Assurer le bon fonctionnement de vos bases de données de production n'est pas une tâche triviale, et il existe un certain nombre d'outils et d'utilitaires pour vous aider dans cette tâche. Il existe des outils disponibles pour surveiller la santé, les performances du serveur, analyser les requêtes, les déploiements, gérer le basculement, les mises à niveau, et la liste continue. ClusterControl en tant que plate-forme de gestion et de surveillance de votre infrastructure de base de données se distingue par sa capacité à gérer le cycle de vie complet du déploiement à la surveillance, la gestion continue et la mise à l'échelle.
Bien que ClusterControl offre des fonctionnalités importantes telles que le basculement automatique de la base de données, le chiffrement en transit/au repos, la gestion des sauvegardes, la récupération ponctuelle, l'intégration Prometheus, la mise à l'échelle de la base de données, celles-ci peuvent être trouvées dans d'autres outils de gestion/surveillance d'entreprise sur le marché. Cependant, il y a certaines fonctionnalités que vous ne trouverez pas aussi facilement. Dans cet article de blog, nous présenterons 9 fonctionnalités que vous ne trouverez dans aucun autre outil de gestion et de surveillance sur le marché (au moment de la rédaction de cet article).
Vérification de sauvegarde
Toute sauvegarde n'est littéralement pas une sauvegarde tant que vous ne savez pas qu'elle peut être récupérée - en vérifiant réellement qu'elle peut être récupérée. ClusterControl permet de vérifier une sauvegarde une fois la sauvegarde effectuée en faisant tourner un nouveau serveur et en testant la restauration. La vérification d'une sauvegarde est un processus critique pour vous assurer que vous respectez votre politique d'objectif de point de récupération (RPO) en cas de reprise après sinistre. Le processus de vérification effectuera la restauration sur un nouvel hôte autonome (où ClusterControl installera les packages de base de données nécessaires avant la restauration) ou sur un serveur dédié à la vérification de sauvegarde.
Pour configurer la vérification des sauvegardes, sélectionnez simplement une sauvegarde existante et cliquez sur Restaurer. Il y aura une option pour restaurer et vérifier :
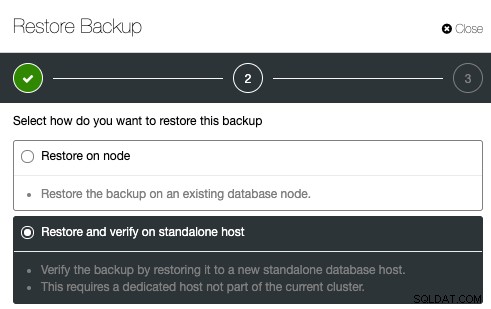
Ensuite, indiquez simplement l'adresse IP du serveur que vous souhaitez restaurer et vérifier :
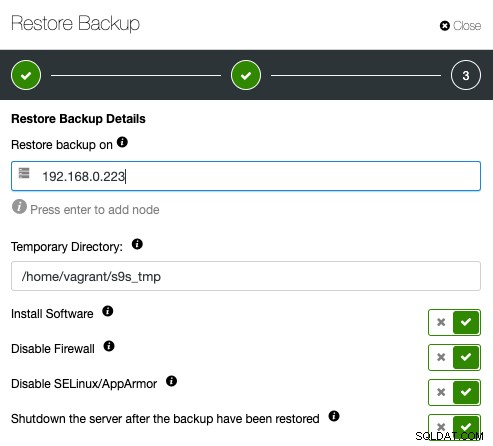
Assurez-vous au préalable que l'hôte spécifié est accessible via SSH sans mot de passe. Vous avez également une poignée d'options en dessous pour le processus d'approvisionnement. Vous pouvez également arrêter le serveur de vérification après la restauration pour économiser des coûts et des ressources une fois la sauvegarde vérifiée. ClusterControl recherchera le code de sortie du processus de restauration et observera le journal de restauration pour vérifier si la vérification échoue ou réussit.
Simplification de la gestion de ProxySQL via une interface graphique
Beaucoup conviendraient que le fait d'avoir une interface utilisateur graphique est plus efficace et moins sujet aux erreurs humaines lors de la configuration d'un système. ProxySQL fait partie de la couche critique de la base de données (bien qu'il se trouve au-dessus de celle-ci) et doit être suffisamment visible aux yeux du DBA pour repérer les problèmes et problèmes courants. ClusterControl fournit une interface utilisateur graphique complète pour ProxySQL.
Les instances ProxySQL peuvent être déployées sur de nouveaux hôtes, ou celles existantes peuvent être importées dans ClusterControl. ClusterControl peut configurer ProxySQL pour qu'il soit intégré à une adresse IP virtuelle (fournie par Keepalived) pour un accès unique aux serveurs de base de données. Il fournit également des informations de surveillance sur les composants clés de ProxySQL, tels que le backend des requêtes, les requêtes lentes, les principales requêtes, les résultats de requête et un tas d'autres statistiques de surveillance. Voici une capture d'écran montrant comment ajouter une nouvelle règle de requête :
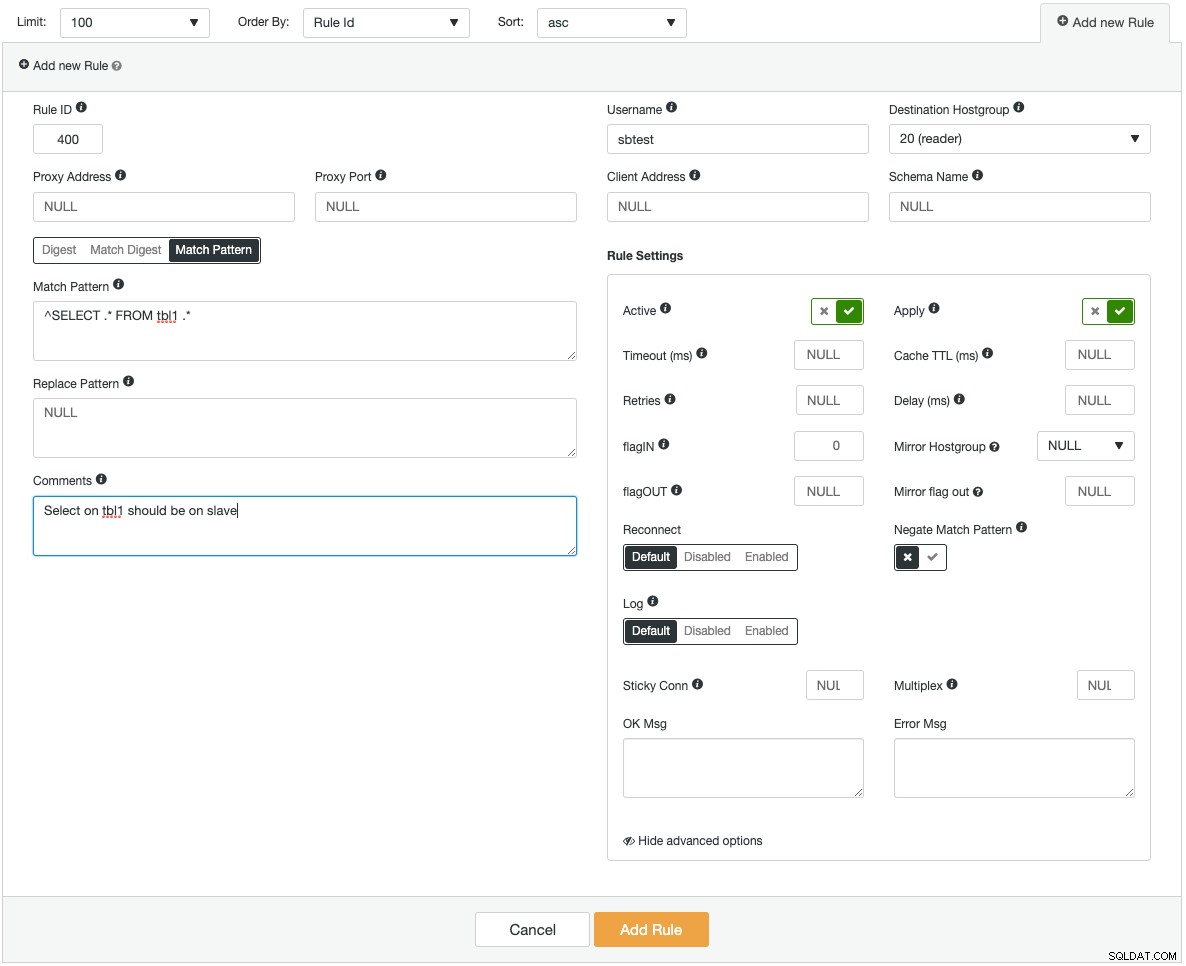
Si vous ajoutiez une règle de requête très complexe, vous seriez plus à l'aise de le faire via l'interface utilisateur graphique. Chaque champ comporte une info-bulle pour vous aider à remplir le formulaire de règle de requête. Lors de l'ajout ou de la modification d'une configuration ProxySQL, ClusterControl s'assurera que les modifications sont apportées à l'exécution et enregistrées sur le disque pour la persistance.
ClusterControl 1.7.4 prend désormais en charge ProxySQL 1.x et ProxySQL 2.x.
Rapports opérationnels
Les rapports opérationnels sont un ensemble de rapports récapitulatifs de votre infrastructure de base de données qui peuvent être générés à la volée ou programmés pour être envoyés à différents destinataires. Ces rapports consistent en différentes vérifications et traitent de diverses tâches DBA quotidiennes. L'idée derrière le reporting opérationnel de ClusterControl est de mettre toutes les données les plus pertinentes dans un seul document qui peut être rapidement analysé afin d'avoir une compréhension claire de l'état des bases de données et de ses processus.
Avec ClusterControl, vous pouvez planifier des rapports d'environnement inter-cluster comme le rapport système quotidien, le rapport de mise à niveau de package, le rapport de changement de schéma ainsi que les sauvegardes et la disponibilité. Ces rapports vous aideront à maintenir votre environnement sécurisé et opérationnel. Vous verrez également des recommandations sur la façon de corriger les lacunes. Les rapports peuvent être adressés aux SysOps, DevOps ou même aux gestionnaires qui souhaitent obtenir des mises à jour régulières sur l'état d'un système donné.
Voici un exemple de rapport opérationnel quotidien envoyé à votre boîte aux lettres en ce qui concerne la disponibilité :
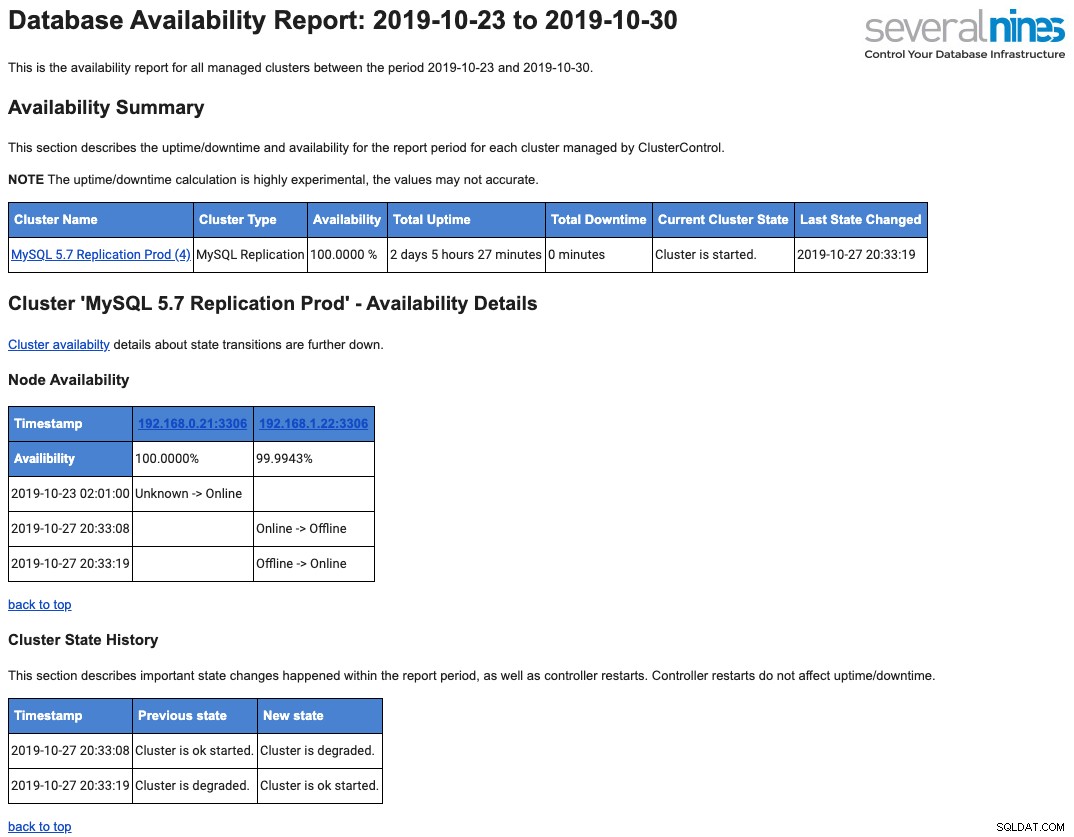
Nous avons couvert cela en détail dans cet article de blog, Un aperçu des rapports opérationnels de base de données dans ClusterControl.
Resynchroniser un esclave via la sauvegarde
ClusterControl permet de mettre en scène un esclave (qu'il s'agisse d'un nouvel esclave ou d'un esclave défectueux) via la dernière sauvegarde complète ou incrémentielle. Cela ne semble pas très excitant, mais cette fonctionnalité est énorme si vous avez de grands ensembles de données de 100 Go et plus. La pratique courante lors de la resynchronisation d'un esclave consiste à diffuser une sauvegarde du maître actuel, ce qui prendra un certain temps en fonction de la taille de la base de données. Cela ajoutera une charge supplémentaire au maître, ce qui peut compromettre les performances du maître.
Pour resynchroniser un esclave via une sauvegarde, sélectionnez le nœud esclave sous la page Nœuds et accédez à Actions de nœud -> Reconstruire l'esclave de réplication -> Reconstruire à partir d'une sauvegarde. Seule la sauvegarde compatible PITR sera répertoriée dans la liste déroulante :
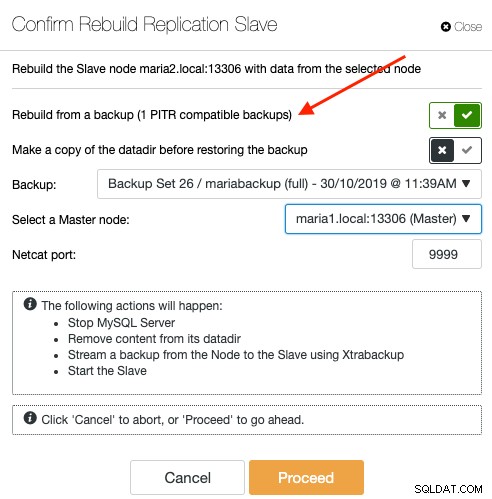
La resynchronisation d'un esclave à partir d'une sauvegarde n'apportera aucune surcharge supplémentaire au maître, où ClusterControl extrait et diffuse la sauvegarde de l'emplacement de stockage de sauvegarde vers l'esclave et configure éventuellement le lien de réplication entre l'esclave et le maître. L'esclave rattrapera plus tard le maître une fois le lien de réplication établi. Le maître est intact pendant tout le processus et vous pouvez surveiller l'ensemble de la progression sous Activité -> Travaux.
Amorcer un cluster Galera
Galera Cluster est très populaire lors de la mise en œuvre de la haute disponibilité pour MySQL ou MariaDB, mais de mauvaises commandes de gestion peuvent avoir des conséquences désastreuses. Jetez un œil à cet article de blog sur la façon de démarrer un cluster Galera dans différentes conditions. Cela montre que l'amorçage d'un cluster Galera comporte de nombreuses variables et doit être effectué avec un soin extrême. Sinon, vous risquez de perdre des données ou de provoquer un split-brain. ClusterControl comprend la topologie de la base de données et sait exactement quoi faire pour amorcer correctement un cluster de base de données. Pour démarrer un cluster via ClusterControl, cliquez sur les Actions du cluster -> Bootstrap Cluster :
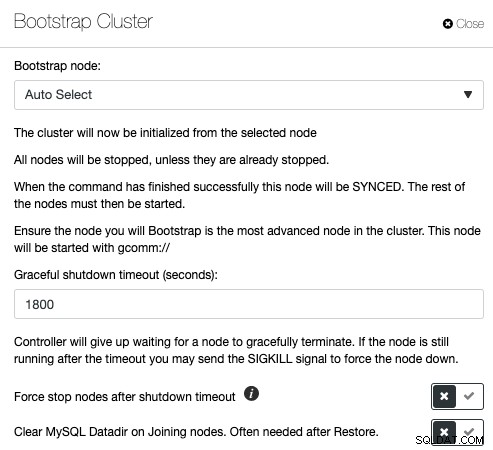
Vous aurez la possibilité de laisser ClusterControl sélectionner automatiquement le bon nœud d'amorçage ou d'effectuer un démarrage initial où vous choisissez l'un des nœuds de base de données dans la liste pour devenir le nœud de référence et effacer le répertoire de données MySQL sur les nœuds de jointure pour forcer SST à partir de le nœud amorcé. Si le processus d'amorçage échoue, ClusterControl extrait le journal des erreurs MySQL.
Si vous souhaitez effectuer un amorçage manuel, vous pouvez également utiliser la fonction "Rechercher le nœud le plus avancé" et effectuer l'opération d'amorçage du cluster sur le nœud le plus avancé signalé par ClusterControl.
Configuration et journalisation centralisées
ClusterControl extrait un certain nombre de fichiers de configuration et de journalisation importants et les affiche dans une arborescence au sein de ClusterControl. Une vue centralisée de ces fichiers est essentielle pour comprendre et dépanner efficacement les configurations de bases de données distribuées. La manière traditionnelle de suivre/grepper ces fichiers est révolue depuis longtemps avec ClusterControl. La capture d'écran suivante montre le gestionnaire de fichiers de configuration de ClusterControl qui répertorie tous les fichiers de configuration associés à ce cluster dans une seule vue (avec coloration syntaxique, bien sûr) :
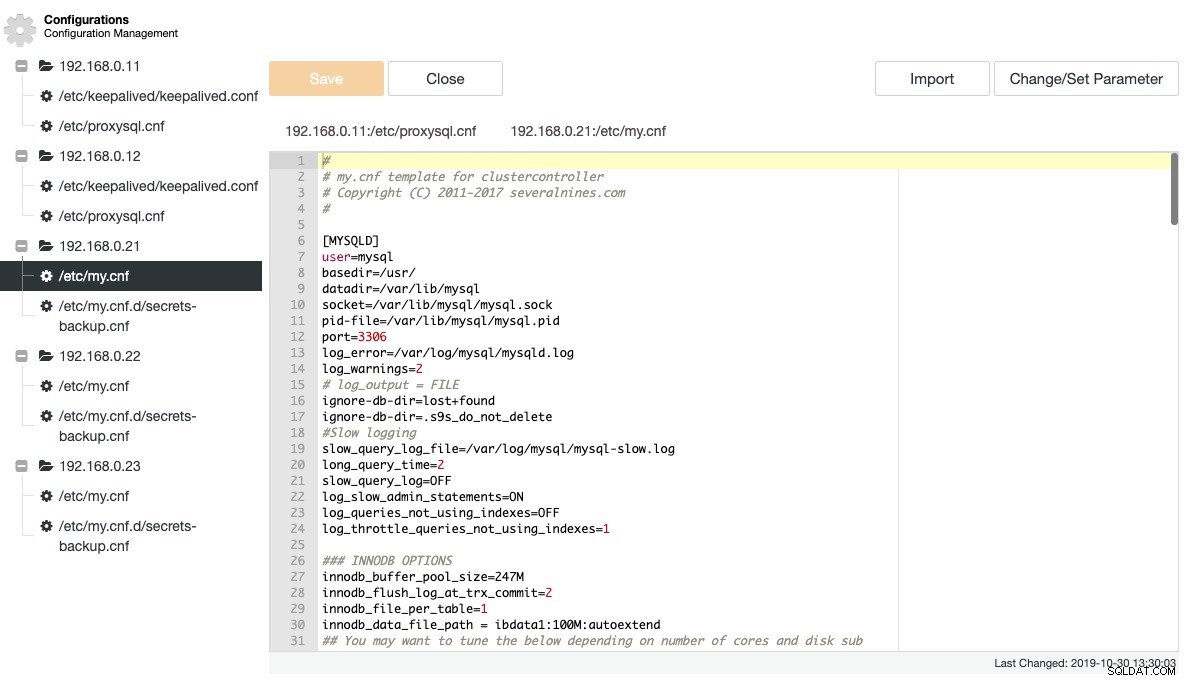
ClusterControl élimine la répétitivité lors de la modification d'une option de configuration d'un cluster de base de données. La modification d'une option de configuration sur plusieurs nœuds peut être effectuée via une seule interface et sera appliquée au nœud de la base de données en conséquence. Lorsque vous cliquez sur "Modifier/Définir le paramètre", vous pouvez sélectionner les instances de base de données que vous souhaitez modifier et spécifier le groupe de configuration, le paramètre et la valeur :
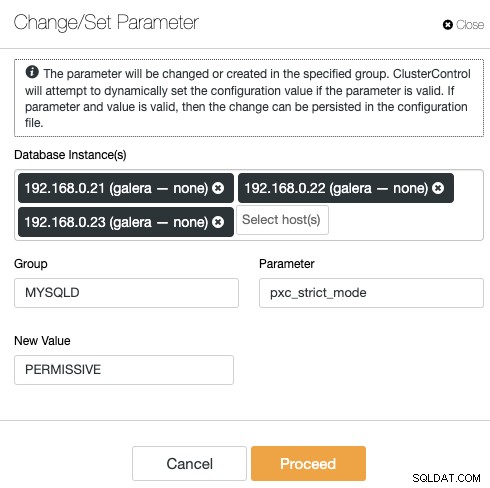
Vous pouvez ajouter un nouveau paramètre dans le fichier de configuration ou modifier un paramètre existant . Le paramètre sera appliqué à l'exécution des nœuds de base de données choisis et dans le fichier de configuration si l'option réussit le processus de validation des variables. Certaines variables peuvent nécessiter un redémarrage du serveur, qui sera alors conseillé par ClusterControl.
Clonage de cluster de base de données
Avec ClusterControl, vous pouvez rapidement cloner un cluster MySQL Galera existant afin d'avoir une copie exacte de l'ensemble de données sur l'autre cluster. ClusterControl effectue l'opération de clonage en ligne, sans aucun verrouillage ni interruption du cluster existant. C'est comme une opération de scale-out de cluster, sauf que les deux clusters sont indépendants l'un de l'autre une fois la synchronisation terminée. Le cluster cloné n'a pas nécessairement besoin d'avoir la même taille de cluster que celui existant. Nous pourrions commencer avec un « cluster à un nœud » et le mettre à l'échelle avec plus de nœuds de base de données à un stade ultérieur.
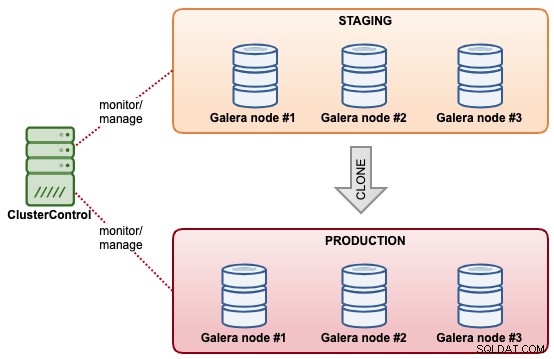
Une autre fonctionnalité similaire offerte par ClusterControl est "Créer un cluster à partir d'une sauvegarde". Cette fonctionnalité a été introduite dans ClusterControl 1.7.1, spécifiquement pour les clusters Galera Cluster et PostgreSQL où l'on peut créer un nouveau cluster à partir de la sauvegarde existante. Contrairement au clonage de cluster, cette opération n'apporte pas de charge supplémentaire au cluster source avec comme contrepartie que le cluster cloné ne sera pas dans le même état que le cluster source.
Nous avons couvert ce sujet en détail dans cet article de blog, Comment créer un clone de votre cluster de bases de données MySQL ou PostgreSQL.
Restaurer la sauvegarde physique
La plupart des outils de gestion de base de données permettent de sauvegarder une base de données, et seuls quelques-uns prennent en charge la restauration de la base de données de la sauvegarde logique uniquement. ClusterControl prend en charge la restauration complète non seulement pour les sauvegardes logiques, mais également pour les sauvegardes physiques, qu'il s'agisse d'une sauvegarde complète ou incrémentielle. La restauration d'une sauvegarde physique nécessite un certain nombre d'étapes critiques (en particulier les sauvegardes incrémentielles) qui impliquent essentiellement la préparation d'une sauvegarde, la copie des données préparées dans le répertoire de données, l'attribution des autorisations/propriétés correctes et le démarrage du nœud dans un ordre correct pour maintenir la cohérence des données à travers tous les membres du cluster. ClusterControl effectue toutes ces opérations automatiquement.
Vous pouvez également restaurer une sauvegarde physique sur un autre nœud qui ne fait pas partie d'un cluster. Dans ClusterControl, l'option pour cela s'appelle "Créer un cluster à partir d'une sauvegarde". Vous pouvez commencer avec un "cluster à un nœud" pour tester le processus de restauration sur un autre serveur ou pour copier votre cluster de base de données vers un autre emplacement.
ClusterControl prend également en charge la restauration d'une sauvegarde externe, une sauvegarde qui n'a pas été effectuée via ClusterControl. Il vous suffit de télécharger la sauvegarde sur le serveur ClusterControl et de spécifier le chemin physique vers le fichier de sauvegarde lors de la restauration. ClusterControl s'occupera du reste.
Réplication de cluster à cluster
Il s'agit d'une nouvelle fonctionnalité introduite dans ClusterControl 1.7.4. ClusterControl peut désormais gérer et surveiller la réplication cluster-cluster, ce qui étend essentiellement la réplication de base de données asynchrone entre plusieurs ensembles de clusters dans plusieurs emplacements géographiques. Un cluster peut être défini comme cluster maître (cluster actif qui traite les lectures/écritures) et le cluster esclave peut être défini comme cluster en lecture seule (cluster de secours qui peut également traiter les lectures). ClusterControl prend en charge la réplication asynchrone cluster-cluster pour Galera Cluster (le journal binaire doit être activé) ainsi que la réplication maître-esclave pour PostgreSQL Streaming Replication.
Pour créer un nouveau cluster les répliques d'un autre cluster, allez dans Actions de cluster -> Créer un cluster esclave :
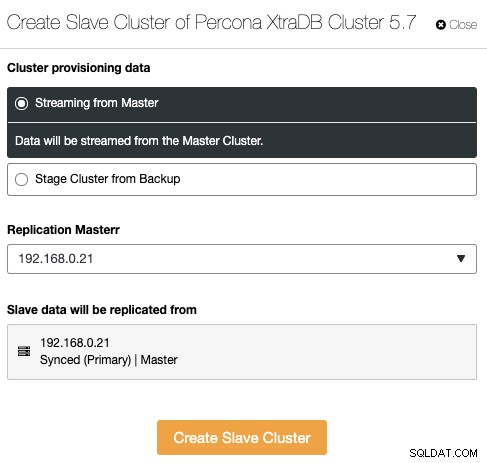
Le résultat du déploiement ci-dessus est présenté clairement sur le tableau de bord Database Cluster List :
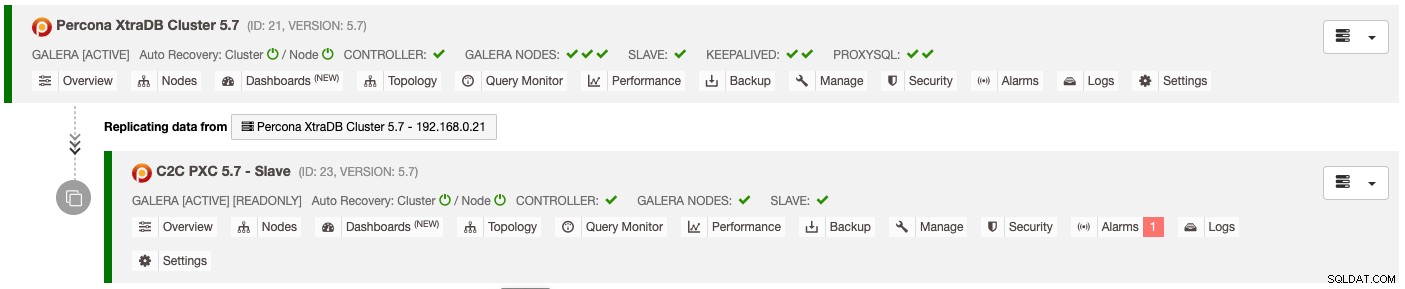
Le cluster esclave est automatiquement configuré en lecture seule, répliquant à partir du cluster principal et agissant comme un cluster de secours. Si une catastrophe frappe le cluster principal et que vous souhaitez activer le site secondaire, sélectionnez simplement le menu "Désactiver la lecture seule" disponible dans le menu déroulant Nœuds > Actions de nœud pour le promouvoir en tant que cluster actif.



