Il n'existe pas de système, de matériel ou de topologie parfaits pour éviter tous les problèmes possibles qui pourraient survenir dans un environnement de production. Relever ces défis nécessite un DRP (plan de reprise après sinistre) efficace, configuré en fonction de votre application, de votre infrastructure et des exigences de votre entreprise. La clé du succès dans ces types de situations est toujours la rapidité avec laquelle nous pouvons résoudre ou résoudre le problème.
Dans ce blog, nous examinerons les scénarios d'échec PostgreSQL les plus courants et vous montrerons comment vous pouvez résoudre ou gérer les problèmes. Nous verrons également comment ClusterControl peut nous aider à nous remettre en ligne
La topologie commune PostgreSQL
Pour comprendre les scénarios d'échec courants, vous devez d'abord commencer par une topologie PostgreSQL courante. Il peut s'agir de n'importe quelle application connectée à un nœud principal PostgreSQL auquel une réplique est connectée.
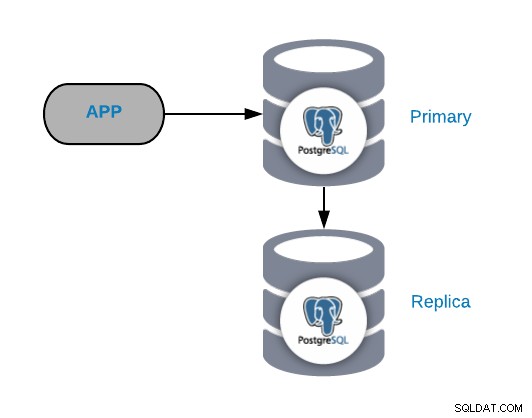
Vous pouvez toujours améliorer ou étendre cette topologie en ajoutant plus de nœuds ou d'équilibreurs de charge , mais c'est la topologie de base avec laquelle nous allons commencer à travailler.
Échec du nœud PostgreSQL principal
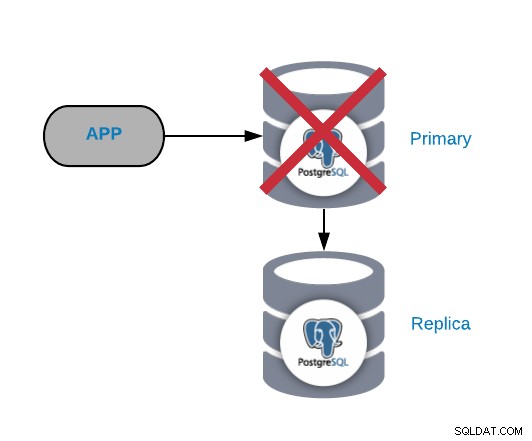
C'est l'un des échecs les plus critiques car nous devrions le réparer dès que possible si nous voulons garder nos systèmes en ligne. Pour ce type de panne, il est important de mettre en place une sorte de mécanisme de basculement automatique. Après l'échec, vous pouvez rechercher la raison des problèmes. Après le processus de basculement, nous nous assurons que le nœud principal défaillant ne pense toujours pas qu'il s'agit du nœud principal. Cela permet d'éviter l'incohérence des données lors de l'écriture.
Les causes les plus courantes de ce type de problème sont une panne du système d'exploitation, une panne matérielle ou une panne de disque. Dans tous les cas, nous devrions vérifier la base de données et les journaux du système d'exploitation pour trouver la raison.
La solution la plus rapide à ce problème consiste à effectuer une tâche de basculement pour réduire les temps d'arrêt. Pour promouvoir une réplique, nous pouvons utiliser la commande pg_ctl promote sur le nœud de base de données esclave, puis nous devons envoyer le trafic depuis application au nouveau nœud principal. Pour cette dernière tâche, nous pouvons implémenter un équilibreur de charge entre notre application et les nœuds de la base de données, afin d'éviter tout changement du côté de l'application en cas de panne. Nous pouvons également configurer l'équilibreur de charge pour détecter la défaillance du nœud et au lieu de lui envoyer du trafic, envoyer le trafic vers le nouveau nœud principal.
Après le processus de basculement et assurez-vous que le système fonctionne à nouveau, nous pouvons examiner le problème, et nous recommandons de toujours garder au moins un nœud esclave en état de marche, donc en cas de nouvelle défaillance primaire, nous pouvons effectuer à nouveau la tâche de basculement.
Échec du nœud de réplication PostgreSQL
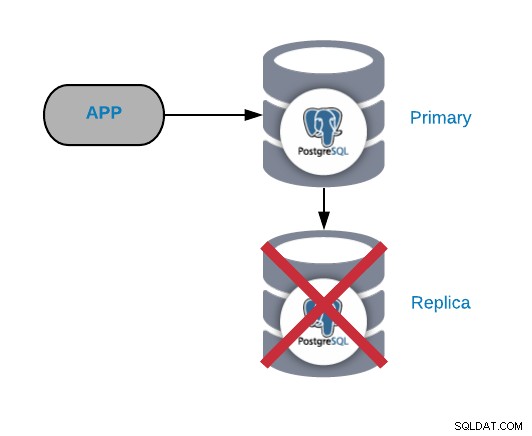
Ce n'est normalement pas un problème critique (tant que vous avez plus de un réplica et ne l'utilisent pas pour envoyer le trafic de production en lecture). Si vous rencontrez des problèmes sur le nœud principal et que votre réplique n'est pas à jour, vous aurez un véritable problème critique. Si vous utilisez notre réplique à des fins de création de rapports ou de mégadonnées, vous souhaiterez probablement la réparer rapidement de toute façon.
Les causes les plus courantes de ce type de problème sont les mêmes que celles que nous avons observées pour le nœud principal, une panne du système d'exploitation, une panne matérielle ou une panne de disque. Vous devez vérifier la base de données et les journaux du système d'exploitation. pour trouver la raison.
Il n'est pas recommandé de laisser le système fonctionner sans aucune réplique car, en cas de panne, vous n'avez pas de moyen rapide de vous remettre en ligne. Si vous n'avez qu'un seul esclave, vous devez résoudre le problème dès que possible ; le moyen le plus rapide étant de créer une nouvelle réplique à partir de zéro. Pour cela, vous devrez effectuer une sauvegarde cohérente et la restaurer sur le nœud esclave, puis configurer la réplication entre ce nœud esclave et le nœud principal.
Si vous souhaitez connaître la raison de l'échec, vous devez utiliser un autre serveur pour créer la nouvelle réplique, puis examiner l'ancienne pour la découvrir. Lorsque vous avez terminé cette tâche, vous pouvez également reconfigurer l'ancien réplica et continuer à fonctionner comme une future option de basculement.
Si vous utilisez le réplica à des fins de création de rapports ou de mégadonnées, vous devez modifier l'adresse IP pour vous connecter à la nouvelle. Comme dans le cas précédent, une façon d'éviter ce changement consiste à utiliser un équilibreur de charge qui connaîtra l'état de chaque serveur, vous permettant d'ajouter/supprimer des répliques à votre guise.
Échec de la réplication PostgreSQL
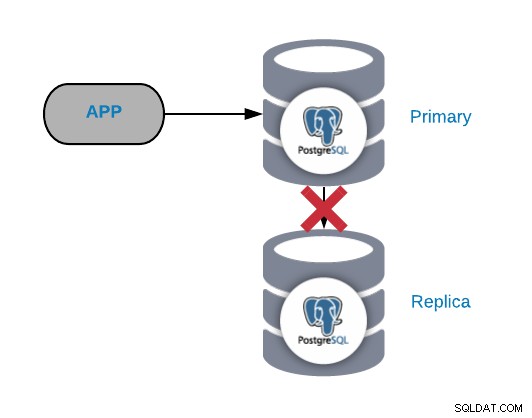
En général, ce type de problème est généré en raison d'un réseau ou d'une configuration publier. C'est lié à une perte de WAL (Write-Ahead Logging) dans le nœud primaire et à la façon dont PostgreSQL gère la réplication.
Si vous avez un trafic important, que vous effectuez des points de contrôle trop fréquemment ou que vous ne stockez WALS que quelques minutes ; si vous avez un problème de réseau, vous aurez peu de temps pour le résoudre. Vos WAL seraient supprimés avant que vous puissiez les envoyer et les appliquer au réplica.
Si le WAL dont la réplique a besoin pour continuer à fonctionner a été supprimé, vous devez le reconstruire, donc pour éviter cette tâche, nous devrions vérifier la configuration de notre base de données pour augmenter les wal_keep_segments (quantités de WALS à conserver dans le pg_xlog) ou les paramètres max_wal_senders (nombre maximum de processus d'envoi WAL exécutés simultanément).
Une autre option recommandée consiste à configurer archive_mode et à envoyer les fichiers WAL vers un autre chemin avec le paramètre archive_command. De cette façon, si PostgreSQL atteint la limite et supprime le fichier WAL, nous l'aurons de toute façon dans un autre chemin.
Corruption des données PostgreSQL / Incohérence des données / Suppression accidentelle

C'est un cauchemar pour tout administrateur de base de données et probablement le problème le plus complexe à résoudre corrigé, en fonction de l'étendue du problème.
Lorsque vos données sont affectées par certains de ces problèmes, le moyen le plus courant de le résoudre (et probablement le seul) consiste à restaurer une sauvegarde. C'est pourquoi les sauvegardes sont la forme de base de tout plan de reprise après sinistre et il est recommandé d'avoir au moins trois sauvegardes stockées dans des emplacements physiques différents. La meilleure pratique dicte que les fichiers de sauvegarde doivent en avoir un stocké localement sur le serveur de base de données (pour une récupération plus rapide), un autre sur un serveur de sauvegarde centralisé et le dernier sur le cloud.
Nous pouvons également créer une combinaison de sauvegardes compatibles PITR complètes/incrémentielles/différentielles pour réduire notre objectif de point de récupération.
Gestion des échecs PostgreSQL avec ClusterControl
Maintenant que nous avons examiné ces scénarios d'échecs PostgreSQL courants, examinons ce qui se passerait si nous gérions vos bases de données PostgreSQL à partir d'un système de gestion de base de données centralisé. Celui qui est excellent pour trouver un moyen rapide et facile de résoudre le problème, dès que possible, en cas d'échec.
ClusterControl fournit une automatisation pour la plupart des tâches PostgreSQL décrites ci-dessus; le tout de manière centralisée et conviviale. Avec ce système, vous pourrez facilement configurer des choses qui, manuellement, prendraient du temps et des efforts. Nous allons maintenant passer en revue certaines de ses principales fonctionnalités liées aux scénarios d'échec de PostgreSQL.
Déployer/Importer un cluster PostgreSQL
Une fois entré dans l'interface ClusterControl, la première chose à faire est de déployer un nouveau cluster ou d'en importer un existant. Pour effectuer un déploiement, sélectionnez simplement l'option Déployer le cluster de bases de données et suivez les instructions qui s'affichent.
Mise à l'échelle de votre cluster PostgreSQL
Si vous accédez à Actions de cluster et sélectionnez Ajouter un esclave de réplication, vous pouvez soit créer un nouveau réplica à partir de zéro, soit ajouter une base de données PostgreSQL existante en tant que réplica. De cette façon, vous pouvez faire fonctionner votre nouvelle réplique en quelques minutes et nous pouvons ajouter autant de répliques que nous le souhaitons. répartir le trafic de lecture entre eux à l'aide d'un équilibreur de charge (que nous pouvons également implémenter avec ClusterControl).
Basculement automatique PostgreSQL
ClusterControl gère le basculement sur votre configuration de réplication. Il détecte les défaillances du maître et promeut un esclave avec les données les plus récentes en tant que nouveau maître. Il bascule également automatiquement le reste des esclaves pour répliquer à partir du nouveau maître. Quant aux connexions client, il exploite deux outils pour la tâche :HAProxy et Keepalived.
HAProxy est un équilibreur de charge qui répartit le trafic d'une origine vers une ou plusieurs destinations et peut définir des règles et/ou des protocoles spécifiques pour la tâche. Si l'une des destinations cesse de répondre, elle est marquée comme étant hors ligne et le trafic est envoyé vers l'une des destinations disponibles. Cela empêche le trafic d'être envoyé vers une destination inaccessible et la perte de ces informations en les dirigeant vers une destination valide.
Keepalived vous permet de configurer une adresse IP virtuelle au sein d'un groupe de serveurs actif/passif. Cette adresse IP virtuelle est attribuée à un serveur « principal » actif. Si ce serveur tombe en panne, l'IP est automatiquement migrée vers le serveur "Secondaire" qui s'est avéré passif, lui permettant de continuer à fonctionner avec la même IP de manière transparente pour nos systèmes.
Ajout d'un équilibreur de charge PostgreSQL
Si vous accédez à Actions de cluster et sélectionnez Ajouter un équilibreur de charge (ou depuis la vue du cluster - accédez à Gérer -> Équilibreur de charge), vous pouvez ajouter des équilibreurs de charge à notre topologie de base de données.
La configuration nécessaire pour créer votre nouvel équilibreur de charge est assez simple. Il vous suffit d'ajouter l'adresse IP/le nom d'hôte, le port, la politique et les nœuds que nous allons utiliser. Vous pouvez ajouter deux équilibreurs de charge avec Keepalived entre eux, ce qui nous permet d'avoir un basculement automatique de notre équilibreur de charge en cas de panne. Keepalived utilise une adresse IP virtuelle et la migre d'un équilibreur de charge à un autre en cas de panne, afin que notre configuration puisse continuer à fonctionner normalement.
Sauvegardes PostgreSQL
Nous avons déjà discuté de l'importance d'avoir des sauvegardes. ClusterControl fournit la fonctionnalité permettant soit de générer une sauvegarde immédiate, soit d'en planifier une.
Vous pouvez choisir entre trois méthodes de sauvegarde différentes :pgdump, pg_basebackup ou pgBackRest. Vous pouvez également spécifier où stocker les sauvegardes (sur le serveur de base de données, sur le serveur ClusterControl ou dans le cloud), le niveau de compression, le chiffrement requis et la période de conservation.
Surveillance et alertes PostgreSQL
Avant de pouvoir agir, vous devez savoir ce qui se passe, vous devrez donc surveiller votre cluster de bases de données. ClusterControl vous permet de surveiller nos serveurs en temps réel. Il existe des graphiques avec des données de base telles que CPU, réseau, disque, RAM, IOPS, ainsi que des métriques spécifiques à la base de données collectées à partir des instances PostgreSQL. Les requêtes de base de données peuvent également être visualisées à partir du moniteur de requêtes.
De la même manière que vous activez la surveillance à partir de ClusterControl, vous pouvez également configurer des alertes qui vous informent des événements dans votre cluster. Ces alertes sont configurables et peuvent être personnalisées selon les besoins.
Conclusion
Tout le monde devra éventuellement faire face aux problèmes et aux échecs de PostgreSQL. Et puisque vous ne pouvez pas éviter le problème, vous devez être en mesure de le résoudre dès que possible et de maintenir le système en marche. Nous avons également vu comment l'utilisation de ClusterControl peut aider à résoudre ces problèmes ; le tout depuis une plateforme unique et conviviale.
Voici ce que nous pensions être certains des scénarios d'échec les plus courants pour PostgreSQL. Nous aimerions connaître vos propres expériences et comment vous l'avez résolu.