Le cluster Galera applique une forte cohérence des données, où tous les nœuds du cluster sont étroitement couplés. Bien que la segmentation du réseau soit prise en charge, les performances de réplication sont toujours liées à deux facteurs :
-
Le temps d'aller-retour (RTT) entre le nœud le plus éloigné du cluster et le nœud d'origine.
-
La taille d'un jeu d'écriture à transférer et à certifier pour les conflits sur le nœud récepteur.
Bien qu'il existe des moyens d'améliorer les performances de Galera, il n'est pas possible de contourner ces deux facteurs limitants.
Heureusement, Galera Cluster a été construit sur MySQL, qui est également livré avec une fonctionnalité de réplication intégrée (duh !). La réplication Galera et la réplication MySQL existent indépendamment dans le même logiciel serveur. Nous pouvons utiliser ces technologies pour travailler ensemble, où toute la réplication au sein d'un centre de données se fera sur Galera, tandis que la réplication inter-centres de données se fera sur la réplication MySQL standard. Le site esclave peut agir comme un site de secours, prêt à servir des données une fois que les applications sont redirigées vers le site de sauvegarde. Nous en avons parlé dans un blog précédent sur les architectures MySQL pour la reprise après sinistre.
La réplication de cluster à cluster a été introduite dans ClusterControl dans la version 1.7.4. Dans cet article de blog, nous montrerons à quel point il est simple de configurer la réplication entre deux clusters Galera (PXC 8.0). Ensuite, nous examinerons la partie la plus difficile :gérer les défaillances au niveau des nœuds et des clusters à l'aide de ClusterControl ; Les opérations de basculement et de restauration sont essentielles pour préserver l'intégrité des données dans l'ensemble du système.
Déploiement de cluster
Pour les besoins de notre exemple, nous aurons besoin d'au moins deux clusters et deux sites :un pour le principal et un autre pour le secondaire. Il fonctionne de la même manière que la réplication maître-esclave MySQL traditionnelle, mais à plus grande échelle avec trois nœuds de base de données sur chaque site. Avec ClusterControl, vous y parviendrez en déployant un cluster principal, suivi du déploiement du cluster secondaire sur le site de reprise après sinistre en tant que cluster répliqué, répliqué par une réplication asynchrone bidirectionnelle.
Le schéma suivant illustre notre architecture finale :

Nous avons six nœuds de base de données au total, trois sur le site principal et un autre trois sur le site de reprise après sinistre. Pour simplifier la représentation des nœuds, nous utiliserons les notations suivantes :
-
Site principal :
-
galera1-P - 192.168.11.171 (maître)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Site de reprise après sinistre :
-
galera1-DR - 192.168.11.181 (esclave)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Tout d'abord, déployez simplement le premier cluster, et nous l'appelons PXC-Primary. Ouvrez ClusterControl UI → Deploy → MySQL Galera et entrez tous les détails requis :
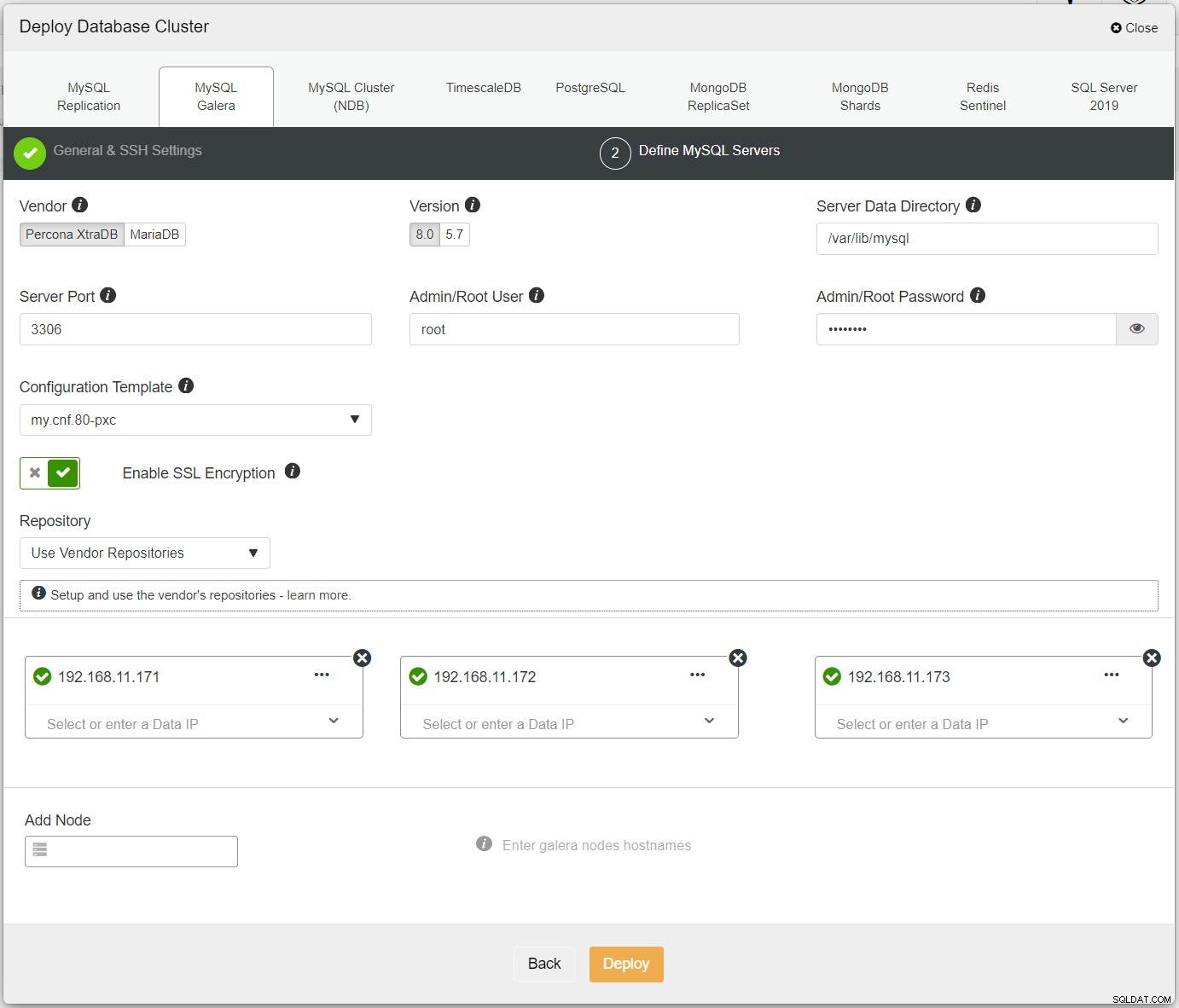
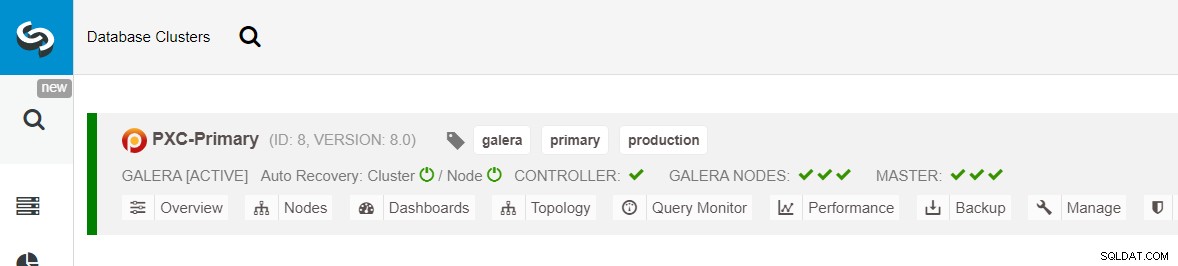
Assurez-vous que chaque nœud spécifié a une coche verte à côté, indiquant que ClusterControl peut se connecter à l'hôte via SSH sans mot de passe. Cliquez sur Déployer et attendez la fin du déploiement. Une fois cela fait, vous devriez voir le cluster suivant répertorié sur la page du tableau de bord du cluster :
Ensuite, nous utiliserons la fonctionnalité ClusterControl appelée Créer un cluster de répliques, accessible depuis la liste déroulante Action de cluster :
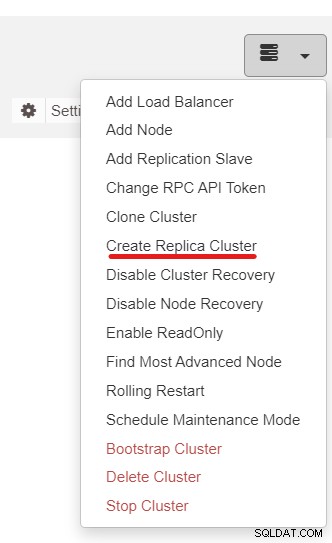
La fenêtre contextuelle suivante s'affichera :
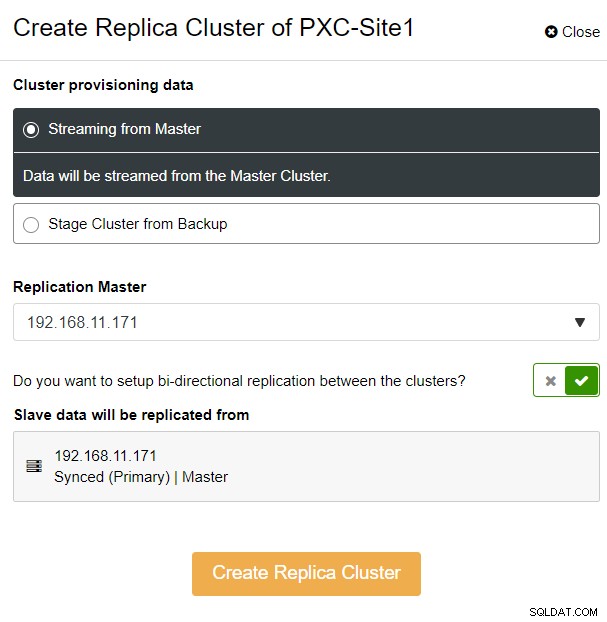
Nous avons choisi l'option "Streaming from Master", où ClusterControl utilisera le maître choisi pour synchroniser le cluster de répliques et configurer la réplication. Faites attention à l'option de réplication bidirectionnelle. Si activé, ClusterControl mettra en place une réplication bidirectionnelle entre les deux sites (réplication circulaire). Le maître choisi répliquera à partir du premier maître défini pour le cluster de répliques et vice versa. Cette configuration réduira le temps de préparation requis lors de la récupération après un basculement ou une restauration automatique. Cliquez sur "Créer un cluster de répliques", où ClusterControl ouvre un nouvel assistant de déploiement pour le cluster de répliques, comme indiqué ci-dessous :
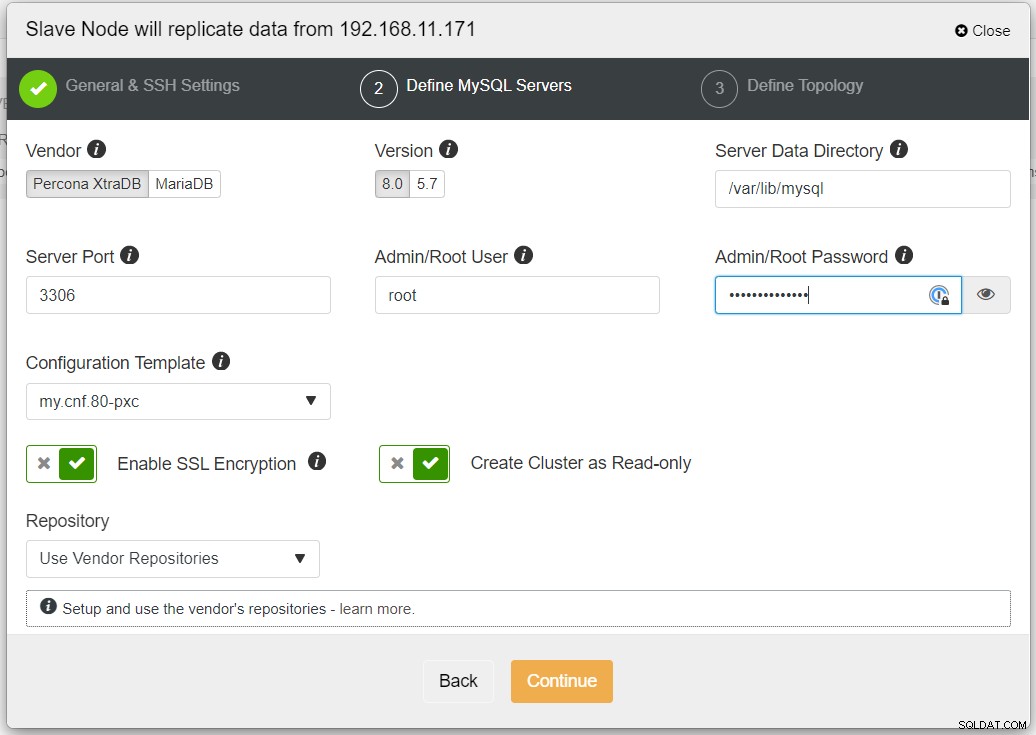
Il est recommandé d'activer le cryptage SSL si la réplication implique des réseaux non fiables tels que WAN, réseaux sans tunnel ou Internet. Assurez-vous également que "Créer un cluster en lecture seule" est activé ; c'est la protection contre les écritures accidentelles et un bon indicateur pour distinguer facilement le cluster actif (lecture-écriture) et le cluster passif (lecture seule).
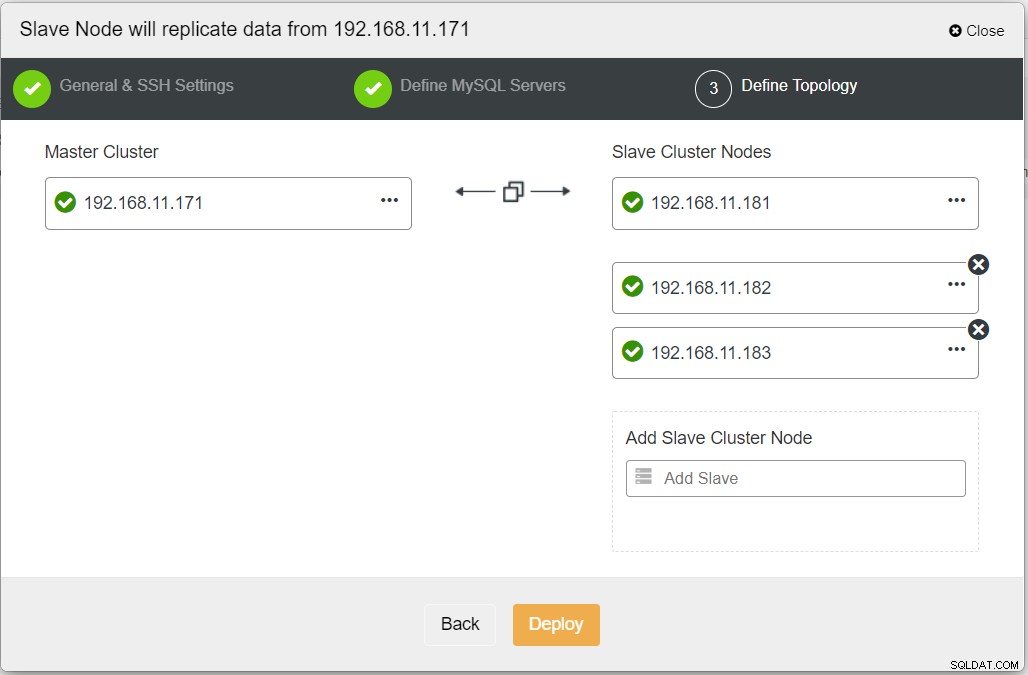
Lorsque vous remplissez toutes les informations nécessaires, vous devez atteindre l'étape suivante pour définir la topologie du cluster de réplicas :
Depuis le tableau de bord ClusterControl, une fois le déploiement terminé, vous devriez voir le Le site DR a une flèche bidirectionnelle connectée au site principal :
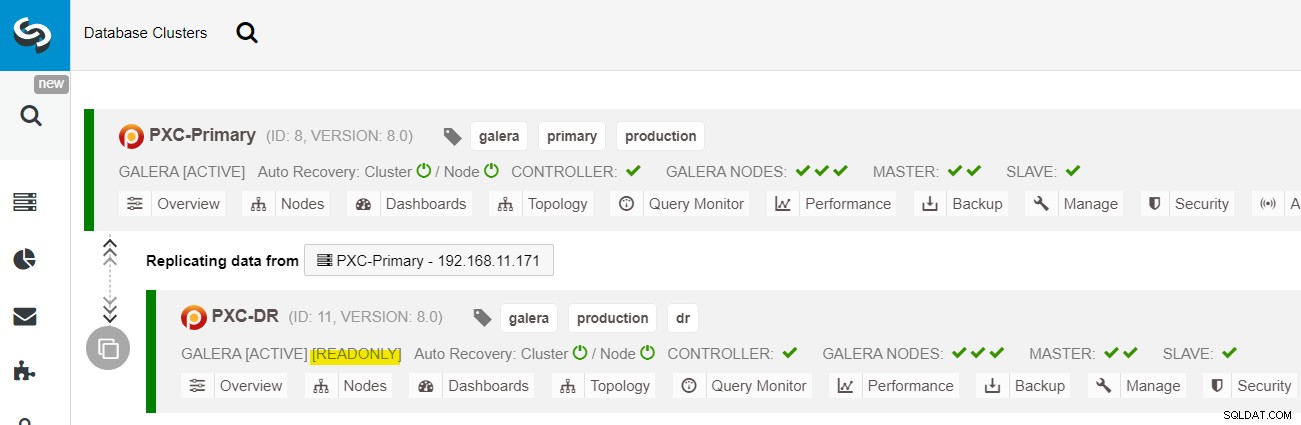
Le déploiement est maintenant terminé. Les applications doivent envoyer des écritures au site principal uniquement puisqu'il s'agit du site actif et que le site DR est configuré en lecture seule (surligné en jaune). Les lectures peuvent être envoyées aux deux sites, bien que le site DR risque d'être à la traîne en raison de la nature de la réplication asynchrone. Cette configuration rendra les sites principaux et de reprise après sinistre indépendants les uns des autres, connectés de manière lâche avec une réplication asynchrone. L'un des nœuds Galera du site DR sera un esclave qui réplique à partir de l'un des nœuds Galera (maître) du site principal.
Nous avons maintenant un système où une panne de cluster sur le site principal n'affectera pas le site de secours. En termes de performances, la latence WAN n'aura pas d'impact sur les mises à jour sur le cluster actif. Ceux-ci sont expédiés de manière asynchrone vers le site de sauvegarde.
En remarque, il est également possible d'avoir une instance esclave dédiée comme relais de réplication au lieu d'utiliser l'un des nœuds Galera comme esclave.
Procédure de basculement du nœud Galera
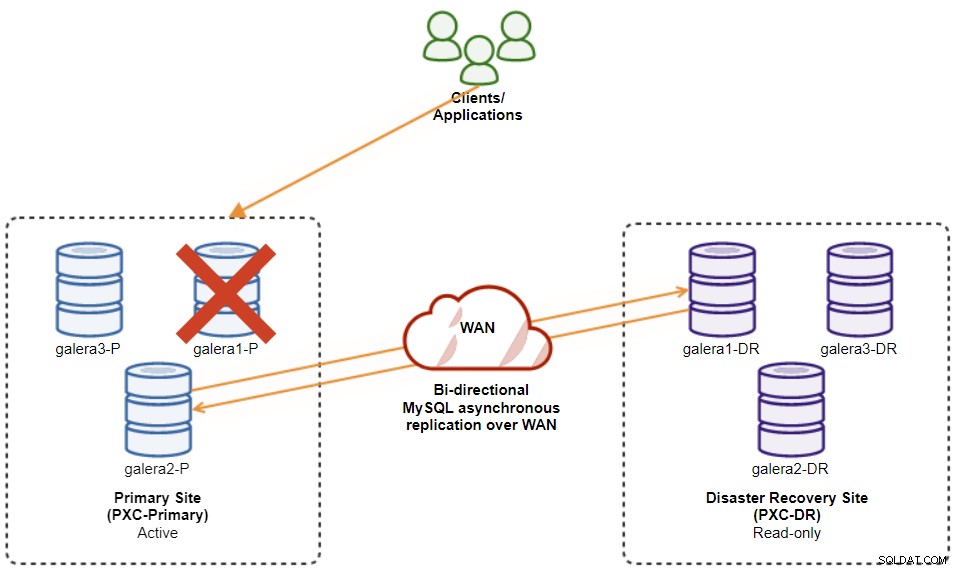
Si le maître actuel (galera1-P) tombe en panne et que les nœuds restants du site principal sont toujours actifs, l'esclave du site de reprise après sinistre (galera1-DR) doit être dirigé vers tous les maîtres disponibles sur le site principal, comme indiqué dans le schéma suivant :
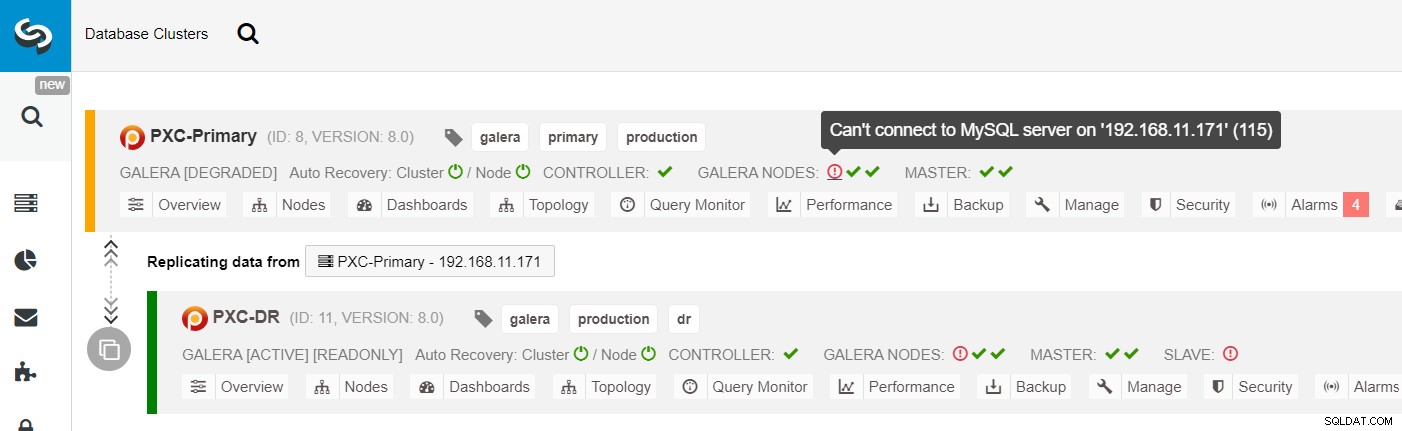
Dans la liste des clusters ClusterControl, vous pouvez voir que l'état du cluster est dégradé , et si vous survolez l'icône du point d'exclamation, vous pouvez voir l'erreur pour ce nœud particulier (galera1-P) :
Avec ClusterControl, vous pouvez simplement accéder au cluster PXC-DR → Nœuds → sélectionner galera1-DR → Actions de nœud → Reconstruire l'esclave de réplication, et la boîte de dialogue de configuration suivante vous sera présentée :
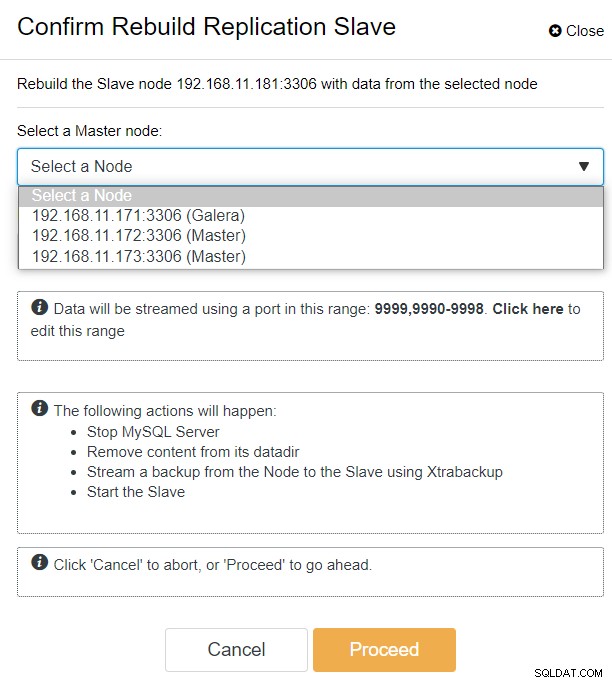
Nous pouvons voir tous les nœuds Galera sur le site principal (192.168.11.17x ) dans la liste déroulante. Choisissez le nœud secondaire, 192.168.11.172 (galera2-P), et cliquez sur Continuer. ClusterControl configurera ensuite la topologie de réplication comme il se doit, en configurant la réplication bidirectionnelle de galera2-P vers galera1-DR. Vous pouvez le confirmer à partir de la page du tableau de bord du cluster (surlignée en jaune) :
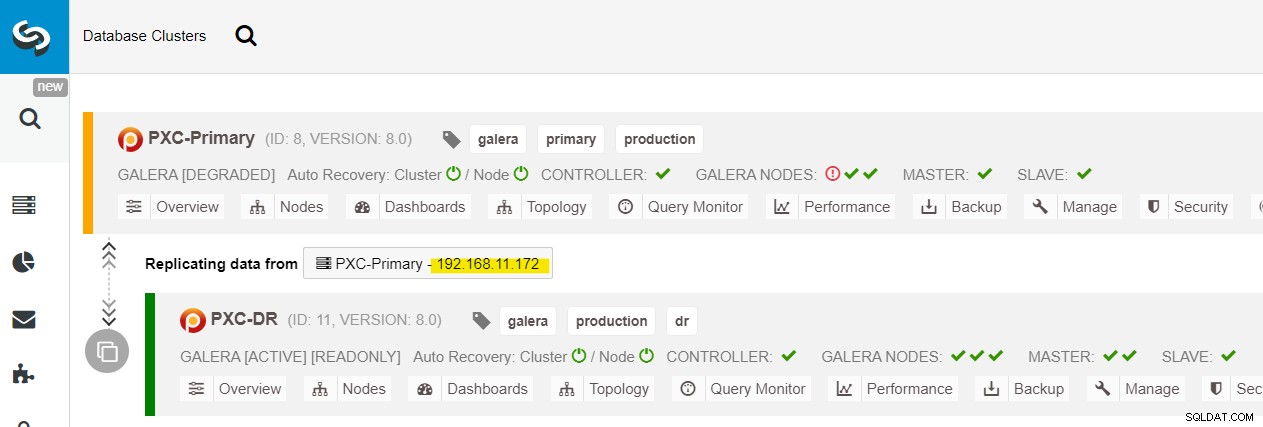
À ce stade, le cluster principal (PXC-Primary) sert toujours comme cluster actif pour cette topologie. Cela ne devrait pas avoir d'incidence sur la disponibilité du service de base de données du cluster principal.
Procédure de basculement du cluster Galera
Si le cluster principal tombe en panne, tombe en panne ou perd simplement la connectivité du point de vue de l'application, l'application peut être dirigée presque instantanément vers le site DR. Le SysAdmin doit simplement désactiver la lecture seule sur tous les nœuds Galera sur le site de reprise après sinistre en utilisant l'instruction suivante :
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRPour les utilisateurs de ClusterControl, vous pouvez utiliser l'interface utilisateur de ClusterControl → Nœuds → choisissez le nœud de base de données → Actions de nœud → Désactiver la lecture seule. La CLI ClusterControl est également disponible en exécutant les commandes suivantes sur le nœud ClusterControl :
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeLe basculement vers le site DR est maintenant terminé et les applications peuvent commencer à envoyer des écritures au cluster PXC-DR. Dans l'interface utilisateur de ClusterControl, vous devriez voir quelque chose comme ceci :
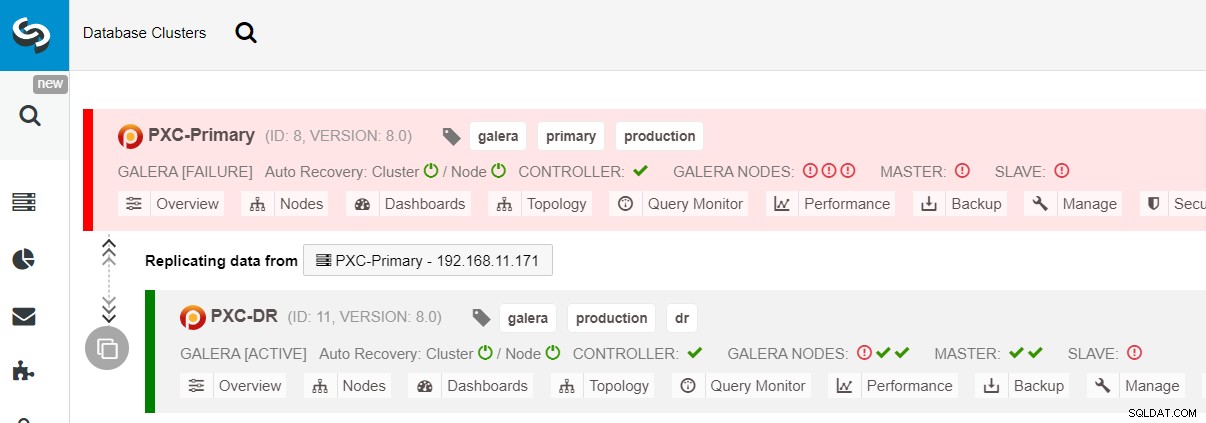
Le schéma suivant montre notre architecture après le basculement de l'application vers le site DR :
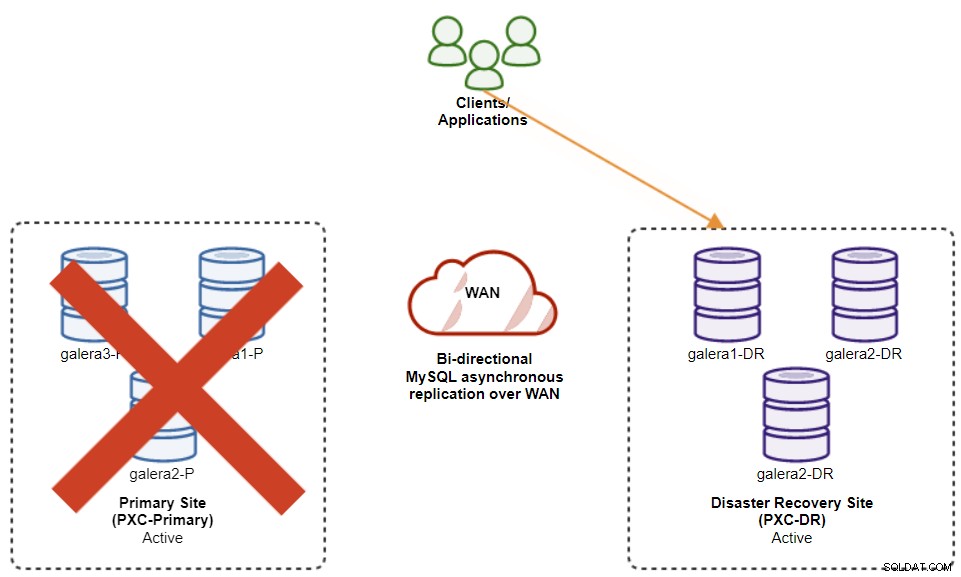
En supposant que le site principal est toujours en panne, à ce stade, il n'y a pas réplication entre les sites jusqu'à ce que le site principal revienne.
Procédure de restauration du cluster Galera
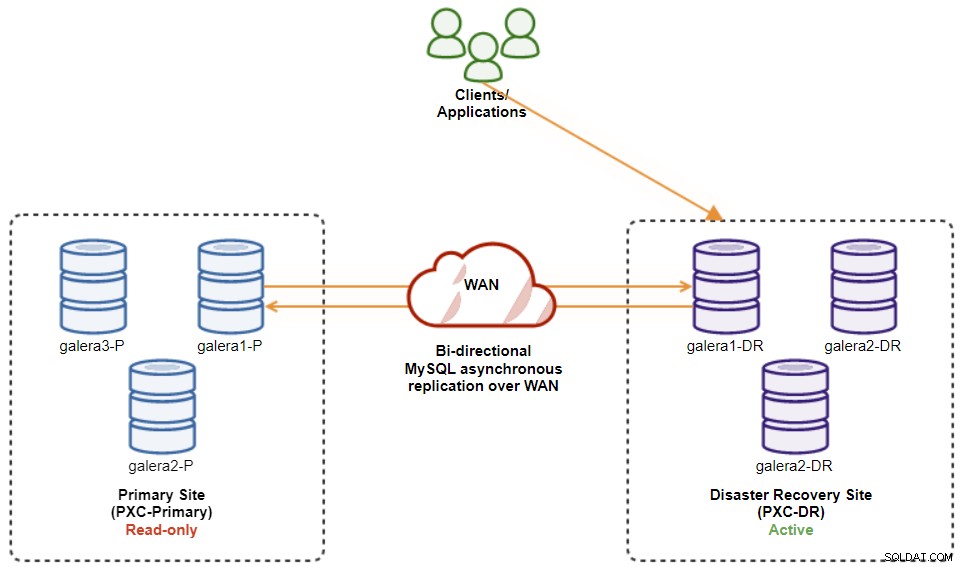
Une fois le site principal lancé, il est important de noter que le cluster principal doit être défini en lecture seule, afin que nous sachions que le cluster actif est celui du site de reprise après sinistre. Dans ClusterControl, accédez au menu déroulant du cluster et choisissez "Activer la lecture seule", ce qui activera la lecture seule sur tous les nœuds du cluster principal et résume la topologie actuelle comme ci-dessous :
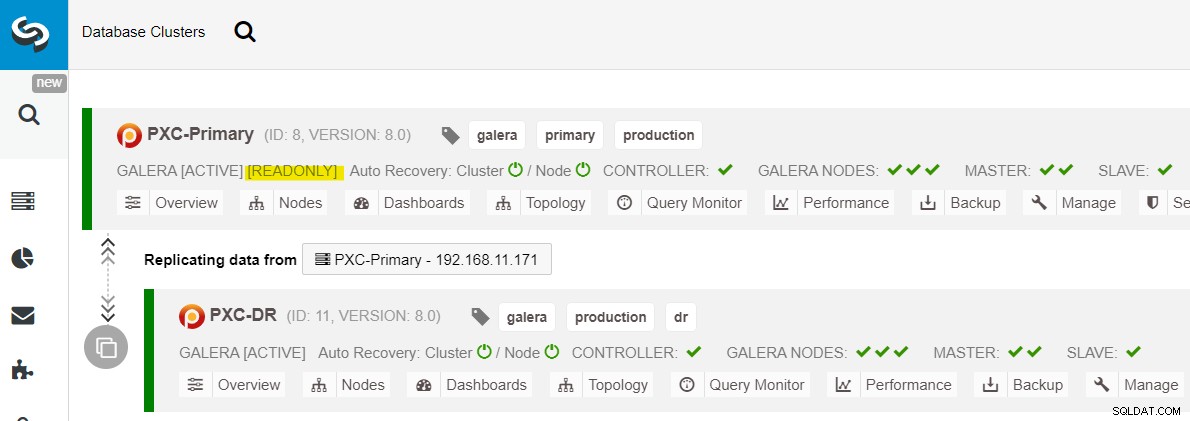
Assurez-vous que tout est vert avant de planifier le démarrage de la procédure de restauration du cluster (vert signifie que tous les nœuds sont actifs et synchronisés les uns avec les autres). S'il y a un nœud en état de dégradation, par exemple, le nœud de réplication est toujours en retard, ou seuls certains des nœuds du cluster principal étaient joignables, attendez que le cluster soit complètement récupéré, soit en attendant les procédures de récupération automatique de ClusterControl à compléter, ou intervention manuelle.
À ce stade, le cluster actif est toujours le cluster du DR et le cluster principal agit comme un cluster secondaire. Le schéma suivant illustre l'architecture actuelle :
Le moyen le plus sûr de revenir au site principal consiste à définir en lecture seule sur le cluster du DR, suivi de la désactivation de la lecture seule sur le site principal. Accédez à ClusterControl UI → PXC-DR (menu déroulant) → Activer la lecture seule. Cela déclenchera une tâche pour définir la lecture seule sur tous les nœuds du cluster du DR. Ensuite, accédez à ClusterControl UI → PXC-Primary → Nodes et désactivez la lecture seule sur tous les nœuds de base de données du cluster principal.
Vous pouvez également simplifier les procédures ci-dessus avec ClusterControl CLI. Vous pouvez également exécuter les commandes suivantes sur l'hôte ClusterControl :
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeUne fois cela fait, la direction de réplication est revenue à sa configuration d'origine, où PXC-Primary est le cluster actif et PXC-DR est le cluster de secours. Le schéma suivant illustre l'architecture finale après l'opération de restauration du cluster :
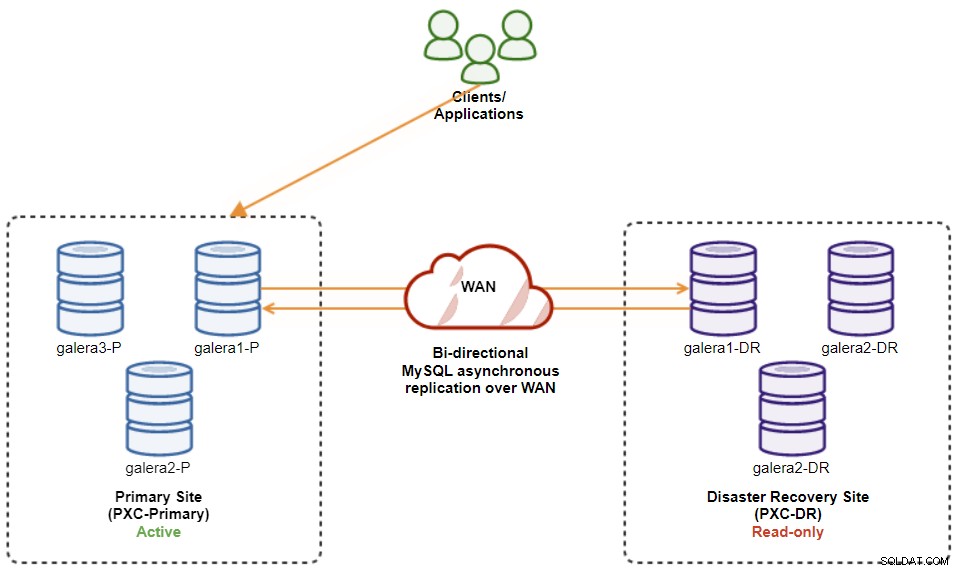
À ce stade, il est maintenant sûr de rediriger les applications pour écrire dessus le site principal.
Avantages de la réplication asynchrone de cluster à cluster
Cluster à cluster avec réplication asynchrone présente de nombreux avantages :
-
Temps d'arrêt minimal lors d'une opération de basculement de base de données. Fondamentalement, vous pouvez rediriger l'écriture presque instantanément vers le site esclave, uniquement si vous pouvez protéger les écritures pour qu'elles n'atteignent pas le site maître (car ces écritures ne seraient pas répliquées et seront probablement écrasées lors de la resynchronisation à partir du site DR).
-
Aucun impact sur les performances du site principal puisqu'il est indépendant du site de secours (DR). La réplication du maître vers l'esclave est effectuée de manière asynchrone. Le site maître génère des journaux binaires, le site esclave réplique les événements et applique les événements ultérieurement.
-
Les sites de récupération après sinistre peuvent être utilisés à d'autres fins, par exemple, la sauvegarde de la base de données, la sauvegarde du journal binaire et la création de rapports, ou requêtes analytiques lourdes (OLAP). Les deux sites peuvent être utilisés simultanément, à l'exception du décalage de réplication et des opérations en lecture seule côté esclave.
-
Le cluster DR pourrait potentiellement s'exécuter sur des instances plus petites dans un environnement de cloud public, tant qu'elles peuvent suivre avec le cluster principal. Vous pouvez mettre à niveau les instances si nécessaire. Dans certains scénarios, cela peut vous faire économiser des coûts.
-
Vous n'avez besoin que d'un site supplémentaire pour la reprise après sinistre par rapport à la configuration de réplication multisite Galera active-active, qui nécessite au moins trois sites actifs pour fonctionner correctement.
Inconvénients de la réplication asynchrone de cluster à cluster
Cette configuration présente également des inconvénients, selon que vous utilisez une réplication bidirectionnelle ou unidirectionnelle :
-
Il est possible que certaines données manquent lors du basculement si l'esclave était en retard, car la réplication est asynchrone. Cela pourrait être amélioré avec la réplication semi-synchrone et multithread des esclaves, bien qu'il y ait un autre ensemble de défis en attente (surcharge du réseau, écart de réplication, etc.).
-
Dans la réplication unidirectionnelle, bien que les procédures de basculement soient assez simples, les procédures de restauration peuvent être délicates et sujettes aux Erreur. Cela nécessite une certaine expertise pour basculer le rôle maître/esclave vers le site principal. Il est recommandé de documenter les procédures, de répéter régulièrement l'opération de basculement/restauration et d'utiliser des outils de rapport et de surveillance précis.
-
Cela peut être assez coûteux, car vous devez configurer un nombre similaire de nœuds sur le site de reprise après sinistre . Ce n'est pas noir sur blanc, car la justification des coûts provient généralement des exigences de votre entreprise. Avec un peu de planification, il est possible de maximiser l'utilisation des ressources de la base de données sur les deux sites, quels que soient les rôles de la base de données.
Conclusion
La configuration de la réplication asynchrone pour vos clusters MySQL Galera peut être un processus relativement simple, tant que vous comprenez comment gérer correctement les pannes au niveau du nœud et du cluster. En fin de compte, les opérations de basculement et de restauration sont essentielles pour garantir l'intégrité des données.
Pour plus de conseils sur la conception de vos clusters Galera avec des stratégies de basculement et de restauration à l'esprit, consultez cet article sur les architectures MySQL pour la reprise après sinistre. Si vous cherchez de l'aide pour automatiser ces opérations, évaluez gratuitement ClusterControl pendant 30 jours et suivez les étapes décrites dans cet article.
N'oubliez pas de nous suivre sur Twitter ou LinkedIn et de vous abonner à notre newsletter pour rester informé des dernières nouvelles et des meilleures pratiques pour gérer vos infrastructures de bases de données open source.