Le ANY l'agrégat n'est pas quelque chose que nous pouvons écrire directement dans Transact SQL. Il s'agit d'une fonctionnalité interne uniquement utilisée par l'optimiseur de requêtes et le moteur d'exécution.
Personnellement, j'aime beaucoup le ANY global, il était donc un peu décevant d'apprendre qu'il est cassé d'une manière assez fondamentale. La saveur particulière de «cassé» à laquelle je fais référence ici est la variété des mauvais résultats.
Dans cet article, je jette un œil à deux endroits particuliers où le ANY l'agrégat apparaît généralement, démontre le problème des résultats erronés et suggère des solutions de contournement si nécessaire.
Pour le fond sur le ANY agrégé, veuillez consulter mon article précédent Plans de requête non documentés :l'agrégat ANY.
1. Une ligne par groupe de requêtes
Cela doit être l'une des exigences de requête les plus courantes au quotidien, avec une solution très connue. Vous écrivez probablement ce type de requête tous les jours, en suivant automatiquement le modèle, sans vraiment y penser.
L'idée est de numéroter l'ensemble de lignes d'entrée à l'aide du ROW_NUMBER fonction de fenêtre, partitionnée par la ou les colonnes de regroupement. Cela est enveloppé dans une expression de table commune ou table dérivée , et filtré jusqu'aux lignes où le numéro de ligne calculé est égal à un. Depuis le ROW_NUMBER redémarre à un pour chaque groupe, cela nous donne la ligne requise par groupe.
Il n'y a aucun problème avec ce modèle général. Le type d'une ligne par requête de groupe soumise à ANY le problème d'agrégation est celui où nous peu importe quelle ligne particulière est sélectionnée de chaque groupe.
Dans ce cas, il n'est pas clair quelle colonne doit être utilisée dans l'obligatoire ORDER BY clause du ROW_NUMBER fonction fenêtre. Après tout, nous ne nous soucions explicitement pas quelle ligne est sélectionnée. Une approche courante consiste à réutiliser le PARTITION BY colonne(s) dans ORDER BY clause. C'est là que le problème peut survenir.
Exemple
Prenons un exemple utilisant un ensemble de données de jouets :
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
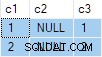
L'exigence est de renvoyer une ligne complète de données de chaque groupe, où l'appartenance au groupe est définie par la valeur dans la colonne c1 .

Après le ROW_NUMBER modèle, nous pourrions écrire une requête comme celle-ci (remarquez le ORDER BY clause du ROW_NUMBER la fonction de fenêtre correspond à la PARTITION BY clause):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Comme présenté, cette requête s'exécute avec succès, avec des résultats corrects. Les résultats sont techniquement non déterministes étant donné que SQL Server peut renvoyer de manière valide n'importe laquelle des lignes de chaque groupe. Néanmoins, si vous lancez cette requête vous-même, vous obtiendrez probablement le même résultat que moi :
Le plan d'exécution dépend de la version de SQL Server utilisée et ne dépend pas du niveau de compatibilité de la base de données.
Sur SQL Server 2014 et versions antérieures, le plan est :

Pour SQL Server 2016 ou version ultérieure, vous verrez :

Les deux plans sont sûrs, mais pour des raisons différentes. Le tri distinct le plan contient un ANY agrégat, mais le tri distinct l'implémentation de l'opérateur ne manifeste pas le bogue.
Le plan SQL Server 2016+ plus complexe n'utilise pas le ANY agréger du tout. Le Trier place les lignes dans l'ordre nécessaire à l'opération de numérotation des lignes. Le segment l'opérateur définit un indicateur au début de chaque nouveau groupe. Le Projet Séquence calcule le numéro de ligne. Enfin, le Filtre l'opérateur transmet uniquement les lignes dont le numéro de ligne calculé est égal à un.
Le bogue
Pour obtenir des résultats incorrects avec cet ensemble de données, nous devons utiliser SQL Server 2014 ou une version antérieure, et le ANY les agrégats doivent être implémentés dans un Stream Aggregate ou Désireux Agrégat de hachage opérateur (Flow Distinct Hash Match Aggregate ne produit pas le bogue).
Une façon d'inciter l'optimiseur à choisir un Stream Aggregate au lieu de Tri distinct consiste à ajouter un index clusterisé pour fournir un classement par colonne c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Après ce changement, le plan d'exécution devient :

Le ANY les agrégats sont visibles dans les Propriétés fenêtre lorsque le Stream Aggregate l'opérateur est sélectionné :

Le résultat de la requête est :
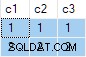
C'est faux . SQL Server a renvoyé des lignes qui n'existent pas dans les données sources. Il n'y a pas de lignes source où c2 = 1 et c3 = 1 par exemple. Pour rappel, les données sources sont :
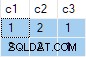
Le plan d'exécution calcule par erreur séparé ANY agrégats pour le c2 et c3 colonnes, en ignorant les valeurs nulles. Chaque agrégat indépendamment renvoie le premier non nul valeur qu'il rencontre, donnant un résultat où les valeurs de c2 et c3 proviennent de différentes lignes source . Ce n'est pas ce que la spécification de la requête SQL d'origine demandait.
Le même résultat erroné peut être produit avec ou sans l'index clusterisé en ajoutant un OPTION (HASH GROUP) indice pour produire un plan avec un Eager Hash Aggregate au lieu d'un Stream Aggregate .
Conditions
Ce problème ne peut se produire que lorsque plusieurs ANY des agrégats sont présents et les données agrégées contiennent des valeurs nulles. Comme indiqué, le problème n'affecte que Stream Aggregate et impatient agrégat de hachage les opérateurs; Tri distinct et flux distinct ne sont pas affectés.
SQL Server 2016 et les versions ultérieures s'efforcent d'éviter d'introduire plusieurs ANY agrégats pour n'importe quel modèle de requête de numérotation de ligne par groupe lorsque les colonnes source acceptent les valeurs NULL. Lorsque cela se produit, le plan d'exécution contiendra Segment , Projet de séquence , et Filtrer opérateurs au lieu d'un agrégat. Cette forme de plan est toujours sûre, car aucun ANY des agrégats sont utilisés.
Reproduire le bogue dans SQL Server 2016+
L'optimiseur SQL Server n'est pas parfait pour détecter quand une colonne initialement contrainte à être NOT NULL peut toujours produire une valeur intermédiaire nulle via des manipulations de données.
Pour reproduire cela, nous allons commencer par une table où toutes les colonnes sont déclarées comme NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Nous pouvons produire des valeurs nulles à partir de cet ensemble de données de plusieurs manières, dont la plupart peuvent être détectées avec succès par l'optimiseur, et ainsi éviter d'introduire ANY agrégats lors de l'optimisation.
Une façon d'ajouter des valeurs nulles qui passent inaperçues est illustrée ci-dessous :
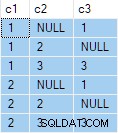
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Cette requête produit le résultat suivant :
L'étape suivante consiste à utiliser cette spécification de requête comme données source pour la requête standard "n'importe quelle ligne par groupe" :
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Sur toute version de SQL Server, qui produit le plan suivant :
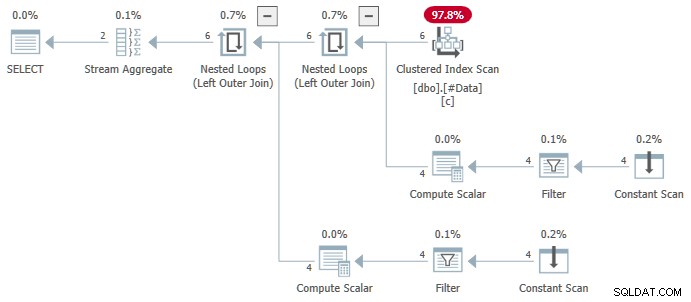
L'agrégat de flux contient plusieurs ANY agrégats, et le résultat est faux . Aucune des lignes renvoyées n'apparaît dans l'ensemble de données source :
db<>démo en ligne violon
Solution de contournement
La seule solution de contournement entièrement fiable jusqu'à ce que ce bogue soit corrigé est d'éviter le modèle où le ROW_NUMBER a la même colonne dans le ORDER BY clause telle quelle dans la PARTITION BY clause.
Quand nous nous moquons de qui une ligne est sélectionnée dans chaque groupe, il est dommage qu'un ORDER BY clause est nécessaire du tout. Une façon d'éviter le problème consiste à utiliser une constante d'exécution telle que ORDER BY @@SPID dans la fonction fenêtre.
2. Mise à jour non déterministe
Le problème avec plusieurs ANY les agrégats sur les entrées nullables ne sont pas limités au modèle de requête d'une ligne par groupe. L'optimiseur de requête peut introduire un ANY interne regrouper dans un certain nombre de circonstances. L'un de ces cas est une mise à jour non déterministe.
Un non déterministe update est l'endroit où l'instruction ne garantit pas que chaque ligne cible sera mise à jour au plus une fois. En d'autres termes, il existe plusieurs lignes source pour au moins une ligne cible. La documentation met explicitement en garde à ce sujet :
Soyez prudent lorsque vous spécifiez la clause FROM pour fournir les critères de l'opération de mise à jour.Les résultats d'une instruction UPDATE sont indéfinis si l'instruction inclut une clause FROM qui n'est pas spécifiée de manière à ce qu'une seule valeur soit disponible pour chaque occurrence de colonne mise à jour, qui est si l'instruction UPDATE n'est pas déterministe.
Pour gérer une mise à jour non déterministe, l'optimiseur regroupe les lignes par clé (index ou RID) et applique ANY s'agrège aux colonnes restantes. L'idée de base est de choisir une ligne parmi plusieurs candidats et d'utiliser les valeurs de cette ligne pour effectuer la mise à jour. Il existe des parallèles évidents avec le précédent ROW_NUMBER problème, il n'est donc pas surprenant qu'il soit assez facile de démontrer une mise à jour incorrecte.
Contrairement au problème précédent, SQL Server ne prend actuellement aucune mesure particulière pour éviter plusieurs ANY agrégats sur des colonnes nullables lors de l'exécution d'une mise à jour non déterministe. Ce qui suit concerne donc toutes les versions de SQL Server , y compris SQL Server 2019 CTP 3.0.
Exemple
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>démo en ligne violon
Logiquement, cette mise à jour devrait toujours produire une erreur :la table cible n'autorise les valeurs nulles dans aucune colonne. Quelle que soit la ligne correspondante choisie dans la table source, une tentative de mise à jour de la colonne c2 ou c3 à null doit se produire.
Malheureusement, la mise à jour réussit et l'état final de la table cible est incohérent avec les données fournies :
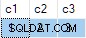
J'ai signalé cela comme un bug. La solution consiste à éviter d'écrire UPDATE non déterministe instructions, donc ANY les agrégats ne sont pas nécessaires pour résoudre l'ambiguïté.
Comme mentionné, SQL Server peut introduire ANY agrégats dans plus de circonstances que les deux exemples donnés ici. Si cela se produit lorsque la colonne agrégée contient des valeurs nulles, il existe un risque de résultats erronés.