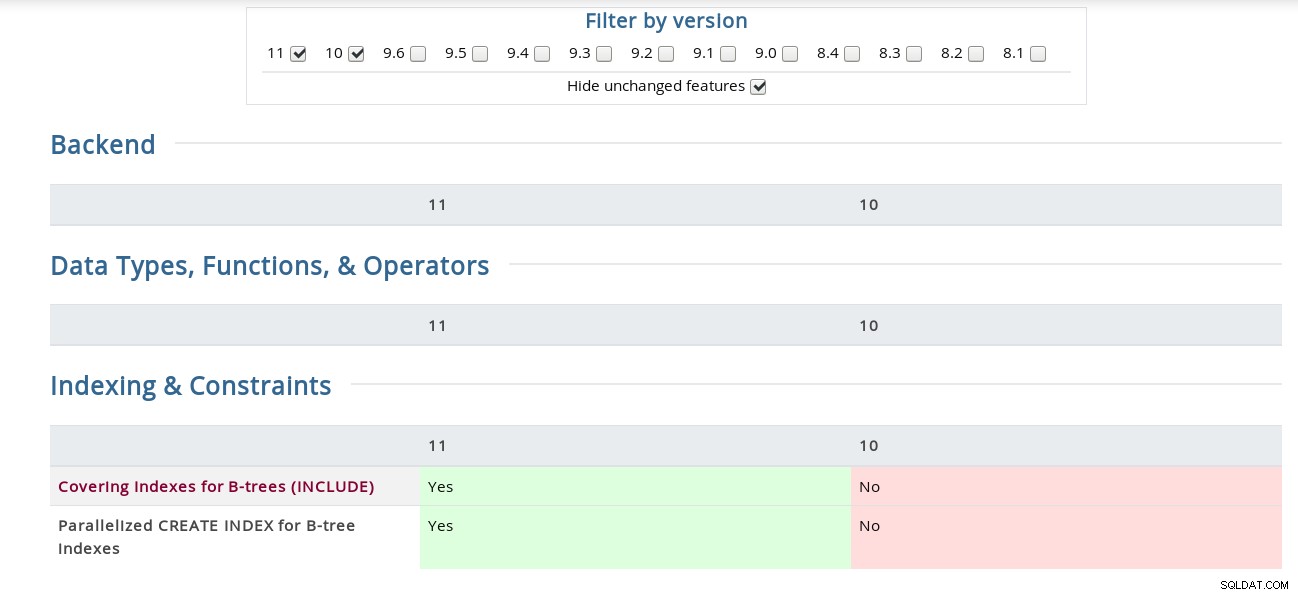 Matrice des fonctionnalités PostgreSQL
Matrice des fonctionnalités PostgreSQL De plus, la page des notes de publication de Bucardo Postgres liée ci-dessus est pratique à sa manière, ce qui facilite la recherche d'un mot-clé dans toutes les versions.
Quoi de neuf? Avec littéralement des centaines de modifications, je passerai en revue les différences répertoriées dans la matrice des fonctionnalités.
Couvrir les index pour les arbres B (INCLUDE)
CREATE INDEX a reçu la clause INCLUDE qui permet aux index d'inclure des colonnes non clés . Son cas d'utilisation pour des requêtes identiques fréquentes est bien décrit dans le commit de Tom Lane du 22 novembre, qui met à jour la documentation de développement (ce qui signifie que la documentation actuelle de PostgreSQL 11 ne l'a pas encore), donc pour le texte complet, reportez-vous à la section 11.9. Analyses d'index uniquement et index de couverture dans la version de développement.
CREATE INDEX parallélisé pour les index B-tree
Comme son nom l'indique, cette fonctionnalité n'est implémentée que pour les index B-tree, et d'après le journal de validation de Robert Haas, nous apprenons que l'implémentation pourrait être affinée à l'avenir. Comme indiqué dans la documentation CREATE INDEX, bien que les méthodes de création d'index parallèles et simultanées tirent parti de plusieurs processeurs, dans le cas de CONCURRENT, seule la première analyse de table sera effectuée en parallèle.
Les paramètres de configuration maintenance_work_mem sont liés à cette nouvelle fonctionnalité. et maintenance_parallel_maintenance_workers .
Enfin, le nombre de travailleurs parallèles peut être défini par table à l'aide de la commande ALTER TABLE et en spécifiant une valeur pour parallel_workers .
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancCompilation juste-à-temps (JIT) pour l'évaluation d'expressions et la déformation de tuples
Avec son propre chapitre JIT dans la documentation, cette nouvelle fonctionnalité repose sur la compilation de PostgreSQL avec le support LLVM (utilisez pg_config pour vérifier).
Le sujet de JIT dans PostgreSQL est suffisamment complexe (voir la référence JIT README dans la documentation) pour nécessiter un blog dédié, en attendant, le blog CitusData sur JIT est une très bonne lecture pour ceux qui souhaitent approfondir le sujet.
Jointures par hachage parallélisées
Cette amélioration des performances des requêtes parallèles est le résultat de l'ajout d'une table de hachage partagée, qui, comme l'explique Thomas Munro dans son blog Parallel Hash for PostgreSQL, évite de partitionner la table de hachage à condition qu'elle tienne dans work_mem , qui jusqu'à présent pour PostgreSQL semble être une meilleure solution que l'algorithme de partition en premier. Le même blog décrit les obstacles de l'architecture PostgreSQL que l'auteur a dû surmonter dans sa quête pour ajouter une parallélisation aux jointures de hachage, ce qui témoigne de la complexité du travail nécessaire pour implémenter cette fonctionnalité.
Partition par défaut
Il s'agit d'une partition attrape-tout pour stocker les lignes qui ne correspondent à aucune autre partition définie. Dans les cas où une nouvelle partition est ajoutée, une contrainte CHECK est recommandée afin d'éviter un scan de la partition par défaut qui peut être lent lorsque la partition par défaut contient un grand nombre de lignes.
Le comportement de partition par défaut est expliqué dans la documentation de ALTER TABLE et CREATE TABLE.
Partitionnement par une clé de hachage
Également appelée partitionnement de hachage, et comme indiqué dans le message de validation, la fonctionnalité permet de partitionner les tables de telle manière que les partitions contiendront un nombre similaire de lignes. Ceci est réalisé en fournissant un module, qui dans le scénario le plus simple est recommandé d'être égal au nombre de partitions, et le reste doit être différent pour chaque partition.
Pour plus de détails et un exemple, consultez la page de documentation CREATE TABLE.
Prise en charge de la CLÉ PRIMAIRE, de la CLÉ ÉTRANGÈRE, des index et des déclencheurs sur les tables partitionnées
Le partitionnement de table est déjà un grand pas en avant dans l'amélioration des performances des grandes tables, et l'ajout de ces fonctionnalités résout les limitations des tables partitionnées depuis PostgreSQL 10, lorsque le "partitionnement déclaratif" de style moderne a été introduit.
Le travail d'Alvaro Herrera est en cours pour permettre aux clés étrangères de référencer les clés primaires, et est prévu pour la prochaine version majeure 12 de PostgreSQL.
MISE À JOUR sur une clé de partition
Comme expliqué dans le journal de validation du correctif, cette mise à jour empêche PostgreSQL de générer une erreur lorsqu'une mise à jour de la clé de partition invalide une ligne, et à la place la ligne sera déplacée vers une partition appropriée.
Lien de canal pour l'authentification SCRAM
Il s'agit d'une mesure de sécurité visant à empêcher les attaques de l'homme du milieu dans l'authentification SASL et est détaillée en détail dans le blog de l'auteur. La fonctionnalité nécessite au minimum OpenSSL 1.0.2.
CREATE PROCEDURE et CALL Syntaxe pour les procédures stockées SQL
PostgreSQL a CREATE FUNCTION depuis 1996, avec la version 1.0.1 , cependant, les fonctions ne peuvent pas gérer les transactions. Comme mentionné dans la documentation, la commande CREATE PROCEDURE n'est pas totalement compatible avec le standard SQL.
Remarque :Restez à l'écoute pour un prochain blog qui plonge en profondeur dans cette fonctionnalité
Conclusion
Les mises à jour majeures de PostgreSQL 11 se concentrent sur l'amélioration des performances grâce à l'exécution parallèle, au partitionnement et à la compilation juste-à-temps. Les procédures stockées permettent un contrôle total des transactions et peuvent être écrites dans une variété de langages PL.