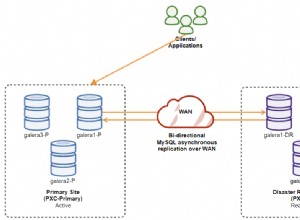
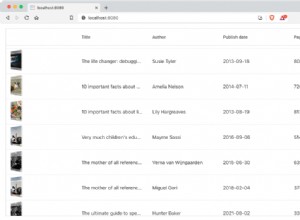
En supposant id_pracownika est la PRIMARY KEY du tableau. Ou au moins défini UNIQUE . (Si ce n'est pas NOT NULL , NULL est un cas d'angle.)
SELECT ou INSERT
Votre fonction est une autre implémentation de "SELECT ou INSERT" - une variante de UPSERT problème, qui est plus complexe face à la charge d'écriture simultanée qu'il n'y paraît. Voir :
- SELECT ou INSERT est-il dans une fonction sujette à des conditions de concurrence ?
Avec UPSERT dans Postgres 9.5 ou version ultérieure
Dans Postgres 9.5 ou version ultérieure, utilisez UPSERT (INSERT ... ON CONFLICT ... ) Détails dans le Wiki Postgres. Cette nouvelle syntaxe fait un travail propre :
CREATE OR REPLACE FUNCTION hire(
_id_pracownika integer
, _imie varchar
, _nazwisko varchar
, _miasto varchar
, _pensja real)
RETURNS text
LANGUAGE plpgsql AS
$func$
BEGIN
INSERT INTO pracownicy
( id_pracownika, imie, nazwisko, miasto, pensja)
VALUES (_id_pracownika,_imie,_nazwisko,_miasto,_pensja);
ON CONFLICT DO NOTHING
RETURNING 'OK';
IF NOT FOUND THEN
RETURN 'JUZ ISTNIEJE';
END IF;
END
$func$;
Table-qualifier les noms de colonne pour lever l'ambiguïté si nécessaire. (Vous pouvez également préfixer les paramètres de fonction avec le nom de la fonction, mais cela devient facilement gênant.)
Mais les noms de colonne dans la liste cible d'un INSERT peut ne pas être qualifié de table. (Jamais ambigu de toute façon.)
Mieux vaut éviter de telles ambiguïtés a priori, c'est moins sujet aux erreurs. Certains (dont moi) aiment le faire en préfixant tous les paramètres de fonction et les variables avec un trait de soulignement.
Si vous avez vraiment besoin un nom de colonne comme nom de paramètre de fonction également, une façon d'éviter les collisions de noms est d'utiliser un ALIAS à l'intérieur de la fonction. Un des rares cas où ALIAS est réellement utile.
Ou référencez les paramètres de la fonction par position ordinale :$1 pour id_pracownika dans ce cas.
Si tout le reste échoue, vous pouvez décider ce qui a priorité en définissant #variable_conflict . Voir :
- Conflit de nom entre le paramètre de la fonction et le résultat de JOIN avec la clause USING
Il y a plus :
-
Il y a des subtilités dans le
RETURNINGclause dans un UPSERT. Voir :- Comment utiliser RETURNING avec ON CONFLICT dans PostgreSQL ?
-
Les littéraux de chaîne (constantes de texte) doivent être placés entre guillemets simples :'OK', et non
"OK"- Insérer du texte avec des guillemets simples dans PostgreSQL
-
L'affectation de variables est comparativement plus coûteuse que dans d'autres langages de programmation. Gardez les affectations au minimum pour de meilleures performances dans plpgsql. Faites autant que possible directement dans les instructions SQL.
-
VOLATILE COST 100sont des décorateurs par défaut pour les fonctions. Inutile de les épeler.
Sans UPSERT dans Postgres 9.4 ou version antérieure
...
IF EXISTS (SELECT FROM pracownicy p
WHERE p.id_pracownika = hire.id_pracownika) THEN
RETURN 'JUZ ISTNIEJE';
ELSE
INSERT INTO pracownicy(id_pracownika,imie,nazwisko,miasto,pensja)
VALUES (hire.id_pracownika,hire.imie,hire.nazwisko,hire.miasto,hire.pensja);
RETURN 'OK';
END IF;
...
Dans un EXISTS expression, le SELECT liste n'a pas d'importance. SELECT id_pracownika , SELECT 1 , ou encore SELECT 1/0 - tous les mêmes. Utilisez simplement un SELECT vide liste. Seule l'existence d'une ligne qualifiante compte. Voir :
- Qu'est-ce qui est plus facile à lire dans les sous-requêtes EXISTS ?