SCUMM (Severalnines ClusterControl Unified Monitoring &Management) est une solution basée sur des agents avec des agents installés sur les nœuds de la base de données. Il fournit un ensemble de tableaux de bord de surveillance, qui ont Prometheus comme magasin de données avec son langage de requête élastique et son modèle de données multidimensionnel. Prometheus récupère les données de métriques des exportateurs exécutés sur les hôtes de base de données.
L'architecture ClusterControl SCUMM a été introduite avec la version 1.7.0 étendant la fonctionnalité de surveillance pour MySQL, Galera Cluster, PostgreSQL et ProxySQL.
Le nouveau ClusterControl 1.7.1 ajoute une surveillance haute résolution pour les systèmes MongoDB.
 Liste du tableau de bord MongoDB de ClusterControl
Liste du tableau de bord MongoDB de ClusterControl Dans cet article, nous décrirons les deux principaux tableaux de bord pour les environnements MongoDB. MongoDB Server et MongoDB Replicaset.
Tableau de bord et liste des métriques
La liste des tableaux de bord et leurs métriques :
| Serveur MongoDB | |
|---|---|
| Name ReplSet Name Server Uptime OpsCounters Connections WT - Concurrent Tickets (Lecture) WT - Concurrent Tickets (Write) /> WT - Cache Verrouillage global Asserts |
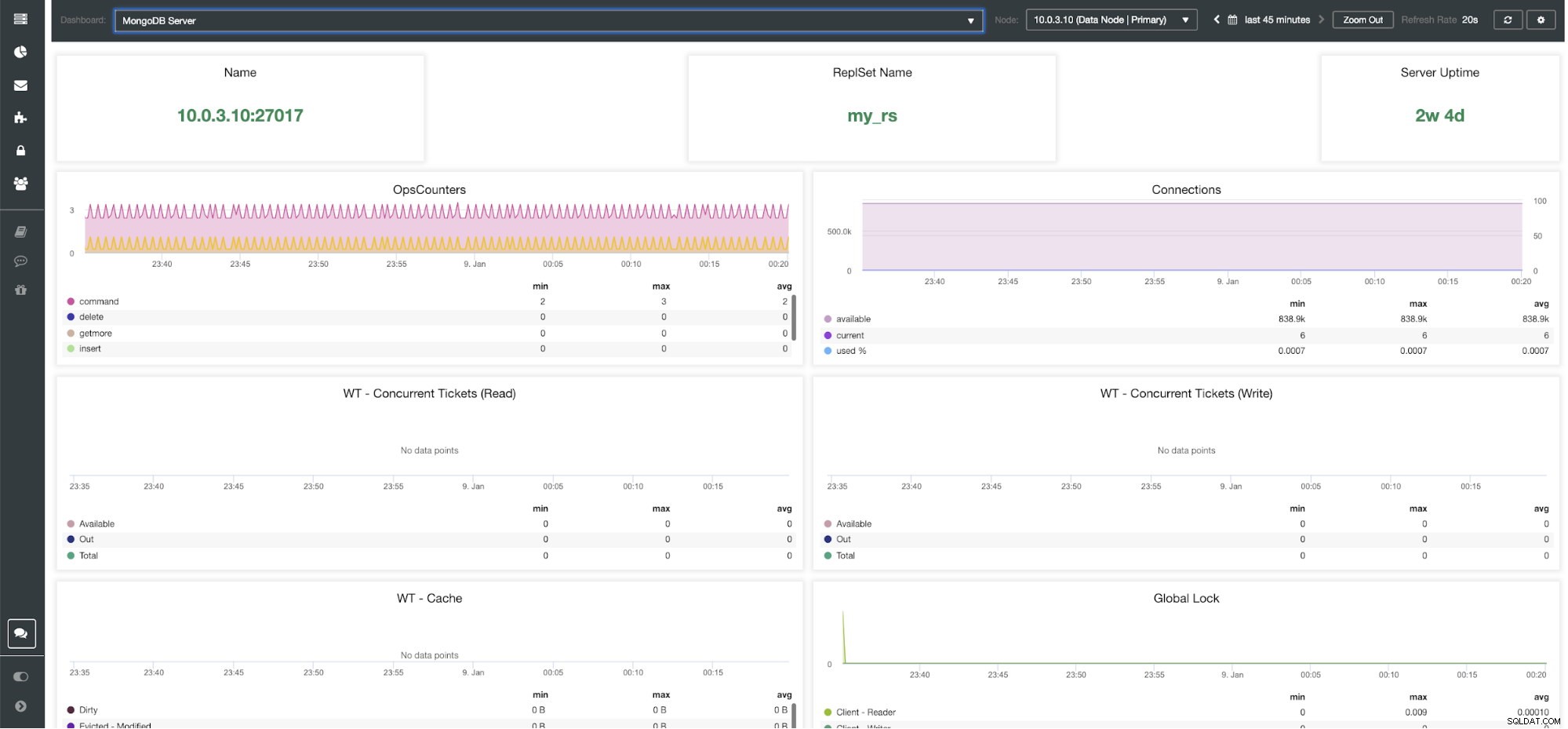 Tableau de bord du serveur MongoDB ClusterControl
Tableau de bord du serveur MongoDB ClusterControl| MongoDB ReplicaSet | |
|---|---|
| Taille du ReplSet Nom du ReplSet PRIMARY Version du serveur Ensembles de répliques et membres Fenêtre Oplog par ReplSet Marge de réplication Total de PRIMAIRE/SECONDAIRE en ligne par ReplSet Curseurs ouverts par ReplSet ReplSet - Curseurs expirés par jeu Délai de réplication maximum par ReplSet Taille d'oplog OpsCounters Ping Time to Replica Set Members from PRIMARY(s) |
 Tableau de bord ClusterControl MongoDB ReplicaSet
Tableau de bord ClusterControl MongoDB ReplicaSet Les systèmes de base de données dépendent fortement des ressources du système d'exploitation, vous pouvez donc également trouver deux tableaux de bord supplémentaires pour la vue d'ensemble du système et la vue d'ensemble du cluster de votre environnement MongoDB.
| Présentation du système | |
|---|---|
| Disponibilité du serveur Cœurs de processeur RAM totale Charge moyenne Utilisation du processeur Utilisation de la RAM Utilisation de l'espace disque Utilisation du réseau /> IOPS disque % d'utilisation d'E/S disque Débit disque |
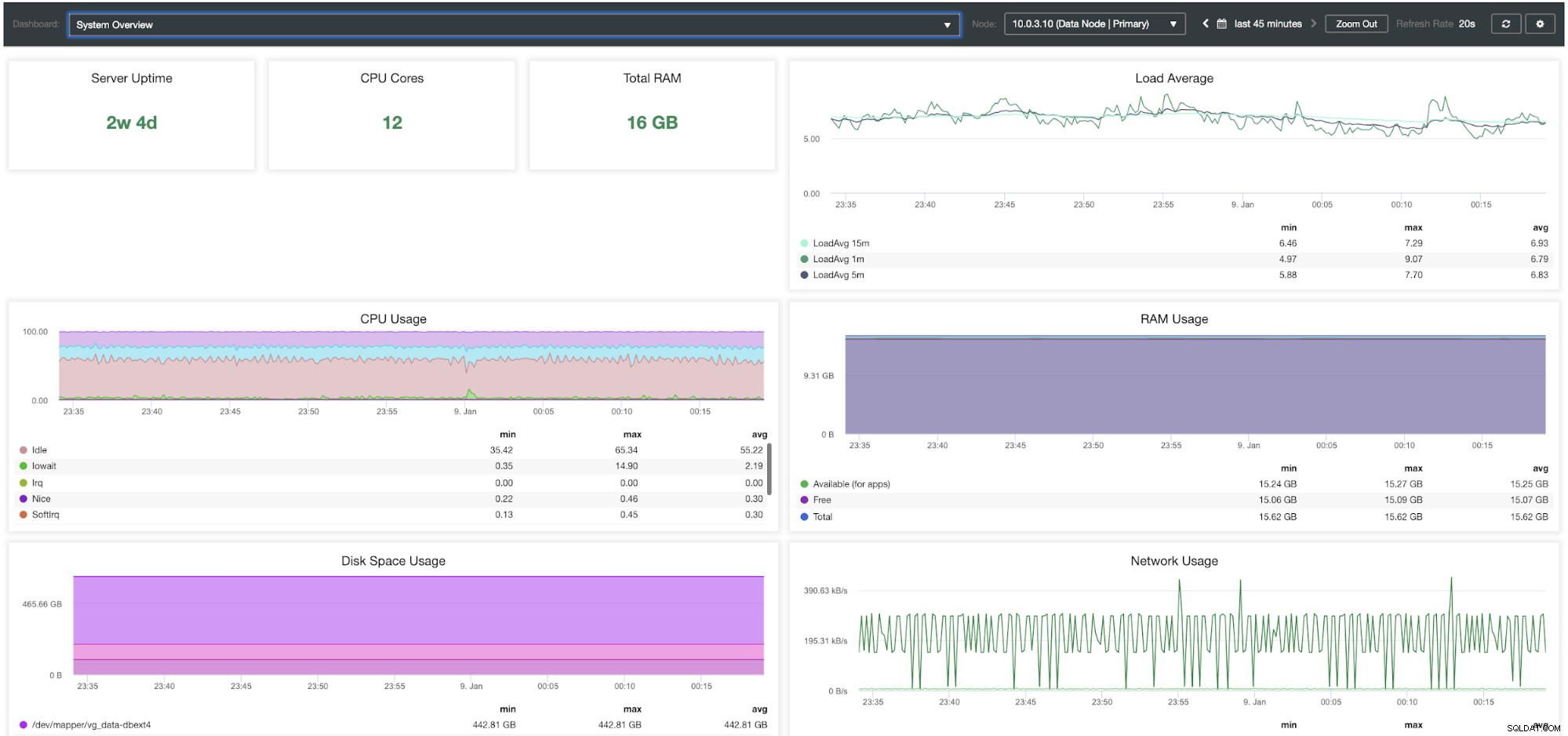 Tableau de bord de présentation du système de contrôle du cluster
Tableau de bord de présentation du système de contrôle du cluster| Présentation du cluster | |
|---|---|
| Charge moyenne 1 m Charge moyenne 5 m Charge moyenne 15 m Mémoire disponible pour les applications Réseau TX Réseau RX Lecture disque IOPS IOPS en écriture de disque IOPS en écriture de disque + lecture |
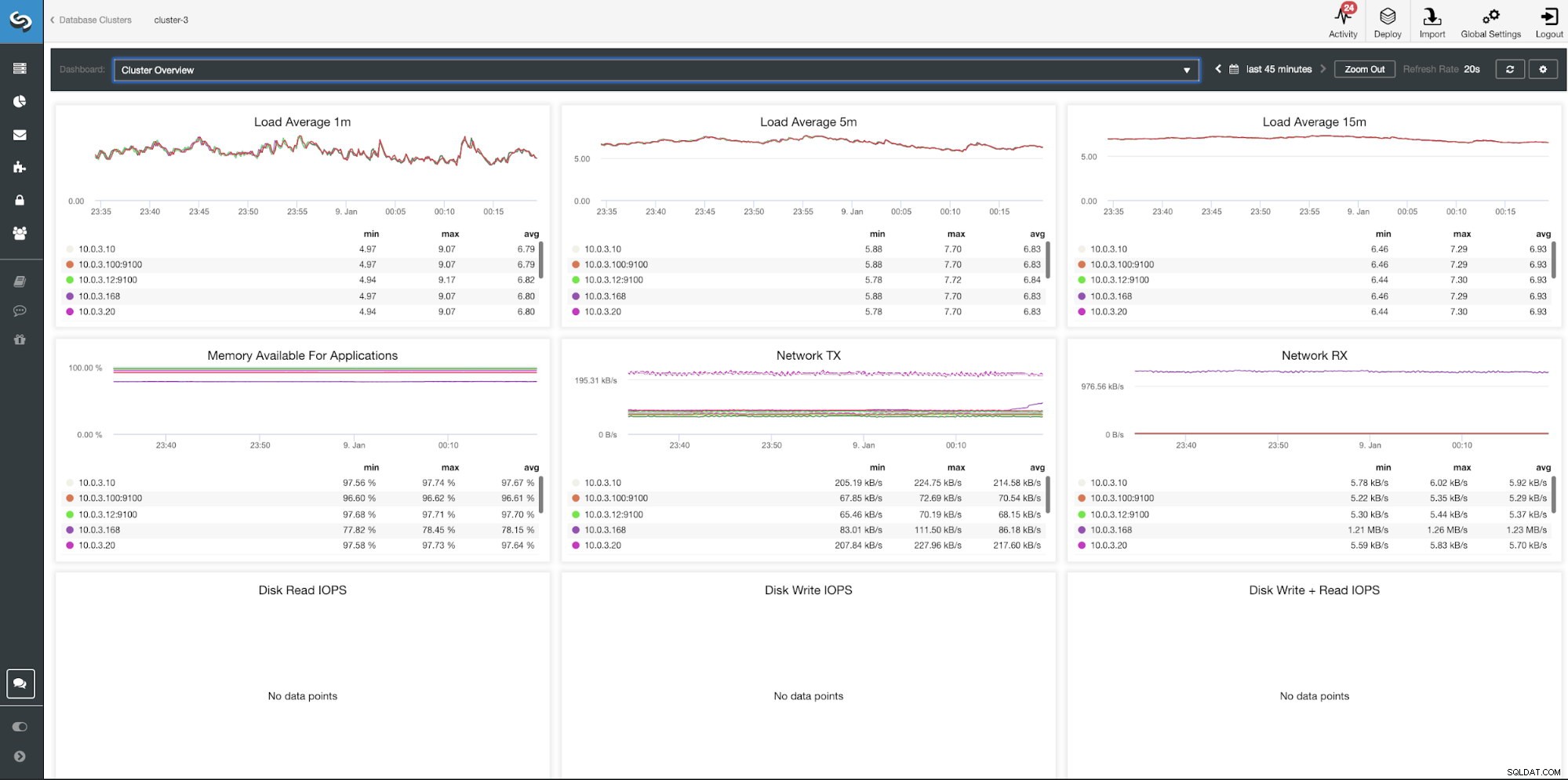 Tableau de bord de présentation du cluster ClusterControl
Tableau de bord de présentation du cluster ClusterControl Tableau de bord du serveur MongoDB
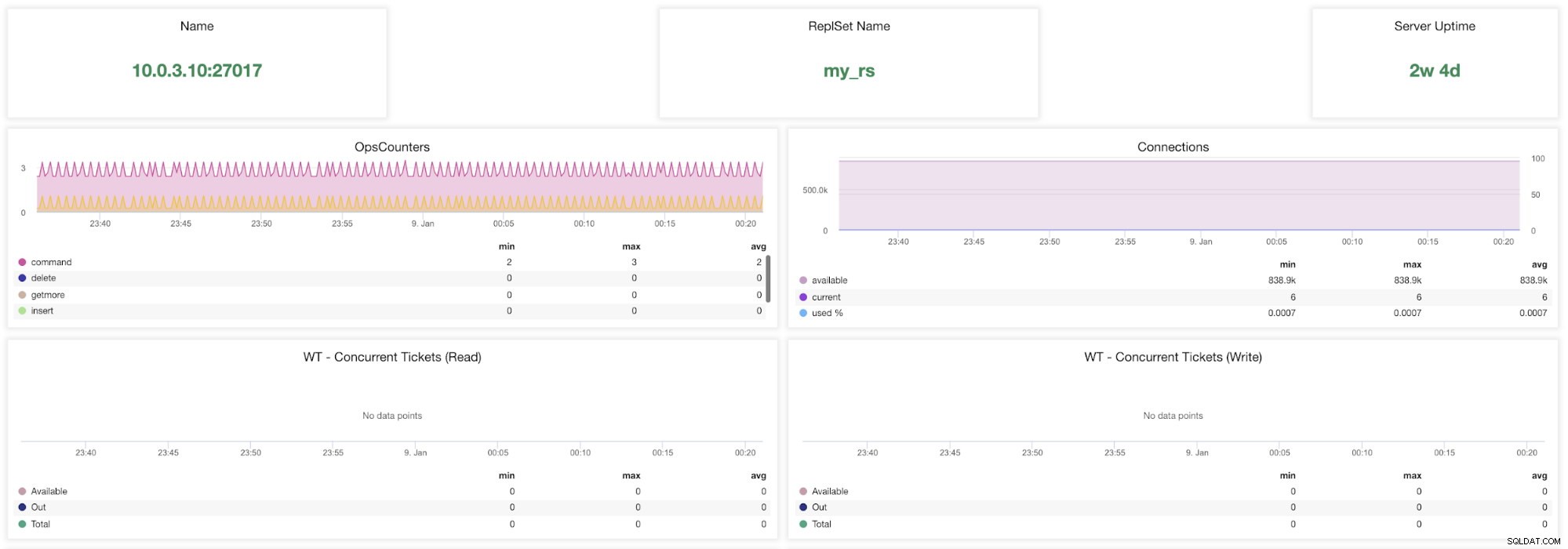 Métriques ClusterControl MongoDB
Métriques ClusterControl MongoDB Nom - L'adresse du serveur et le port.
Nom de l'ensemble de remplacement - Présente le nom du jeu de répliques auquel appartient le serveur.
Temps de disponibilité du serveur - Temps écoulé depuis le dernier redémarrage du serveur.
Ops Couteurs - Nombre de requêtes reçues pendant la période sélectionnée réparties par type d'opération. Ces décomptes incluent toutes les opérations reçues, y compris celles qui n'ont pas abouti.
Connexions - Ce graphique montre l'une des mesures les plus importantes à surveiller - le nombre de connexions reçues pendant la période sélectionnée, y compris les demandes infructueuses. Des charges de trafic anormales peuvent entraîner des problèmes de performances. Si MongoDB manque de connexions, il se peut qu'il ne soit pas en mesure de traiter les demandes entrantes en temps opportun.
WT - Billets simultanés (Lecture) / WT - Billets simultanés (Écriture) Ces deux graphiques montrent des tickets de lecture et d'écriture qui contrôlent la simultanéité dans WiredTiger (WT). Les tickets WT contrôlent le nombre d'opérations de lecture et d'écriture pouvant être exécutées simultanément sur le moteur de stockage. Lorsque les tickets de lecture et d'écriture disponibles tombent à zéro, le nombre d'opérations en cours d'exécution simultanées est égal aux valeurs de lecture/écriture configurées. Cela signifie que toute autre opération doit attendre que l'un des threads en cours d'exécution ait terminé son travail sur le moteur de stockage avant de s'exécuter.
 Métriques ClusterControl MongoDB
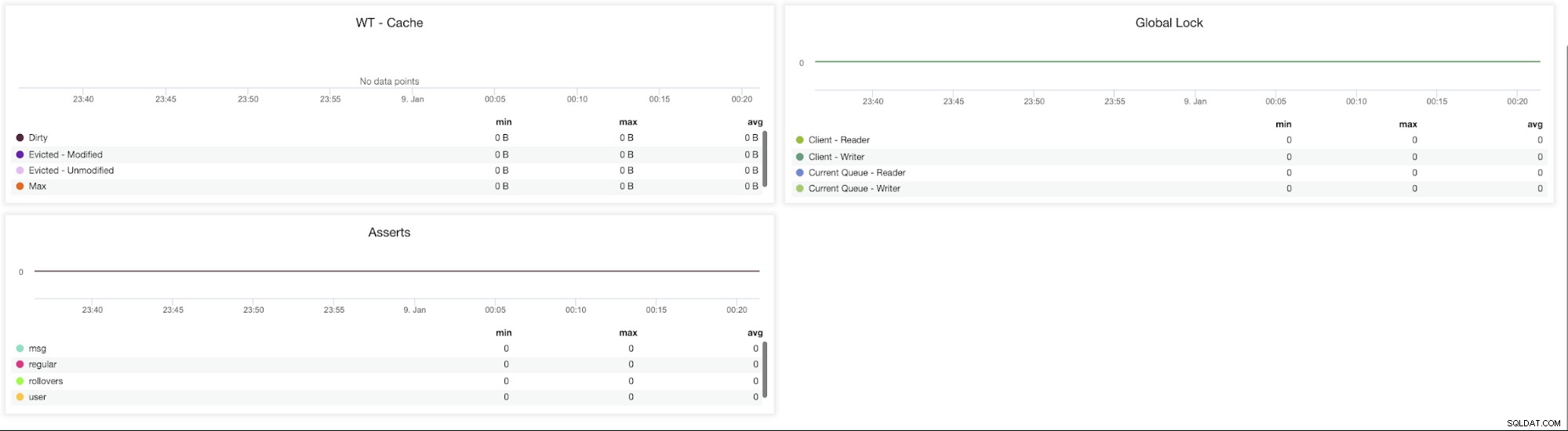
Métriques ClusterControl MongoDB WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - La taille du cache est le bouton le plus important pour WiredTiger. Par défaut, MongoDB 3.x réserve 50 % (60 % en 3.2) de la mémoire disponible pour son cache de données.
Verrouillage global (Client-Read, Client - Write, Current Queue - Reader, Current Queue - Writer) - Des modèles de conception de schéma médiocres ou des demandes de lecture et d'écriture intensives de la part de nombreux clients peuvent entraîner un verrouillage important. Lorsque cela se produit, il est nécessaire de maintenir la cohérence et d'éviter les conflits d'écriture.
Pour y parvenir, MongoDB utilise le verrouillage multi-granularité qui permet aux opérations de verrouillage de se produire à différents niveaux, tels qu'un niveau global, de base de données ou de collection. .
Affirmations (msg, regular, rollovers, user) - Ce graphique montre le nombre d'affirmations qui sont déclenchées chaque seconde. Les valeurs élevées et les écarts par rapport aux tendances doivent être examinés.
Tableau de bord MongoDB ReplicaSet
Les métriques affichées dans ce tableau de bord n'ont d'importance que si vous utilisez un jeu de réplicas.
 Métriques ClusterControl MongoDB ReplicaSet
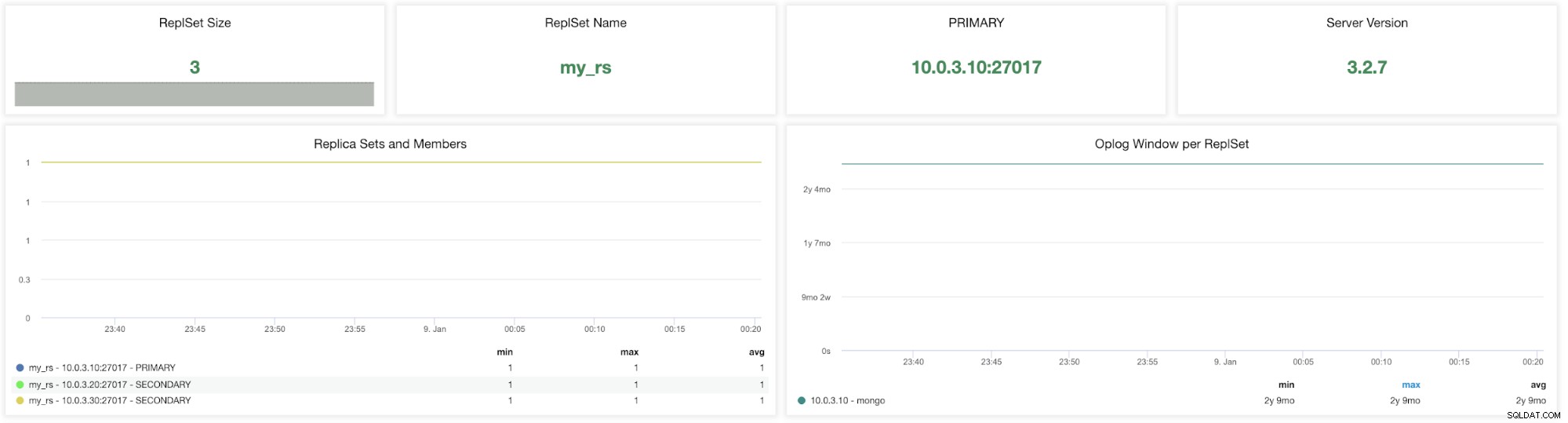
Métriques ClusterControl MongoDB ReplicaSet Taille de l'ensemble de réplicas - Le nombre de membres dans le jeu de répliques. Le déploiement d'un jeu de répliques standard pour le système de production est un jeu de répliques à trois membres. De manière générale, il est recommandé qu'un jeu de réplicas ait un nombre impair de membres votants. La tolérance aux pannes d'un jeu de réplicas correspond au nombre de membres qui peuvent devenir indisponibles tout en laissant suffisamment de membres dans le jeu pour élire un primaire. La tolérance aux pannes pour trois membres est de un, pour cinq, elle est de deux, etc.
Nom de l'ensemble de remplacement - C'est le nom attribué dans le fichier de configuration de MongoDB. Le nom fait référence à la valeur de /etc/mongod.conf replSet.
PRIMAIRE - Le nœud principal reçoit toutes les opérations d'écriture et enregistre toutes les autres modifications apportées à son ensemble de données dans son journal des opérations. La valeur sert à identifier l'adresse IP et le port de votre nœud principal dans le cluster d'ensemble de réplicas MongoDB.
Version serveur - Identifiez la version du serveur. ClusterControl version 1.7.1 prend en charge les versions 3.2/3.4/3.6/4.0 de MongoDB.
Ensembles de répliques et membres (min, max, moy) - Ce graphique peut vous aider à identifier les membres actifs sur la période. Vous pouvez suivre les nombres minimum, maximum et moyen de nœuds primaires et secondaires et comment ces nombres ont changé au fil du temps. Tout écart peut affecter la tolérance aux pannes et la disponibilité du cluster.
Fenêtre Oplog par ReplSet - La fenêtre de réplication est une métrique essentielle à surveiller. L'oplog MongoDB est une collection unique qui a été limitée à une taille (prédéfinie). Il peut être décrit comme la différence entre le premier et le dernier horodatage dans oplog.rs. Il s'agit de la durée pendant laquelle un secondaire peut être hors ligne avant qu'une synchronisation initiale ne soit nécessaire pour synchroniser l'instance. Ces métriques vous informent du temps qu'il vous reste avant que notre prochaine transaction ne soit supprimée de l'oplog.
 Métriques ClusterControl MongoDB ReplicaSet
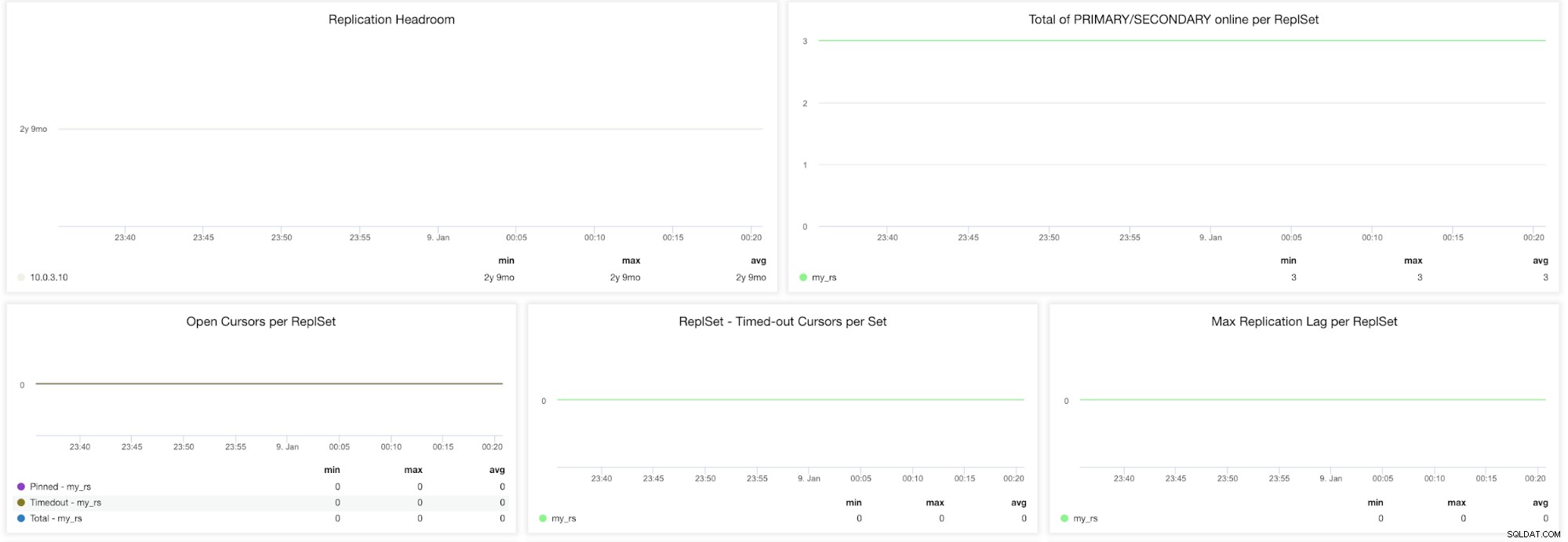
Métriques ClusterControl MongoDB ReplicaSet Marge de réplication - Ce graphique présente la différence entre la fenêtre d'oplog du primaire et le décalage de réplication des nœuds secondaires. L'oplog MongoDB est limité en taille et si le nœud est trop en retard, il ne pourra pas rattraper son retard. Si cela se produit, une synchronisation complète sera émise et il s'agit d'une opération coûteuse qui doit être évitée à tout moment.
Total de PRIMAIRE/SECONDAIRE en ligne par ReplSet - Nombre total de nœuds de cluster sur la période.
Ouvrir les curseurs par ReplSet (Épinglé, Délai d'expiration, Total) - Une requête de lecture est accompagnée d'un curseur qui est un pointeur vers l'ensemble de données du résultat. Il restera ouvert sur le serveur et consommera donc de la mémoire à moins qu'il ne soit terminé par le paramètre MongoDB par défaut. Vous devez identifier les curseurs non actifs et les couper pour économiser de la mémoire.
ReplSet - Timeout Cursors per SetsMax Replication Lag per ReplSet - Il est très important de garder un œil sur le décalage de réplication si vous étendez les lectures en ajoutant plus de secondaires. MongoDB n'utilisera ces secondaires que s'ils ne sont pas trop à la traîne. Si le secondaire présente un décalage de réplication, vous risquez de diffuser des données obsolètes qui ont déjà été écrasées sur le principal.
OplogSize - Certaines charges de travail peuvent nécessiter une plus grande taille d'oplog. Les mises à jour de plusieurs documents à la fois, les suppressions équivalent à la même quantité de données qu'une insertion ou le nombre important de mises à jour sur place.
OpsConters - Ce graphique montre le nombre d'exécutions de requêtes.
Délai de ping pour répliquer le membre de l'ensemble à partir du primaire - Cela vous permet de découvrir les membres du jeu de réplicas qui sont en panne ou inaccessibles depuis le nœud principal.
Remarques de clôture
La nouvelle fonctionnalité de tableau de bord MongoDB de ClusterControl 1.7.1 est disponible gratuitement dans l'édition communautaire. Les équipes d'exploitation de la base de données peuvent en tirer profit en utilisant les graphiques haute résolution, en particulier lors de l'exécution de leurs routines quotidiennes telles que les analyses des causes profondes et la planification des capacités.
Il suffit d'un clic pour déployer de nouveaux agents de surveillance. ClusterControl installe les agents Prometheus, configure les métriques et maintient l'accès à la configuration des exportateurs Prometheus via son interface graphique, afin que vous puissiez mieux gérer la configuration des paramètres comme les indicateurs de collecteur pour les exportateurs (Prometheus).
En surveillant de manière adéquate le nombre de requêtes de lecture et d'écriture, vous pouvez éviter la surcharge des ressources, trouver rapidement l'origine des surcharges potentielles et savoir quand effectuer une mise à l'échelle.



