La plupart des charges de travail OLTP impliquent une utilisation aléatoire des E/S de disque. Sachant que les disques (y compris les SSD) ont des performances plus lentes que la RAM, les systèmes de base de données utilisent la mise en cache pour augmenter les performances. La mise en cache consiste à stocker des données en mémoire (RAM) pour un accès plus rapide ultérieurement.
PostgreSQL utilise également la mise en cache de ses données dans un espace appelé shared_buffers. Dans ce blog, nous allons explorer cette fonctionnalité pour vous aider à augmenter les performances.
Principes de base de la mise en cache PostgreSQL
Avant d'approfondir le concept de mise en cache, révisons les bases.
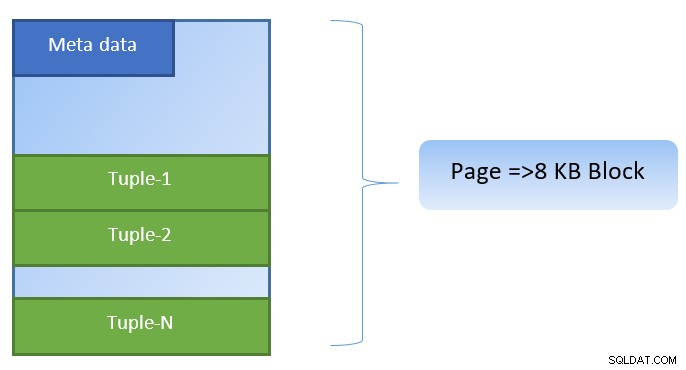
Dans PostgreSQL, les données sont organisées sous la forme de pages de taille 8 Ko, et chacune de ces pages peut contenir plusieurs tuples (selon la taille du tuple). Une représentation simpliste pourrait être comme ci-dessous :
PostgreSQL met en cache les éléments suivants pour accélérer l'accès aux données :
- Données dans des tableaux
- Index
- Plans d'exécution des requêtes
Alors que la mise en cache du plan d'exécution des requêtes se concentre sur la sauvegarde des cycles CPU ; la mise en cache des données de table et des données d'index est axée sur l'économie d'opérations d'E/S de disque coûteuses.
PostgreSQL permet aux utilisateurs de définir la quantité de mémoire qu'ils souhaitent réserver pour conserver ce cache pour les données. Le paramètre pertinent est shared_buffers dans le fichier de configuration postgresql.conf. La valeur finie de shared_buffers définit le nombre de pages pouvant être mises en cache à tout moment.
Lorsqu'une requête est exécutée, PostgreSQL recherche la page sur le disque qui contient le tuple pertinent et la place dans le cache shared_buffers pour un accès latéral. La prochaine fois que le même tuple (ou n'importe quel tuple de la même page) doit être accédé, PostgreSQL peut économiser les E/S disque en le lisant en mémoire.
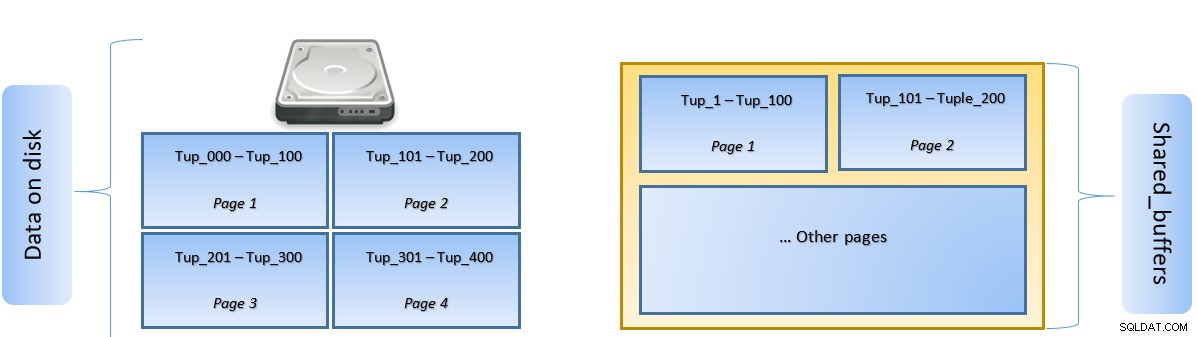
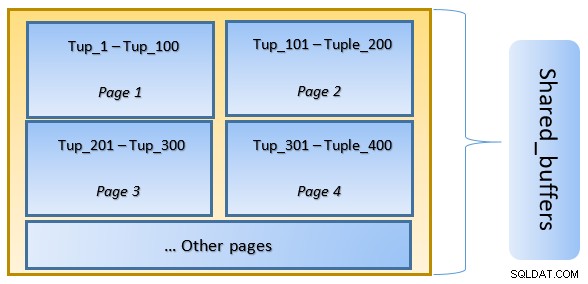
Dans la figure ci-dessus, Page-1 et Page-2 d'un certain table ont été mises en cache. Au cas où une requête utilisateur aurait besoin d'accéder à des tuples entre Tuple-1 et Tuple-200, PostgreSQL peut l'extraire de la RAM elle-même.
Cependant, si la requête doit accéder aux tuples 250 à 350, elle devra effectuer des E/S disque pour les pages 3 et 4. Tout accès ultérieur pour les tuples 201 à 400 sera extrait du cache et les E/S de disque ne seront pas nécessaires, ce qui accélérera la requête.
À un niveau élevé, PostgreSQL suit l'algorithme LRU (le moins récemment utilisé) pour identifier les pages qui doivent être évincées du cache. En d'autres termes, une page qui n'est consultée qu'une seule fois a plus de chances d'être évincée (par rapport à une page consultée plusieurs fois), au cas où une nouvelle page devrait être récupérée par PostgreSQL dans le cache.
La mise en cache PostgreSQL en action
Exécutons un exemple et voyons l'impact du cache sur les performances.
Démarrez PostgreSQL en gardant la valeur shared_buffer définie sur 128 Mo par défaut
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startConnectez-vous au serveur et créez une table factice tblDummy et un index sur c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Remplir les données factices avec 200 000 tuples, de sorte qu'il y ait 10 000 p_id uniques et pour chaque p_id, il y a 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Redémarrez le serveur pour vider le cache. Exécutez maintenant une requête et vérifiez le temps nécessaire pour l'exécuter
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msEnsuite, vérifiez les blocs lus depuis le disque
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Dans l'exemple ci-dessus, 1 000 blocs ont été lus à partir du disque pour trouver le nombre de tuples où c_id =1. Il a fallu 160 ms car des E/S de disque étaient impliquées pour récupérer ces enregistrements sur le disque.
L'exécution est plus rapide si la même requête est réexécutée, car tous les blocs sont encore dans le cache du serveur PostgreSQL à ce stade
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 mset blocs lus depuis le disque vs depuis le cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Il est évident d'en haut que puisque tous les blocs ont été lus depuis le cache et qu'aucune E/S disque n'était nécessaire. Cela a donc également donné les résultats plus rapidement.
Définir la taille du cache PostgreSQL
La taille du cache doit être ajustée dans un environnement de production en fonction de la quantité de RAM disponible ainsi que des requêtes à exécuter.
Par exemple, un buffer_partagé de 128 Mo peut ne pas être suffisant pour mettre en cache toutes les données, si la requête devait récupérer plus de tuples :
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Changez le shared_buffer à 1024 Mo pour augmenter le heap_blks_hit.
En fait, compte tenu des requêtes (basées sur c_id), dans le cas où les données sont réorganisées, un meilleur taux d'accès au cache peut également être obtenu avec un shared_buffer plus petit.
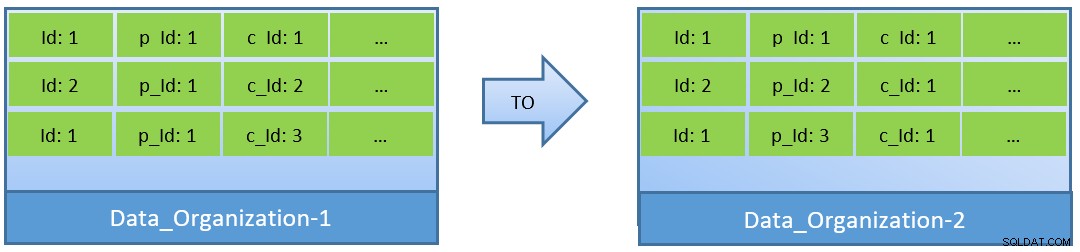
Dans Data_Organization-1, PostgreSQL aura besoin de 1000 lectures de blocs (et de consommation de cache ) pour trouver c_id=1. En revanche, pour Data_Organisation-2, pour la même requête, PostgreSQL n'aura besoin que de 104 blocs.
Moins de blocs requis pour la même requête consomment finalement moins de cache et optimisent également le temps d'exécution de la requête.
Conclusion
Alors que le shared_buffer est maintenu au niveau du processus PostgreSQL, le cache au niveau du noyau est également pris en considération pour identifier les plans d'exécution de requête optimisés. J'aborderai ce sujet dans une prochaine série de blogs.