Envie de tout savoir sur le cluster Hadoop ?
Hadoop est un cadre logiciel permettant d'analyser et de stocker de grandes quantités de données sur des clusters de matériel de base. Dans cet article, nous allons étudier un cluster Hadoop.
Commençons d'abord par une introduction à Cluster.
Qu'est-ce qu'un cluster ?
Un cluster est un ensemble de nœuds. Les nœuds ne sont rien d'autre qu'un point de connexion/d'intersection au sein d'un réseau.
Un cluster d'ordinateurs est un ensemble d'ordinateurs connectés à un réseau, capables de communiquer entre eux et fonctionnant comme un système unique.
Qu'est-ce qu'un cluster Hadoop ?
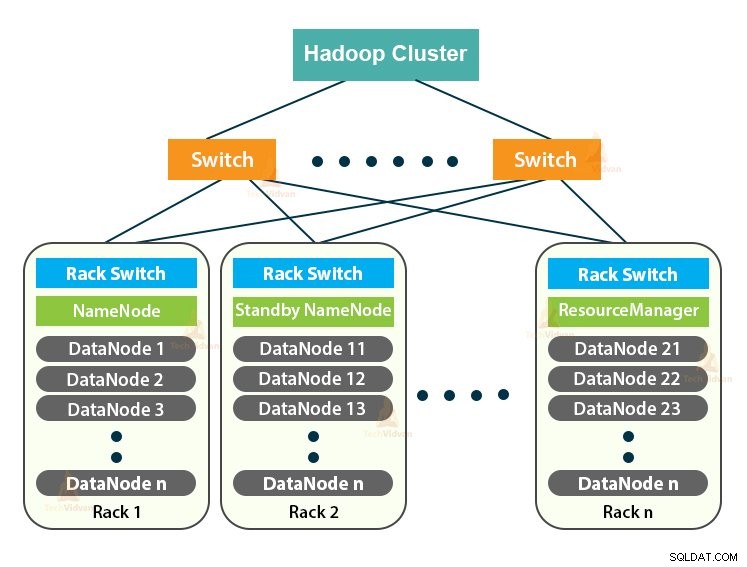
Hadoop Cluster est juste un cluster informatique utilisé pour gérer une grande quantité de données de manière distribuée.
Il s'agit d'un cluster informatique conçu pour stocker et analyser d'énormes quantités de données non structurées ou structurées dans un environnement informatique distribué.
Les clusters Hadoop sont également connus sous le nom de systèmes sans partage car rien n'est partagé entre les nœuds du cluster, à l'exception de la bande passante du réseau. Cela diminue la latence de traitement.
Ainsi, lorsqu'il est nécessaire de traiter des requêtes sur une énorme quantité de données, la latence à l'échelle du cluster est minimisée.
Étudions maintenant l'architecture du cluster Hadoop.
Architecture du cluster Hadoop
Le cluster Hadoop suit une architecture maître-esclave. Il se compose du nœud maître, des nœuds esclaves et du nœud client.
1. Maîtrise en cluster Hadoop
Le maître dans le cluster Hadoop est une machine haute puissance avec une configuration élevée de mémoire et de processeur. Les deux démons que sont NameNode et ResourceManager s'exécutent sur le nœud maître.
un. Fonctions de NameNode
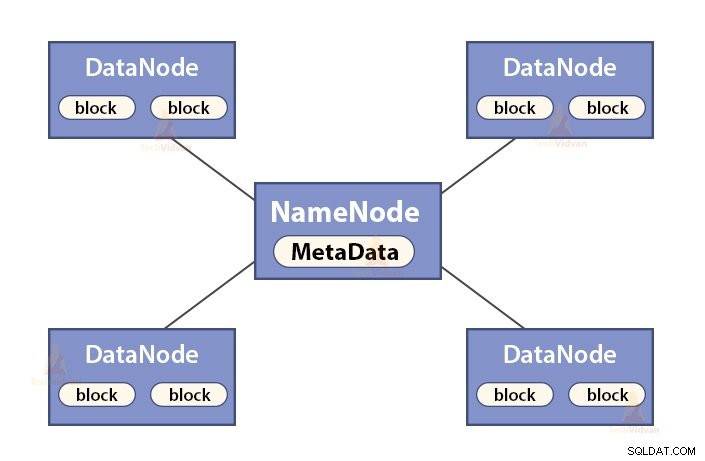
NameNode est un nœud maître dans Hadoop HDFS . NameNode gère l'espace de noms du système de fichiers. Il stocke les métadonnées du système de fichiers dans la mémoire pour une récupération rapide. Par conséquent, il doit être configuré sur des machines haut de gamme.
Les fonctions de NameNode sont :
- Gère l'espace de noms du système de fichiers
- Stocke des métadonnées sur les blocs d'un fichier, l'emplacement des blocs, les autorisations, etc.
- Il exécute les opérations d'espace de noms du système de fichiers comme l'ouverture, la fermeture, le renommage des fichiers et des répertoires, etc.
- Il maintient et gère le DataNode.
b. Fonctions du gestionnaire de ressources
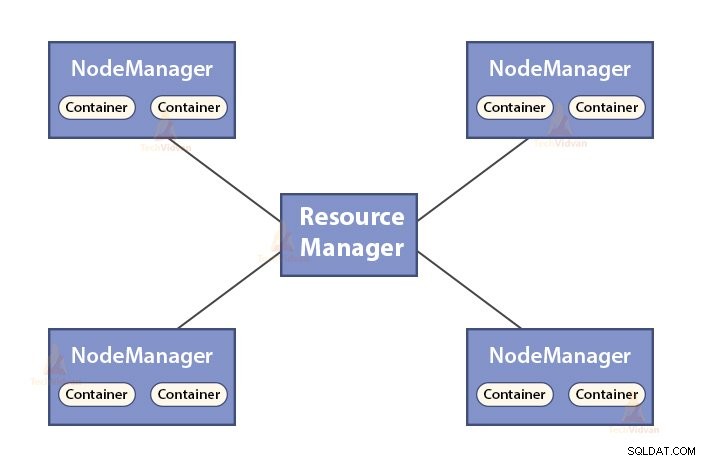
- ResourceManager est le démon maître de YARN.
- Le ResourceManager arbitre les ressources entre toutes les applications du système.
- Il garde une trace des nœuds actifs et morts dans le cluster.
2. Esclaves dans le cluster Hadoop
Les esclaves du cluster Hadoop sont du matériel de base peu coûteux. Les deux démons que sont les DataNodes et les NodeManagers YARN s'exécutent sur les nœuds esclaves.
un. Fonctions des DataNodes
- DataNodes stocke les données commerciales réelles. Il stocke les blocs d'un fichier.
- Il effectue la création, la suppression et la réplication de blocs en fonction des instructions de NameNode.
- DataNode est responsable des opérations de lecture/écriture du client.
b. Fonctions de NodeManager
- NodeManager est le démon esclave de YARN.
- Il est responsable des conteneurs, surveille leur utilisation des ressources (telles que le processeur, le disque, la mémoire, le réseau) et en fait rapport au ResourceManager.
- Le NodeManager vérifie également la santé du nœud sur lequel il s'exécute.
3. Nœud client dans le cluster Hadoop
Les nœuds clients dans Hadoop ne sont ni des nœuds maîtres ni des nœuds esclaves. Ils ont Hadoop installé dessus avec tous les paramètres du cluster.
Fonctions des nœuds clients
- Les nœuds clients chargent les données dans le cluster Hadoop.
- Il soumet des tâches MapReduce, décrivant comment ces données doivent être traitées.
- Récupérer les résultats de la tâche une fois le traitement terminé.
Nous pouvons faire évoluer le cluster Hadoop en ajoutant plus de nœuds. Cela rend Hadoop linéairement évolutif . Avec chaque ajout de nœud, nous obtenons une augmentation correspondante du débit. Si nous avons 'n' nœuds, ajouter 1 nœud donne (1/n) une puissance de calcul supplémentaire.
Cluster Hadoop à nœud unique VS Cluster Hadoop à nœuds multiples
1. Cluster Hadoop à nœud unique
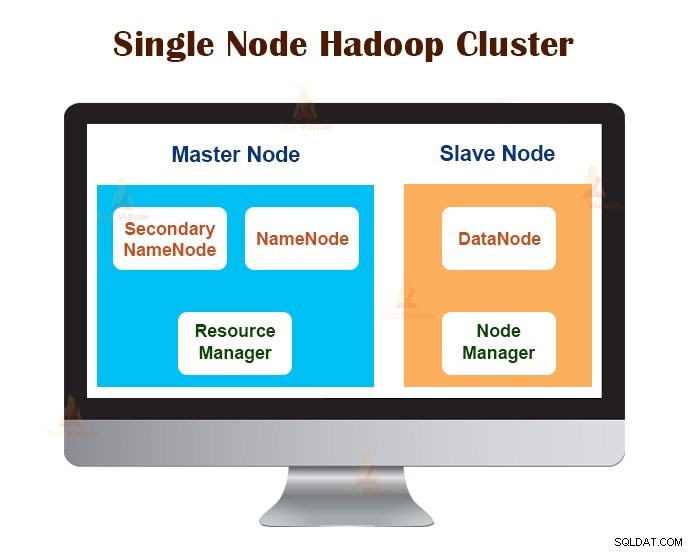
Le cluster Hadoop à nœud unique est déployé sur une seule machine. Tous les démons comme NameNode, DataNode, ResourceManager, NodeManager s'exécutent sur la même machine/hôte.
Dans une configuration de cluster à nœud unique, tout s'exécute sur une seule instance JVM. L'utilisateur Hadoop n'a pas eu à définir de paramètres de configuration, à l'exception de la définition de la variable JAVA_HOME.
Le facteur de réplication par défaut pour un cluster Hadoop à nœud unique est toujours 1.
2. Cluster Hadoop multinœud
Le cluster Hadoop multi-nœuds est déployé sur plusieurs machines. Tous les démons du cluster Hadoop multi-nœuds sont opérationnels et exécutés sur différentes machines/hôtes.
Un cluster Hadoop multi-nœuds suit une architecture maître-esclave. Les démons Namenode et ResourceManager s'exécutent sur les nœuds maîtres, qui sont des ordinateurs haut de gamme.
Les démons DataNodes et NodeManagers s'exécutent sur les nœuds esclaves (nœuds de travail), qui sont du matériel de base peu coûteux.
Dans le cluster Hadoop multi-nœuds, les machines esclaves peuvent être présentes à n'importe quel emplacement, quel que soit l'emplacement de l'emplacement physique du serveur maître.
Protocoles de communication utilisés dans le cluster Hadoop
Les protocoles de communication HDFS sont superposés au protocole TCP/IP. Un client établit une connexion avec le NameNode via le port TCP configurable sur la machine NameNode.
Le cluster Hadoop établit une connexion avec le client via ClientProtocol. De plus, le DataNode communique avec le NameNode en utilisant le protocole DataNode.
L'abstraction d'appel de procédure distante (RPC) enveloppe le protocole client et le protocole DataNode. De par sa conception, NameNode n'initie aucun RPC. Il ne répond qu'aux requêtes RPC émises par les clients ou les DataNodes.
Meilleures pratiques pour créer un cluster Hadoop
Les performances d'un cluster Hadoop dépendent de divers facteurs basés sur les ressources matérielles bien dimensionnées qui utilisent le processeur, la mémoire, la bande passante réseau, le disque dur et d'autres couches logicielles bien configurées.
Construire un cluster Hadoop est un travail non trivial. Cela nécessite la prise en compte de divers facteurs tels que le choix du bon matériel, le dimensionnement des clusters Hadoop et la configuration du cluster Hadoop.
Voyons maintenant chacun en détail.
1. Choisir le bon matériel pour le cluster Hadoop
De nombreuses organisations, lors de la configuration de l'infrastructure Hadoop, se trouvent dans une situation difficile car elles ne sont pas conscientes du type de machines qu'elles doivent acheter pour configurer un environnement Hadoop optimisé et de la configuration idéale qu'elles doivent utiliser.
Pour choisir le bon matériel pour le cluster Hadoop, il faut tenir compte des points suivants :
- Le volume de données que le cluster va gérer.
- Le type de charges de travail que le cluster traitera (lié au processeur, lié aux E/S).
- Méthodologie de stockage des données, comme les conteneurs de données, les techniques de compression des données utilisées, le cas échéant.
- Une politique de conservation des données, c'est-à-dire la durée pendant laquelle nous souhaitons conserver les données avant de les supprimer.
2. Dimensionnement du cluster Hadoop
Pour déterminer la taille du cluster Hadoop, le volume de données que les utilisateurs Hadoop traiteront sur le cluster Hadoop doit être un facteur clé.
En connaissant le volume de données à traiter, aide à décider combien de nœuds seront nécessaires pour traiter efficacement les données et la capacité de mémoire requise pour chaque nœud. Il doit y avoir un équilibre entre les performances et le coût du matériel approuvé.
3. Configuration du cluster Hadoop
Trouver la configuration idéale pour le cluster Hadoop n'est pas une tâche facile. Le framework Hadoop doit être adapté au cluster qu'il exécute et également au travail.
La meilleure façon de décider de la configuration idéale pour le cluster Hadoop est d'exécuter les tâches Hadoop avec la configuration par défaut disponible afin d'obtenir une ligne de base. Après cela, nous pouvons analyser les fichiers journaux de l'historique des travaux pour voir s'il y a une faiblesse des ressources ou si le temps nécessaire pour exécuter les travaux est plus élevé que prévu.
Si tel est le cas, modifiez la configuration. La répétition du même processus peut ajuster la configuration du cluster Hadoop qui correspond le mieux aux besoins de l'entreprise.
Les performances du cluster Hadoop dépendent fortement des ressources allouées aux démons. Pour les contextes de données petits à moyens, Hadoop réserve un cœur de processeur sur chaque DataNode, tandis que, pour les longs ensembles de données, il alloue 2 cœurs de processeur sur chaque DataNode pour les démons HDFS et MapReduce.
Gestion des clusters Hadoop
Lors du déploiement du cluster Hadoop en production, il est évident qu'il doit s'adapter à toutes les dimensions que sont le volume, la variété et la vitesse.
Diverses caractéristiques qu'il devrait posséder pour être prêt pour la production sont - disponibilité 24 heures sur 24, robustesse, gérabilité et performances. La gestion du cluster Hadoop est la principale facette de l'initiative Big Data.
Le meilleur outil pour la gestion du cluster Hadoop devrait avoir les fonctionnalités suivantes :-
- Il doit garantir une haute disponibilité 24h/24 et 7j/7, le provisionnement des ressources, une sécurité diversifiée, la gestion de la charge de travail, la surveillance de l'état et l'optimisation des performances. En outre, il doit assurer la planification des tâches, la gestion des règles, la sauvegarde et la restauration sur un ou plusieurs nœuds.
- Mettre en œuvre la haute disponibilité redondante du NameNode HDFS avec équilibrage de charge, secours automatiques, resynchronisation et basculement automatique.
- Appliquer des contrôles basés sur des règles qui empêchent toute application de s'accaparer une part disproportionnée des ressources sur un cluster Hadoop déjà saturé
- Effectuer des tests de régression pour gérer le déploiement de toutes les couches logicielles sur les clusters Hadoop. Cela permet de s'assurer que les tâches ou les données ne se bloquent pas ou ne rencontrent pas de goulots d'étranglement dans les opérations quotidiennes.
Avantages du cluster Hadoop
Les différents avantages apportés par le cluster Hadoop sont :
1. Évolutif
Les clusters Hadoop sont évolutifs. Nous pouvons ajouter n'importe quel nombre de nœuds au cluster Hadoop sans aucun temps d'arrêt et sans aucun effort supplémentaire. Avec chaque ajout de nœud, nous obtenons une augmentation correspondante du débit.
2. Robustesse
Le cluster Hadoop est surtout connu pour son stockage fiable. Il peut stocker des données de manière fiable, même dans des cas tels que l'échec de DataNode, l'échec de NameNode et la partition réseau. Le DataNode envoie périodiquement un signal de pulsation au NameNode.
Dans la partition réseau, un ensemble de DataNodes se détache du NameNode en raison duquel NameNode ne reçoit aucun battement de cœur de ces DataNodes. NameNode considère alors ces DataNodes comme morts et ne leur transmet aucune requête I/O.
De plus, le facteur de réplication des blocs stockés dans ces DataNodes tombe en dessous de leur valeur spécifiée. En conséquence, NameNode lance alors la réplication de ces blocs et récupère de l'échec.
3. Rééquilibrage des clusters
L'architecture Hadoop HDFS effectue automatiquement le rééquilibrage du cluster. Si l'espace libre dans le DataNode tombe en dessous du seuil, l'architecture HDFS déplace automatiquement certaines données vers un autre DataNode où suffisamment d'espace est disponible.
4. Rentable
La configuration du cluster Hadoop est rentable car il comprend du matériel de base peu coûteux. Toute organisation peut facilement configurer un cluster Hadoop puissant sans dépenser beaucoup d'argent en matériel de serveur coûteux.
De plus, les clusters Hadoop avec sa topologie de stockage distribué surmontent les limites du système traditionnel. Le stockage limité peut être étendu simplement en ajoutant des unités de stockage supplémentaires peu coûteuses au système.
5. Souple
Les clusters Hadoop sont très flexibles car ils peuvent traiter des données de tout type, structurées, semi-structurées ou non structurées et de toutes tailles allant de gigaoctets à pétaoctets.
6. Traitement rapide
Dans Hadoop Cluster, les données peuvent être traitées en parallèle dans un environnement distribué. Cela fournit des capacités de traitement de données rapides à Hadoop. Les clusters Hadoop peuvent traiter des téraoctets ou des pétaoctets de données en une fraction de seconde.
7. Intégrité des données
Pour vérifier toute corruption dans les blocs de données due à un logiciel bogué, à des défauts dans un périphérique de stockage, etc., le cluster Hadoop implémente une somme de contrôle sur chaque bloc du fichier. S'il trouve un bloc corrompu, il le recherche dans un autre DataNode contenant la réplique du même bloc. Ainsi, le cluster Hadoop maintient l'intégrité des données.
Résumé
Après avoir lu cet article, nous pouvons dire que le cluster Hadoop est un cluster de calcul spécial conçu pour analyser et stocker des mégadonnées. Hadoop Cluster suit l'architecture maître-esclave.
Le nœud maître est la machine informatique haut de gamme et les nœuds esclaves sont des machines avec une configuration CPU et mémoire normale. Nous avons également vu que le cluster Hadoop peut être configuré sur une seule machine appelée cluster Hadoop à nœud unique ou sur plusieurs machines appelées cluster Hadoop multi-nœud.
Dans cet article, nous avions également couvert les meilleures pratiques à suivre lors de la construction d'un cluster Hadoop. Nous avions également vu de nombreux avantages du cluster Hadoop, notamment l'évolutivité, la flexibilité, la rentabilité, etc.



