Je sais que c'est une question assez ancienne, mais je viens de parcourir un petit exemple dans ma tête qui m'a aidé à comprendre pourquoi Postgres a cette restriction apparemment étrange sur les colonnes SELECT DISTINCT / ORDER BY.
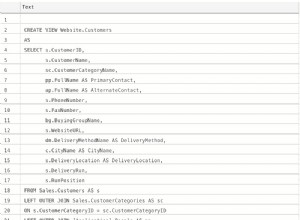
Imaginez que vous ayez les données suivantes dans votre tableau Rsvp :
event_id | start_time
----------+------------------------
0 | Mar 17, 2013 12:00:00
1 | Jan 1, 1970 00:00:00
1 | Aug 21, 2013 16:30:00
2 | Jun 9, 2012 08:45:00
Maintenant, vous voulez récupérer une liste d'event_ids distincts, classés par leurs start_times respectifs. Mais où devrait 1 aller? Doit-il venir en premier, car le premier tuple commence le 1er janvier 1970, ou doit-il passer en dernier à cause du 21 août 2013 ?
Comme le système de base de données ne peut pas prendre cette décision pour vous et que la syntaxe de la requête ne peut pas dépendre des données réelles sur lesquelles elle pourrait fonctionner (en supposant que event_id est unique), nous sommes limités à trier uniquement par colonnes du SELECT clause.
Quant à la question réelle - une alternative à la réponse de Matthew consiste à utiliser une fonction d'agrégation telle que MIN ou MAX pour le tri :
SELECT event_id
FROM Rsvp
GROUP BY event_id
ORDER BY MIN(start_time)
Le regroupement et l'agrégation explicites sur start_time permettre à la base de données de proposer un ordre sans ambiguïté des tuples de résultat. Notez cependant que la lisibilité est définitivement un problème dans ce cas;)