En janvier 2015, mon bon ami et collègue MVP de SQL Server, Rob Farley, a écrit sur une nouvelle solution au problème de la recherche de la médiane dans les versions de SQL Server antérieures à 2012. En plus d'être une lecture intéressante en soi, il s'avère être un excellent exemple à utiliser pour démontrer une analyse avancée du plan d'exécution et pour mettre en évidence certains comportements subtils de l'optimiseur de requête et du moteur d'exécution.
Médiane unique
Bien que l'article de Rob cible spécifiquement un calcul de médiane groupée, je vais commencer par appliquer sa méthode à un grand problème de calcul de médiane unique, car il met en évidence plus clairement les problèmes importants. Les exemples de données proviendront à nouveau de l'article original d'Aaron Bertrand :
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); L'application de la technique de Rob Farley à ce problème donne le code suivant :
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Comme d'habitude, j'ai commenté le comptage du nombre de lignes dans le tableau et je l'ai remplacé par une constante pour éviter une source de variance des performances. Le plan d'exécution de la requête importante est le suivant :

Cette requête s'exécute pendant 5 800 ms sur ma machine de test.
Le déversement de tri
La principale cause de ces performances médiocres devrait apparaître clairement en examinant le plan d'exécution ci-dessus :l'avertissement sur l'opérateur de tri indique qu'une allocation de mémoire d'espace de travail insuffisante a provoqué un débordement de niveau 2 (multi-passes) vers tempdb disque :
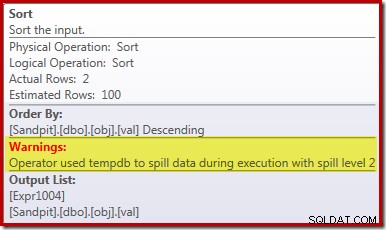
Dans les versions de SQL Server antérieures à 2012, vous devez surveiller séparément les événements de débordement de tri pour voir cela. Quoi qu'il en soit, la réservation de mémoire de tri insuffisante est causée par une erreur d'estimation de cardinalité, comme le montre le plan de pré-exécution (estimé) :

L'estimation de la cardinalité de 100 lignes à l'entrée Sort est une estimation (très imprécise) de l'optimiseur, en raison de l'expression de la variable locale dans l'opérateur Top précédent :

Notez que cette erreur d'estimation de cardinalité n'est pas un problème d'objectif de ligne. L'application de l'indicateur de trace 4138 supprimera l'effet d'objectif de ligne sous le premier Top, mais l'estimation post-Top sera toujours une estimation de 100 lignes (la réservation de mémoire pour le tri sera donc encore beaucoup trop petite) :

Indiquer la valeur de la variable locale
Il existe plusieurs façons de résoudre ce problème d'estimation de cardinalité. Une option consiste à utiliser un indice pour fournir à l'optimiseur des informations sur la valeur contenue dans la variable :
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); L'utilisation de l'indice améliore les performances à 3 250 ms à partir de 5 800 ms. Le plan de post-exécution montre que le tri ne déborde plus :

Il y a cependant quelques inconvénients à cela. Tout d'abord, ce nouveau plan d'exécution nécessite un 388 Mo allocation de mémoire - mémoire qui pourrait autrement être utilisée par le serveur pour mettre en cache des plans, des index et des données :
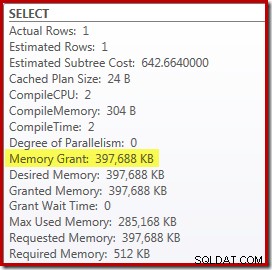
Deuxièmement, il peut être difficile de choisir un bon nombre pour l'indice qui fonctionnera bien pour toutes les exécutions futures, sans réserver inutilement de la mémoire.
Notez également que nous avons dû indiquer une valeur pour la variable qui est supérieure de 10 % à la valeur réelle de la variable pour éliminer complètement le déversement. Ce n'est pas rare, car l'algorithme de tri général est plutôt plus complexe qu'un simple tri sur place. Réserver de la mémoire égale à la taille de l'ensemble à trier ne sera pas toujours (ni même généralement) suffisant pour éviter un débordement à l'exécution.
Intégrer et recompiler
Une autre option consiste à tirer parti de l'optimisation de l'intégration des paramètres activée en ajoutant un indicateur de recompilation au niveau de la requête sur SQL Server 2008 SP1 CU5 ou version ultérieure. Cette action permettra à l'optimiseur de voir la valeur d'exécution de la variable et d'optimiser en conséquence :
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Cela améliore le temps d'exécution à 3150 ms – 100 ms de mieux que d'utiliser OPTIMIZE FOR indice. La raison de cette petite amélioration supplémentaire peut être discernée dans le nouveau plan de post-exécution :

L'expression (2 – @Count % 2) – comme vu précédemment dans le deuxième opérateur Top – peut maintenant être réduit à une seule valeur connue. Une réécriture post-optimisation peut alors combiner le Top avec le Sort, résultant en un seul Top N Sort. Cette réécriture n'était pas possible auparavant car la fusion de Top + Sort en un Top N Sort ne fonctionne qu'avec une valeur littérale constante Top (pas de variables ni de paramètres).
Remplacer le Top and Sort par un Top N Sort a un petit effet bénéfique sur les performances (100 ms ici), mais il élimine également presque entièrement les besoins en mémoire, car un Top N Sort n'a qu'à suivre le N le plus élevé (ou le plus bas) rangées, plutôt que l'ensemble complet. Suite à ce changement d'algorithme, le plan de post-exécution de cette requête indique que le minimum de 1 Mo la mémoire était réservée pour le Top N Sort dans ce plan, et seulement 16 Ko a été utilisé au moment de l'exécution (rappelez-vous, le plan de tri complet nécessitait 388 Mo) :
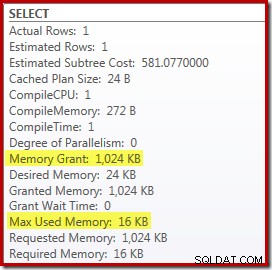
Éviter la recompilation
L'inconvénient (évident) de l'utilisation de l'indicateur de requête de recompilation est qu'il nécessite une compilation complète à chaque exécution. Dans ce cas, la surcharge est assez faible - environ 1 ms de temps CPU et 272 Ko de mémoire. Même ainsi, il existe un moyen de modifier la requête de manière à bénéficier des avantages d'un tri Top N sans utiliser d'indices et sans recompiler.
L'idée vient de la reconnaissance qu'un maximum de deux rangées sera nécessaire pour le calcul final de la médiane. Il peut s'agir d'une ligne ou de deux lors de l'exécution, mais il ne peut jamais y en avoir plus. Cet aperçu signifie que nous pouvons ajouter une étape intermédiaire Top (2) logiquement redondante à la requête comme suit :
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Le nouveau Top (avec le littéral constant le plus important) signifie que le plan d'exécution final comporte l'opérateur Top N Sort souhaité sans recompilation :

Les performances de ce plan d'exécution sont inchangées par rapport à la version recompilée à 3150 ms et la mémoire requise est la même. Notez cependant que l'absence d'incorporation de paramètres signifie que les estimations de cardinalité sous le tri sont des suppositions de 100 lignes (bien que cela n'affecte pas les performances ici).
Le principal point à retenir à ce stade est que si vous voulez un tri Top N à faible mémoire, vous devez utiliser un littéral constant ou permettre à l'optimiseur de voir un littéral via le paramètre d'intégration de l'optimisation.
Le scalaire de calcul
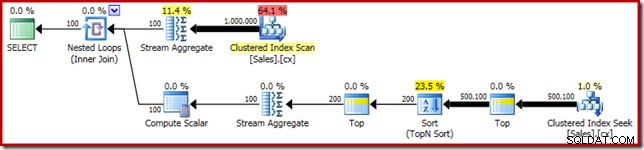
Suppression des 388 Mo l'allocation de mémoire (tout en améliorant les performances de 100 ms) est certainement intéressante, mais il existe un gain de performances beaucoup plus important. La cible improbable de cette dernière amélioration est le Compute Scalar juste au-dessus du Clustered Index Scan.
Ce scalaire de calcul se rapporte à l'expression (0E + f.val) contenu dans le AVG agrégat dans la requête. Au cas où cela vous semble bizarre, il s'agit d'une astuce d'écriture de requête assez courante (comme multiplier par 1,0) pour éviter l'arithmétique entière dans le calcul de la moyenne, mais elle a des effets secondaires très importants.
Il y a une séquence particulière d'événements ici que nous devons suivre étape par étape.
Tout d'abord, notez que 0E est un zéro littéral constant, avec un flottant Type de données. Afin d'ajouter ceci à la colonne d'entiers val, le processeur de requêtes doit convertir la colonne d'entier en flottant (conformément aux règles de priorité des types de données). Un type de conversion similaire serait nécessaire si nous avions choisi de multiplier la colonne par 1,0 (un littéral avec un type de données numérique implicite). Le point important est que cette astuce de routine introduit une expression .
Maintenant, SQL Server essaie généralement de pousser les expressions vers le bas l'arborescence du plan autant que possible lors de la compilation et de l'optimisation. Cela est fait pour plusieurs raisons, notamment pour faciliter la correspondance des expressions avec les colonnes calculées et pour faciliter les simplifications à l'aide des informations de contrainte. Cette stratégie déroulante explique pourquoi le scalaire de calcul apparaît beaucoup plus proche du niveau feuille du plan que ne le suggère la position textuelle d'origine de l'expression dans la requête.
Un risque d'effectuer ce refoulement est que l'expression pourrait finir par être calculée plus de fois que nécessaire. La plupart des plans comportent un nombre de lignes décroissant à mesure que nous progressons dans l'arborescence du plan, en raison de l'effet des jointures, de l'agrégation et des filtres. Pousser les expressions vers le bas de l'arborescence risque donc d'évaluer ces expressions plus de fois (c'est-à-dire sur plus de lignes) que nécessaire.
Pour atténuer cela, SQL Server 2005 a introduit une optimisation dans laquelle les scalaires de calcul peuvent simplement définir une expression, avec le travail de réellement évaluer l'expression différé jusqu'à ce qu'un opérateur ultérieur du plan demande le résultat. Lorsque cette optimisation fonctionne comme prévu, l'effet est d'obtenir tous les avantages de pousser les expressions vers le bas de l'arborescence, tout en n'évaluant l'expression qu'autant de fois que nécessaire.
Ce que signifient tous ces trucs Compute Scalar
Dans notre exemple courant, le 0E + val l'expression était initialement associée à AVG agrégé, nous pouvons donc nous attendre à le voir au (ou légèrement après) le Stream Aggregate. Cependant, cette expression a été poussée vers le bas l'arbre pour devenir un nouveau scalaire de calcul juste après l'analyse, avec l'expression étiquetée comme [Expr1004].
En regardant le plan d'exécution, nous pouvons voir que [Expr1004] est référencé par le Stream Aggregate (extrait de l'onglet Plan Explorer Expressions illustré ci-dessous) :

Toutes choses étant égales par ailleurs, l'évaluation de l'expression [Expr1004] serait différée jusqu'à ce que l'agrégat ait besoin de ces valeurs pour la partie somme du calcul de la moyenne. Étant donné que l'agrégat ne peut rencontrer qu'une ou deux lignes, cela devrait entraîner l'évaluation de [Expr1004] une ou deux fois :
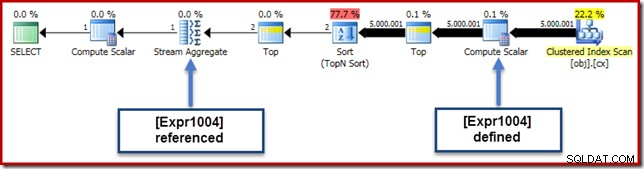
Malheureusement, ce n'est pas tout à fait comme ça que ça marche ici. Le problème est l'opérateur de tri bloquant :
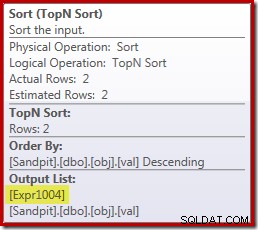
Cela force l'évaluation de [Expr1004], donc au lieu d'être évalué une ou deux fois au Stream Aggregate, le Sort signifie que nous finissons par convertir le val colonne à un flottant et en y ajoutant zéro 5 000 001 fois !
Une solution de contournement
Idéalement, SQL Server serait un peu plus intelligent à propos de tout cela, mais ce n'est pas ainsi que cela fonctionne aujourd'hui. Il n'y a pas d'indication de requête pour empêcher les expressions d'être poussées vers le bas de l'arborescence de plan, et nous ne pouvons pas non plus forcer les scalaires de calcul avec un guide de plan. Il y a inévitablement un indicateur de trace non documenté, mais ce n'est pas celui dont je peux parler de manière responsable dans le contexte actuel.
Donc, pour le meilleur ou pour le pire, cela nous laisse essayer de trouver une réécriture de requête qui empêche SQL Server de séparer l'expression de l'agrégat et de la repousser au-delà du tri, sans modifier le résultat de la requête. Ce n'est pas aussi facile que vous pourriez le penser, mais la modification (certes légèrement étrange) ci-dessous y parvient en utilisant un CASE expression sur une fonction intrinsèque non déterministe :
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Le plan d'exécution pour cette forme finale de la requête est présenté ci-dessous :

Notez qu'un Compute Scalar n'apparaît plus entre le Clustered Index Scan et le Top. Le 0E + val l'expression est maintenant calculée au niveau du Stream Aggregate sur un maximum de deux lignes (au lieu de cinq millions !) et les performances augmentent encore de 32 % de 3 150 ms à 2 150 ms en conséquence.
Cela ne se compare toujours pas très bien avec les performances inférieures à la seconde du OFFSET et des solutions de calcul médian de curseur dynamique, mais cela représente toujours une amélioration très significative par rapport aux 5800 ms d'origine pour cette méthode sur un grand ensemble de problèmes à médiane unique.
L'astuce CASE n'est pas garantie de fonctionner à l'avenir, bien sûr. Le point à retenir ne concerne pas tant l'utilisation d'astuces d'expression de cas étranges, que les implications potentielles en termes de performances des scalaires de calcul. Une fois que vous savez ce genre de chose, vous pourriez réfléchir à deux fois avant de multiplier par 1,0 ou d'ajouter un zéro flottant dans un calcul de moyenne.
Mise à jour : s'il vous plaît voir le premier commentaire pour une belle solution de contournement par Robert Heinig qui ne nécessite aucune supercherie non documentée. Quelque chose à garder à l'esprit la prochaine fois que vous serez tenté de multiplier un entier par un décimal (ou flottant) dans un agrégat moyen.
Médiane groupée
Pour être complet, et pour lier plus étroitement cette analyse à l'article original de Rob, nous terminerons en appliquant les mêmes améliorations à un calcul de médiane groupée. Les tailles d'ensemble plus petites (par groupe) signifient que les effets seront bien sûr plus petits.
Les données de l'échantillon médian groupé (encore une fois telles qu'elles ont été créées à l'origine par Aaron Bertrand) comprennent dix mille lignes pour chacun des cent vendeurs imaginaires :
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); L'application directe de la solution de Rob Farley donne le code suivant, qui s'exécute en 560 ms sur ma machine.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Le plan d'exécution présente des similitudes évidentes avec la médiane unique :
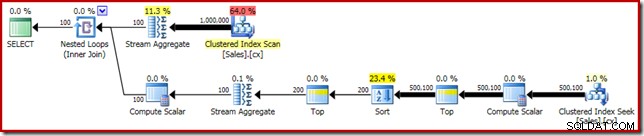
Notre première amélioration consiste à remplacer le Sort par un Top N Sort, en ajoutant un Top (2) explicite. Cela améliore légèrement le temps d'exécution de 560 ms à 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Le plan d'exécution affiche le Top N Tri comme prévu :
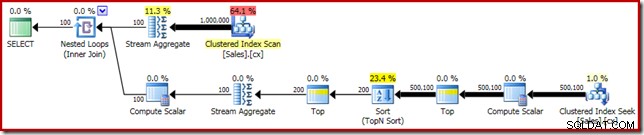
Enfin, nous déployons l'expression CASE étrange pour supprimer l'expression Compute Scalar poussée. Cela améliore encore les performances à 450 ms (une amélioration de 20 % par rapport à l'original) :
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Le plan d'exécution fini est le suivant :